来升强/谢邦昌/朱建平
【内容提要】
作为一种近似处理的工具,粗集主要用于不确定情况下的决策分析,并且不需要任何事先的数据假定。但当前的主流粗集分类方法仍然需要先经过离散化的步骤,这就损失了数值型变量提供的高质量信息。本文对隶属函数重新加以概率定义,并提出了一种基于Bayes概率边界域的粗集分类技术,比较好地解决了当前粗集方法所面临的数值型属性分类的不适应、分类规则不完备等一系列问题。
【关 键 词】可变精度粗糙集/Bayes边界域/高频数据
一、引言
粗集理论的基本观点是利用上近似、下近似以及两者的差集非常明确地刻画了任何个体的类属[1]。在分类能力不变的前提下,通过知识约简导出分类规则,并用于数据压缩,规则提取以及分类等任务。粗集中的主要研究方向集中在理论扩展、数学性质分析以及算法设计等方面[2-4]。但粗集也面临两个主要的问题:其一,粗集的基础是等价关系,但实际中这一条件比较强,并且考虑到噪声和观测误差,容易出现泛化能力不足的现象[5]。另外,粗集不能直接处理定量数据,必须先对连续数据进行离散化,不可避免地损失了一些分类信息。Ziarko(1993)提出的可变精度粗集(Variable Precision Rough Set)模型比较好地解决了第一个方面的问题[6]。可变精度粗集模型把粗集上下近似域的绝对条件变为相对条件,也就是根据其所考察的属性集的重叠区域的比例来判断近似程度。在属性集不变的条件下,β越大,其边界越清晰,当β=1时,就还原为普通的粗集模型。因为采用了概率公式来表达近似程度,所以也称为β近似。随后,Ziarko又进一步提出基于样本的β近似等价关系,从大数定律的角度进一步探讨了利用β近似所得到的规则的完备性、可扩展性和支持度[8]。
可变精度粗集也存在一些不妥之处。由于β近似建立在部分属性的等价关系上,组成这些等价关系的属性集所构成的核仅仅是全部属性集的一个子集,根据粗集有关定义,增加一个或多个属性后所形成的增广核,其分类精度至少不应降低。但有研究表明会出现某些增广核的分类准确度反而下降的情况[9],这就直接违背了粗集中约简与核的定义。其次,由于可变精度粗集方法是将落入同一等价类区域中的个体看做是来自同一总体中的样本,直接计算其频率作为近似程度指标。这从统计上来看,并不总是适当的,至少对于有限个体的重复观测情形来说,这个假定完全忽略了个体内在的异质特征。至于改进后的样本β近似等价类划分方法[8],则把论域本身看做样本,认为从样本论域中得到的等价关系只是总体论域的一个子集,这就允许在样本论域扩大时出现新的等价关系,比较好地解释了等价关系的不完备性。但这种论域随机化处理并没有解决在实际问题中可变精度粗集泛化能力仍然不足的现象。再次,研究者很少关注β值的选择,一般假定是经验判断值或事先给定的,在决策过程作为外生变量处理。而在实际决策过程中,β初始值选择十分关键,并且伴随着决策过程的持续,β也应做调整。最后,对于数值型变量的分类,可变精度粗集方法仍然显得力不从心。虽然可变精度粗集已经对隶属函数进行了一定程度的“柔化”,但其隶属函数仍然是由定性数据的隶属关系导出,放弃了数值型数据所提供的高质量分类信息。
本研究针对这些问题,从统计角度提出了一种基于Bayes概率边界域的粗集分类方法。此方法能够直接处理数值型数据,可以充分利用数值型变量的高质量信息。其主要步骤为:首先,通过历史数据获取全属性域的经验分布;其次,利用Bayes后验分布计算各个等价类的隶属概率,并用概率阈值筛选分类规则;最后,通过分类规则的预测准确率,得到最优的等价类划分策略。该方法避免了可变精度粗集中β近似的不足和缺陷,能够得出Bayes最优的分类规则,并给出了全域一致的隶属概率,避免了增广约简核的精度下降的不一致情形。
二、基本粗集模型与扩展

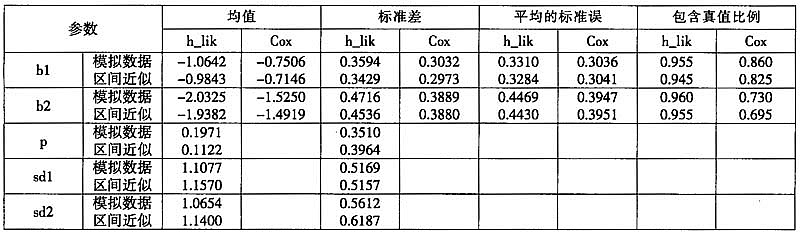
基于粗集的分类问题,就是通过个体在其属性集上观测到的取值或状态,来判断待分类集落入分类知识所形成的区域的情况。特别地,当X中仅能观测到部分属性集,而不能观测到判别属性时,粗集的边界判断问题就变成了决策问题①。

特别地,当β=1时,可变精度粗集就退化为普通的粗集。由于边界柔化,较之普通的粗集,可变精度粗集的容错能力和适应性能大大增强,在此基础上,派生出一系列基于β近似的数据约简[9]以及算法研究[10]等。
三、Bayes概率边界域划分准则
可变精度粗集的β近似考虑的频率主要是指类似于截面数据的多个体单次观测值集合。由于观测误差的存在,β近似中的频率只能看作是真实概率的一次观测值的实现,具体的频率值也只是随机变量的一个观测值,把这样的一次观测频率值作为概率显然是不合适的。虽然可以看作一个初始的先验概率,并且这个先验信息对于首次决策无疑是有效率的,但伴随着数据积累和决策经验增长,不断增加的观测值使得后续决策改进成为可能,基于概率的粗集方法也应当反映并包含这种由于经验积累所带来的决策改进。因此,本文认为有必要从统计角度对粗集的边界域近似指标进行重新构建,使其成为名副其实的概率近似粗集。
(一)包含观测误差的隶属度函数
由于观测中无法避免的误差,导致了个体属性值的测量偏差,进而影响分类的准确性②。这种误差首先是出现在单一属性的示性函数上,由示性函数汇总,并表现为隶属度函数的不确定性。
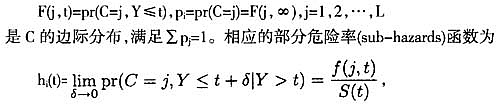
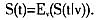
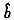
根据前述有关论述和推理,得到单一属性的示性函数之后,再根据前节推导就可以得到x∈X在所有属性变量上的Bayes概率分类规则。
但对于数值型变量而言,等价类划分策略可以千差万别,如何从中选择较优的一组分类策略就成为一个急需解决的问题。在主流的粗集方法中,数值型变量的等价类划分也被称为数值离散化,基本是被作为一个独立的过程进行。但这种处理方式显然疏忽了等价类的划分策略对于最终分类规则的影响。有鉴于此,结合bsyes概率边界域,本文提出了以下一种比较通用的数值型多属性等价类划分和选优步骤。
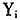
4.按照阈值β筛选出最优的分类策略。
四、Bayes边界粗集分类应用
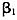
从图1可以看出,指标误差
由于进行了标准化,观测到的分布可以认为主要是由检测指标误差造成。因此,产品等级划分也将主要取决于每个指标的测量误差的分布。从分布中可以看到同一指标在不同分类等级上都有不同程度的重叠,这意味着,任一单指标的临界值分割方法将会得到非常大比例的次品,同时优良产品的比例将会非常小。所以要比较准确地判断产品等级,必须要考虑各单项指标误差在不同产品等级下

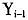
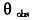
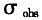
由于核密度函数实际上是未知的,所以最优带宽(式(18))只能是在某种程度的近似获取。本文选用的是Silverman(1986)提出的拇指规则带宽[12],
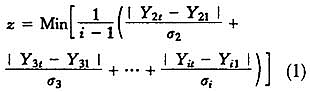
在缺乏关于样本分布先验知识的条件下,为了能够比较精确地拟合出分布特征,笔者将节点数设定为1001个,所有分布拟合的近似均方积分误差(AMISE)均小于0.001④。类似地,在经验分布拟合中,间隔点也被分为1000个。
关于等价类的划分策略,笔者选用了从-0.6(约为10%的分位数)开始,到2.0(约为90%的分位数)之间进行等间隔分类,间隔数依次从5增至20。在规则提取环节,保留了每个等价类的最大概率规则,这就使所有等价类都有明确的类别所属,保证了分类规则的完备性。但考虑到不同分类方法所产生规则的不一致性,统一保留了前100条规则作为优选的规则集。逐个计算其在不同划分策略下的样本内准确率之后,比较其在样本规模和拟合分布类型下的平均准确率。
为了比较分类效率和稳健性,笔者还将原始数据按照批次(Lot)从5批数据逐渐扩展样本容量至所有批次。此外,还将bayes概率边界域划分方法与传统的按照覆盖比例进行划分的粗集方法放在同一框架下进行对比分析。
表2Bayes概率边界域分类与简单粗集分类准确率的扩展样本对比

注:括号内为标准差。
表2列示了两种分类方法所得到的最优规则集合在不同扩展样本下的平均分类准确率。由于数据分布不具备明显的规律性,这使得基于平滑的核函数估计的整体准确率略低于采用经验分布的结果。从样本规模上看,伴随着样本批次的增加,这两类方法所得分类规则集的平均准确率和对应的标准差几乎不变。这表明两种方法对于样本规模具有很强的稳定性。但在各种情况下,采用bayes概率边界域分类方法不仅其平均准确率显著高于简单粗集分类方法,准确率提高幅度达60%~70%,而且对应的标准差仅为后者的80%~90%。
简单粗集边界判定方法的平均预测准确率(采用经验分布)

简单粗集边界判定方法的平均预测准确率(采用核密度分布)
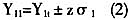
图3简单粗集分类法所得规则的平均分类准确率
图3、图4分别描述了两种粗集分类方法在样本规模和不同划分策略下的平均准确率变化情况。位于图上方的曲线为平均分类准确率,下方为对应的标准差。由于样本扩展一共得到6个不同规模的样本,而在每个样本内验证了16次不同的等价类划分策略,即每个样本期包含了16个横坐标刻度,因此横坐标刻度为1至96。从图中可以看出,在同一样本期中,伴随着划分策略的细化,准确率的上升呈现了一定的“凸性”,这表明分类准确率与等价类个数的关系存在拐点,这个拐点正是最优的等价类划分策略的所在。数据表明这个最优划分策略是对变量等间隔划分个数为10或11。
bayes边界判定方法的平均预测准确率(采用经验分布函数)
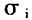
bayes边界判定方法的平均预测准确率(采用核密度函数)
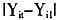
图4bayes边界域划分法所得规则的平均分类准确率
图4展示了基于bayes概率边界域的粗集分类方法所得到的前100个规则的平均预测准确率变化。与图3简单比较就可以发现bayes方法的明显优势:在每个样本期内,在每个划分策略下的平均分类准确率都要高于简单粗集分类方法,同时分类准确率的标准差及其波动性也都明显低于后者。
五、结论
粗集分类方法的观点就是对于定性数据,特别是不完全的定性数据进行决策分析或者分类。但并不意味着粗集分类就一定要牺牲数值型数据所提供的高质量信息。实际上,在当前计算成本相对较低的条件下,放弃决策信息的精确度已经变得没有必要,而且由此带来的信息损失将会直接误导决策。
本文所提出的基于Bayes概率边界域的粗集分类方法比较好地解决了这一问题。首先从数值型变量中提取充分的Bayes分类信息,然后再根据提取出分类规则的准确率来选择最优等价类。通过隶属概率的方式,充分利用了数值型变量的高质量信息,解决了数值型属性的粗集划分问题。同时还避免了可变精度粗集中β近似的不足和缺陷,以及增广约简核的精度下降的不一致情形。最后本文还对生产实践中的高频检测数据进行了实证分析,所得到的结果也支持了本方法的实践优势。
注释:
①在基于粗集的决策问题中,属性集被分成条件属性集和决策属性集。在条件属性集中寻找恰当的属性集的取值组合并对观测进行划分而得到一个基于值集相等的等价类族,通过考察等价类的属性集的取值频率,提取出“并发概率”较高的值集,并描述成为一条“IF-THEN”规则。对于分类问题,同样也要建立类似的规则,但与决策问题不同,其决策属性集是由分类知识派生出来的类别信息所构成。例如,通过考察一批观测数据后,发现可以将其分为五类。那么,这五个类别(有时还会加入一个无法判断的类别),就构成了后续观测数据的决策属性集。这五个类别并不是由观测数据本身提供,而是根据分析结果推断得出。而对于后续观测数据而言,其决策属性集则是给定的,需要进一步根据其可观测的条件属性集加以判断。所以本文将决策问题作为分类问题的特例看待,不加以区分。
②特别是工业生产中的检测系统,比较容易受到生产环境的影响,检测仪器需要经常性的调整和校准以减小误差。
③在各个等级下的参数分布拟合优度均不显著,故省略。
④通过反复拟合数据,我们发现当节点数n大于800时,不同核函数和带宽设定之间的差异微乎其微。
【参考文献】
[1]Z. Pawlak. Rough Sets[J]. Int'l Journal of Computer and Information Sciences, 1982(11):341-356.
[2]来升强,朱建平.数据挖掘中高维定性数据的粗糙集聚类分析[J].统计研究,2005,8.
[3]王钰,苗夺谦,周育健.关于Rough Set理论与应用的综述[J].模式识别与人工智能,1996,9(4):337-344.
[4]张文修,吴伟志,梁吉业,李德玉.粗糙集理论与方法[M].北京:科学出版社,2001.
[5]W. Ziarko. Introduction to the special issue on rough sets and knowledge discovery[J]. Communications of ACM, 1995, 38(Ⅱ):89-95.
[6]W. Ziarko. Variable precision rough set model[J]. Journal of Information and System Science, 1993.
[7]杜卫锋.粗糙集理论在中文文本分类中的应用[D].西南交通大学博士学位论文,2006.
[8]W. Ziarko. Probabilistic decision tables in the variable precision rough set model[J]. Computational Intelligence, 2001,3(17):593-603.
[9]M. Beynon. Reducts within the variable precision rough sets model: a further investigation[J]. European Journal of Operational Research, 2001,134:592-605.
[10]梁吉业.基于粗糙集与概念格的智能数据分析方法研究[D].中科院计算技术研究所博后工作报告.
[11]吉阳生,商琳.可变精度粗糙集β值的增量计算[J].计算机科学,2008,3(35):228-230.
[12]B.W. Silverman, Density Estimation[M]. Chapter 3. 1986,
【原文出处】《统计研究》(京)2010年3期第76~82页
【作者简介】来升强,男,1981年生,江苏人,厦门大学计划统计系在读博士生,研究方向为高频数据挖掘。
谢邦昌,男,台北人,台湾辅仁大学统计资讯学系教授,博导,厦门大学计划统计系讲座教授,博导,研究方向为数据挖掘和商业智能。
朱建平,男,山西人,厦门大学计划统计系系主任,教授,博导,研究方向为数据挖掘、数理统计和计量经济学。