内容提要:面板研究是纵贯面研究领域的一种重要类型,近年来,国外运用多层线性模型在面板研究领域取得了一系列理论和应用上的进展。通过对面板研究的界定,对面板研究的发展情况、数据特征进行简要介绍,在与传统统计分析方法进行比较的基础上,重点阐述多层线性模型在面板研究领域的独特优势及其一般建模方法和过程,分为线性发展模型、曲线发展模型和三层发展模型进行解读,并结合多个实例分析不同类别的多层线性模型在面板研究中的应用情况,指出现存的面板研究中多层线性模型应用需要注意的时间变量设定及中心化、固定效应和随机效应的选择及样本量等问题,同时进一步指出多层线性模型在未来面板研究领域存在的调节作用和中介作用、结构方程模型的选择应用等发展方向。
关键词:面板研究多层线性模型纵贯面研究发展模型
作者简介:郑昱(1977-),女,山东济南人,中国科学院心理研究所(北京100101),中国科学院研究生院博士研究生(北京100039),研究方向:效能感、行为决策等,E-mail:zhengy@psych.ac.cn;王二平,中国科学院心理研究所。
1引言
1963年,Harris所著的《测量变化的问题》(Problems in measuring change)一书问世,该书探讨了随时间积累的数据分析问题,由此引发研究者对纵贯面研究的重视,关于纵贯面研究的各种方法论探讨陆续涌现。Bijleveld等[1]根据数据结构中时间变量和观测对象关系的不同,将纵贯面研究进一步分为5种类型,面板研究(panel study)是其中一种。一般而言,面板研究是指同一时间内有系统地观察以不同时间组或不同群体所做分类的样本,在未来不同时间点里不同研究变量上的变化。面板研究的发展可以追溯到20世纪60年代,并在最近20年得到飞速发展,这主要得益于各国面板数据库的建立和完善,其中比较著名的是美国密西根大学的收入动态面板研究(panel study of income dynamics,PSID)和美国劳动力市场纵向研究(national longitudinal survey of labor market experience,NLS)[2]。PSID研究开始于1968年,每年调查5 000个家庭和15 000个个人的全国代表性样本的经济数据,数据库包括5000个以上的变量,如家庭状况、收入就业状况等。NLS开始于1966年,主要体现在劳动力市场的供给方面,包括劳动力市场中5个相互独立的追踪数据集。
多层线性模型(multilevel model)由Lindley等[3]于1972年提出,是用于分析具有嵌套结构数据的一种统计分析技术。作为传统方差分析模型的有效扩展,Korendijk等[4]和Duncan等[5]众多的研究者对多层线性模型进行了广泛研究。Laird等[6]于1982年率先提出在纵贯面数据中建立一个两层次随机效应模型的方法,在两层次中区分方差分量。20多年来,该方法在社会科学领域获得了广泛应用。近年来,有研究者提出使用多层线性模型进行面板研究,并且已在社会科学领域取得较大进展[7]。本研究主要讨论多层线性模型在面板研究中的发展和应用。
2面板研究中传统分析方法的局限性和多层线性模型应用的优势
2.1面板研究的数据特征和传统分析方法的局限性
除了收入动态面板研究和美国劳动力市场纵向研究之外,表1(见下页)给出部分在各国比较有影响的面板研究数据库。
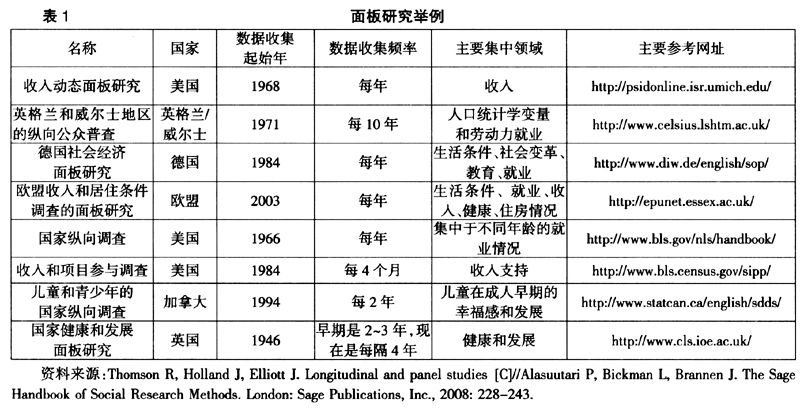
Thomson等[8]根据面板数据库建立中被调查者所接受调查内容时间导向的不同,将面板研究的数据收集方法分为前瞻性研究和回溯性研究两种。如果所调查项目是针对被调查者过往时间点的信息,即为回溯性研究;而针对被调查者当前和对未来时间点预期的信息,则属前瞻性研究。如英国家庭面板调查(the British household panel survey,BHPS)即属于前瞻性面板研究,其每年调查受访者当前的生活条件、态度和信仰等信息。但由于面板研究的数据收集一般来自于大范围的调查,经常会结合众多不同数据的收集方法进行,所以很难清晰划分前瞻性和回溯性研究,存在前瞻性研究中结合回溯性研究的情况[8]。如BHPS在1992年和1993年的两轮调查中,被调查者回答的问题中也包括了有关他们过去的雇佣经历等信息。另外,前瞻性面板研究还存在一种延伸类型是链接性面板研究,一般使用公众普查或管理数据,如医院的治疗或收益记录的信息等。该研究的数据收集过程是被调查者介入最少的一种,调查收集的数据会与未来某个时间所收集的数据链接后进行结合分析。对面板数据分析中所采用的方法进行研究,大致可以分为固定效应模型和具有滞后内生变量的面板数据模型检验等。Lichter等[9]采用固定效应模型分析政府福利支出对女性主导型家庭的影响,他们利用1980年至1990年对美国48个州中6 106个家庭的调查数据进行分析,其中因变量是以未婚女性为户主的有18岁以下孩子的家庭比例,解释变量包括男性就业率、性别比例、女性的经济独立程度等,该研究中没有进行豪斯曼检验的相关信息;McManus等[10]利用1980年至1993年的PSID数据研究分居和离婚对于18岁至65岁男性的经济影响,时间表征用当前时间t的(t-1)和(t+1)之间的婚姻解体时间,是采用滞后因变量的面板数据分析;Budig等[11]采用固定效应模型对1982年至1993年美国全国纵向研究的数据分析至少从事两年全职或兼职工作的女性,研究样本中女性在成为母亲后工资收入上的损失变化。这些研究中大部分都倾向于采用随机效应模型分析,同时较少研究者采取有效的措施处理面板数据中个体间差异、个体内差异以及相应地区差异的问题,这对于研究结论无疑会产生一定的影响。
由以上面板研究的数据收集方式和相应研究实例可以看出,面板研究的数据存在较明显的特征。首先,在长期追踪中,历经多年追踪却没有缺失值的情况是少之又少。一般情况下,某些被调查者可能会因为各种原因而中断,那些仍留在研究中的被调查者也可能由于某些原因错过随访观察的机会,所以经常会出现面板研究数据库中若干观测值缺失的情况[12]。针对这种情况,传统的纵贯面分析中常用的多元方差分析要求所有研究对象须在每一个时间点都得到观测,一旦出现数据缺失,就不得不剔除有缺失数据的对象样本。当因追踪时间较长而出现数据缺失的情况时,就会造成统计效力的下降[13]。其次,由于是对每一个被调查者反复收集数据,因此研究对象内的观察值之间会存在相关。最后,面板数据的差异来源一般包括研究被试内差异和被试间差异以及地区间因时间发生的差异,而且这些差异可能会随时间的变化而发生改变[13],针对这种情况,另一种常用的纵贯面研究分析方法是重复测量方差分析,其前提假设要求不同时间点上的残差方差相同,且协方差为常数[14],这样的假定条件在大多数面板数据中都不太可能成立,因此在实际应用中受到限制。
2.2面板研究中多层线性模型的应用优势
由上述分析可知,在面板研究中,传统的数据分析方法会遇到很多难以克服的困难,而多层线性模型可以很好地处理上述问题。近年来,越来越多的面板研究开始采用多层线性模型的分析方法,显示出多层线性模型在面板研究中的独特优势。
首先,多层线性模型通过考察个体水平在不同时间点的差异,明确表达出个体在层次一的变化情况,因而对于数据的解释(个体随时间的增长趋势)是在个体与重复观测交互作用基础上的解释,即不仅包含不同观测时点的差异,也包含个体之间存在的差异[15]。
其次,多层线性模型可在最大似然或限制性最大似然估计的基础上处理缺失值,因此对原始数据的要求相对较低,不需要去除那些带有缺失值的研究对象,也不需要弥补缺失的观测值[16-18]。另外,多层线性模型既能处理各研究对象重复观测次数不等的问题,也能处理重复观测间隔时间不等的问题。
再次,多层线性模型可以定义重复观测变量之间的复杂协方差结构,对不同协方差结构进行显著性检验,通过定义数据不同层次的随机差异解释个体随时间变化的复杂情况[19]。例如就个体间差异而言,模型假设研究对象在不同时间的观测值相关是由于非测量因素产生的个体间异质性引起的,因此在模型中设定随机回归系数,如用随机截距反映个体结果测量值的不同初始水平,用时间变量的随机斜率反映个体结果观测随时间的不同变化率,从而引入个体特定效应来处理个体间异质性问题[13]。从个体内差异角度出发,则可以在构建模型之初通过设定一个适当的残差方差/协方差结构来处理数据的序列相关问题。
最后,多层线性模型既不要求研究对象个体内的观测值相互独立,也不受某些限制性假设的制约。例如时间序列分析作为一种传统的纵贯面研究方法一般要严格限制所观测个体的数量,同时要求重复观测的次数较多[12]。多层线性模型也非常容易在模型中加入时变协变量,在重复测量数据中,个体水平的协变量(如性别、种族等)是非时变变量,因为它们不随时间变化而变化,但观测水平的测量(如职位、经济收入等)都可能是时变协变量,其值可随时间的变化而发生改变[6]。允许时变协变量的加入,使面板研究的分析更加具有灵活性和实效性。
3多层线性模型在面板研究中的应用
面板数据可以构造为一个两水平或三水平的层次结构,即在个体内不同时间的重复观测为层次一的单位,层次一分析的目标是得出每个个体随时间的成长变化轨迹;个体间观测的差异为层次二的单位,层次二分析的目标是关于个体间变化的异质性,以确定预测因素和成长轨迹的关系;群体或组织变量为层次三的单位,层次三分析的目标是确定群体间变化的异质性[5]。根据研究要求,还可以建立两水平或多于三水平的多层模型。图1(见下页)以三层线性模型为例,展示面板研究中的两水平和三水平线性模型[20]。

由图1可以看出,应用多层线性模型的面板研究有助于研究者进一步探明各种变量间的关系,同时可有效考察不同变量发展趋势之间的差异[21]。多层线性模型的重要性日益受到研究者的重视,自20世纪80年代以来,开始涌现出专门用于多层线性模型分析的统计软件,常用的有hierarchical linear models(HLM)[22]和MLn,另外一些综合性软件在近年也增加了处理多层线性模型的专用模块,如SAS、STATA、SPSS以及结构方程模型的专业软件LISREL、MPLUS。但在多层线性模型中应用最广、升级最快的统计软件为HLM,本研究中举例的面板研究中所建立的多层线性模型基本都是应用HLM软件进行数据分析。
3.1多层线性模型在面板研究应用中的分类
以两层次模型为例,面板研究中的多层线性模型的一般表达式如下。
层次一为个体内模型,即

上述模型的建立主要讨论个体结果变量的变化、或是变量变化的组间效应以及造成结果变量变化的影响因素等方面的问题[23]。如果将模型中的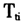 变量去掉,则模型是由同一个研究对象在不同时间点的解释变量和结果变量构成的,据此分析这两个变量随时间变化的关系;如果将
变量去掉,则模型是由同一个研究对象在不同时间点的解释变量和结果变量构成的,据此分析这两个变量随时间变化的关系;如果将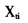 变量去掉,该模型也称之为线性发展模型,即
变量去掉,该模型也称之为线性发展模型,即
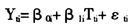 (3)
(3)
为了确定结果变量的平均发展趋势是直线还是曲线模式,可以设定时间变量不同的多项式函数,如二次方和三次方时间多项式函数模型。根据设定时间变量多项式函数的不同,在实际应用中可分为线性发展模型和曲线发展模型。
3.1.1线性发展模型
在实际研究中,最常用的又可进一步分为随机系数模型以及以截距和斜率为结果的模型。
在随机系数模型的建立中,通常是从拟合零模型开始,该模型将总的差异分解为个体内和个体间两个部分,用来检验个体间是否存在差异以及计算个体间的差异在总差异中所占的比例[13]。如果个体间的差异不显著,即表示没有对数据进行多层统计分析的必要。零模型是后面模型分析的基础,可以通过零模型的结果来判断组内相关系数(intraclass correlation coefficient,ICC)的大小,从而可以说明同一个体的测量是否有较大相似性[24]。同时基于极大似然函数得出的差异统计量是描述模型整体拟合程度的统计指标,可以对两个具有嵌套关系模型的拟合程度差异性进行检验。在零模型的基础上,在层次一增加描述时间的变量可以得到无条件线性增长模型,该模型的层次一属于个体内层次,主要用来描述个体随时间的线性变化趋势,在层次一研究的主要目标是得出每个个体随不同时间点所表现的成长变化轨迹。层次二属于个体间层次,用来解释这种线性变化趋势是否存在个体差异[25]。通过该模型与零模型的差异统计量的对比,可以判别加入时间变量后层次一的模型拟合程度的改变情况。
举例说明。Lucas等[26]在对婚姻状况改变导致的反应和适应的研究中建立最初的零模型。
层次一为

用于检验从结婚前一年到结婚后持续两年间的反应是否存在个体差异,结果表明,结婚对于个体生活满意度的影响十分显著,对比结婚前一年的生活满意度,个体的生活满意度有明显提升;同时在层次一模型的基础上增加结婚后两年经历期的变量,发现个体在结婚后两年生活满意度会有所下降,但仍比结婚前一年的生活满意度有显著提高,这种状况存在个体间差异。在虚拟编码时间变量所表示的不同时间段中,“经历期”之前的时间变量“前一年”为基点时间设计,经历期作为反应时间段编码为1,其他年份为0。
以截距和斜率为结果的模型是在无条件线性增长模型的层次二模型中增加解释变量,层次一解释结果变量随时间增长的线性模型,层次二用不同解释变量来描述预测个体间不同发展趋势的差异[21]。通过固定部分的参数估计结果可以得出结果变量的初始均值水平和各解释变量的初始均值水平,通过随机部分的参数估计结果可以得出,在考虑不同解释变量对个体间发展差异的影响之后,用截距和斜率的差异是否显著来说明各自解释差异的改变程度[27]。模型的整体拟合差异统计量通过与无条件线性增长模型的比较可以从总体上说明解释变量对于结果变量及随时间变化的预测作用。
举例说明。Luhmann等[28]有关重复生活事件(如重复失业等)对于生活满意度影响的研究,在层次二中增加性别、年龄、外倾性、神经质、重复事件的持续期等诸多解释变量。样本数据来自德国社会经济面板研究数据库german socio-economic panel,GSOEP)。以重复失业为例,层次一模型为


另外,在面板研究中,若需要同时检验个体若干特征随时间变化的特点以及若干特征之间变化趋势的差异,可以应用多元多层线性模型[29-30],该模型是将单因变量的线性发展模型扩展到对多个因变量同时检验的方法,考虑到重复测量被认为是嵌套于个体本身,一般在HLM软件应用中,层次一通过设定虚拟变量来区分不同时间变量下的不同因变量,如用 区分3个不同的因变量,以描述因变量的多元结构层次。层次二为时间变量的设定,为测量水平,层次二要用另外的虚拟变量标示出对于因变量的测量次数。如果需要考察个体间不同特征变量(非时变特征)对于不同因变量变化趋势的交互作用,可以增加层次三来设定变量,在SAS软件中则可以直接加入层次二设定交互项。通过最后对于相关矩阵的分析可以得知,如果截距之间存在显著相关,说明初始因变量值之间存在显著相关;截距和斜率之间存在显著相关,则说明初始水平的因变量值与其发展变化速度之间的变化呈显著相关。因此,多元多层线性模型不仅可以用来分析多个因变量初始水平间的变化关系,还可以用来分析多个因变量之间变化速度的关系。模型可以表示为
区分3个不同的因变量,以描述因变量的多元结构层次。层次二为时间变量的设定,为测量水平,层次二要用另外的虚拟变量标示出对于因变量的测量次数。如果需要考察个体间不同特征变量(非时变特征)对于不同因变量变化趋势的交互作用,可以增加层次三来设定变量,在SAS软件中则可以直接加入层次二设定交互项。通过最后对于相关矩阵的分析可以得知,如果截距之间存在显著相关,说明初始因变量值之间存在显著相关;截距和斜率之间存在显著相关,则说明初始水平的因变量值与其发展变化速度之间的变化呈显著相关。因此,多元多层线性模型不仅可以用来分析多个因变量初始水平间的变化关系,还可以用来分析多个因变量之间变化速度的关系。模型可以表示为

3.1.2曲线发展模型
如果时间函数的二次方和三次方系数均不统计显著,且整个模型拟合相对于线性时间趋势函数模型也无显著改善,可以判定该模型不存在曲线关系[31];若统计显著,说明结果变量随时间变化呈非线性发展,如Chan等[32]对新员工随时间的适应性研究和Lucas等[26]对丧偶的适应性研究。在Lucas等[26]的研究中为检验进入丧偶状态对于个体的影响是否存在适应性,即由于丧偶状态的确立对于个体生活满意度的改变是否经过一段时间会回到丧偶前的生活满意度水平,是否呈现曲线发展趋势,于是建立二次方时间函数,层次一为
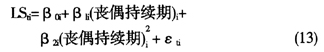
检验结果表示二次方系数统计显著,表明丧偶者生活满意度的下降呈曲线发展状况,大约8年时间才能恢复到他们之前的基点生活满意度水平,从而验证关于适应性有曲线发展的假设。一般而言,若用t=0,1,2,3来表示时间,则可以用时间变量t的平方0,1,4,9来描述二次增长趋势,时间变量t的三次方0,1,8,27来描述三次增长趋势,通常对K个时间点的测量,可以用时间的(K-1)阶多项式准确地描述因变量的增长趋势。但在类似的多次方时间多项式函数模型中,较容易出现多重共线性问题,Enders等[33]指出,将时间项中心化或者使用正交多项式的时间测量方法可以予以避免。
3.1.3三层结构的多层线性模型
面板研究中三层结构的多层线性模型比较少见,Bryk等[22]在研究学生的成绩变化情况时,提出建立三层次多层线性模型的方法。一般而言,层次一为被试内模型,即

层次三为被试群体/组织特征模型[14],即

检验结果表明个体的成绩进步在幼儿园、暑假和一年级期间与其所受家庭教育有关,可以由K、S、F的相应回归系数表明;层次二进行组中心化的均值处理,表示每个被试的学业成绩的变化轨迹;层次三的学校间模型主要考察被试学业成绩的时间变化是否存在学校间差异的影响,即个体所在不同学校的特征能否解释其在不同时间段学业成绩的变化情况。该研究后续又在层次二增加种族变量,检验不同种族的个体随时间成绩变化的状况,一般把非时变变量放在层次二,可以用来进一步通过层次二代入层次一产生的乘积项考察是否存在跨层次的调节作用。
另外,三层次线性发展模型也可以同时构建二次方或三次方时间项,以Smokowski等[35]在社区管理领域内拉丁裔青少年暴力的影响因素的研究为例,其选取的样本来自拉丁裔文化和健康项目。为验证是否存在非线性关系,作者在层次一设定了二次方时间项,即

该层次为青少年和家庭特征层次,等同于一般意义上的组织特征层次。(23)~(28)式和(14)~(18)式非常类似,只是省略了个体层次的自变量和特征属性变量,保留了组织层次的特征属性变量((26)式中以X表示家庭特征属性变量)。如果该例中的二次方系数统计显著,说明拉丁裔青少年暴力的发展变化呈非线性发展状况,呈曲线发展。通过层次三对于多个人口统计学变量作为自变量的引入,可以用来说明是否拉丁裔青少年暴力发展变化受年龄大小、男女等变量差异的影响。由以上分析可知,在三层次的线性发展模型中,层次二和层次三其实相当于横截面分析的多层线性模型的层次一和层次二结构,存在3次嵌套,重复测量嵌套于个体,个体嵌套于群体。
3.2多层线性模型在面板研究应用中的关键性问题
3.2.1时间变量设定及中心化问题
面板研究中非常重要的一个问题是对时间变量设定合适的值,通过对不同的时间变量的设定,其相应模型参数估计值的解释也不同。如将时间变量设定为基点为“0”的值,0、1、2、3、4、5,每一个时间点代表一个随访的时点,模型中的截距代表结果变量测量得出的平均初始值或基点调查所得出的均值。另外,根据研究的需要,也可将观测期的任何时间点设定为0,此时模型的截距表示设定时间点的结果测量均值。一般在有关治疗疗效的对比研究中,常将研究终点作为参照时点,在有关绩效考核等方面的研究中,常将研究起点作为参照时点,具体应与研究者的研究目的相匹配。而在一般多层线性模型的建立中,往往需要对第一水平的自变量做组中心化的处理[13],但在面板研究中,研究者一般对描述时间的变量按照研究目的的不同在时间变量的设定时已做出不同的转换,使截距项有明确的含义,从而可以不再做中心化处理。
3.2.2固定效应与随机效应的选择问题
多层线性模型第二层、第三层回归系数的随机效应或固定效应的选择,应该是从理论出发,可以进行先行测试是否存在随机效应,当固定效应出现几乎为0的结果时可能就要考虑是否有随机效应的出现[36-37]。Longford[38]建议当第二层组数较少时宜采用固定效应模型,组数过多时可采用随机效应模型。Snijders等[39]则建议当组数少于10组时,宜采用固定效应模型,当样本来自总体抽样的结果而欲推论回总体时则建议采用随机系数模型。
3.2.3面板数据中的样本量问题
现在基于两轮数据的面板研究其统计效力受到普遍质疑,如无法确定变化的趋势是稳定还是波动,无法根据两轮数据做出不同观测对象的发展曲线,而这是多层线性模型中层次一的核心部分[40]。一般而言,测量的次数越多,多层线性模型的分析结果也就越可靠,因此一般建议使用三轮以上的面板数据进行多层线性模型的分析。
与传统统计模型一样,多层线性模型也假定样本所代表总体的发展趋势具有同质性,即不存在不同特征子总体发展趋势差异的问题。但是,当不同的子总体发展趋势本身存在差异时,运用多层线性模型进行分析不能很好地找出不同子总体中可能存在的不同关系以及可能忽视的一些重要的预测关系变量[41]。要解决这一问题,一般应先建立分层模型,然后再引入观测误差模型。通过估计这些潜在变量的联合分布,可以估计它们的直接作用和间接作用[36]。
4发展方向
时至今天,人们已经不满足仅仅对于现象的静态描述(横截面研究)和简单的差异检验,要想对行为的内因有更深入的探索,更准确地把握事物发展的内在规律,面板研究必然会越来越受到重视。面板研究难免发生数据库中研究对象流失或数据缺失,这种情况往往造成传统统计分析技术检验力下降,即使在大样本情况下,得到的参数估计结果也可能有偏。然而,多层线性模型是在最大似然或限制性最大似然估计的基础上处理缺失值,对原始数据的要求相对较低,既能处理各研究对象重复观测次数不等的问题,也能处理重复观测间隔时间不等的问题,也非常容易在模型中加入时变协变量,使得在实际应用中多层线性模型解决问题更显灵活,应用面更广,因此具有一般传统方法所无法比拟的独特优势。
面板研究领域近年来还出现了几个新动向。第一是运用多层线性模型检验各种变量的中介作用和调节作用[42-43]。Preacher等[44]通过验证在调节变量和自变量之间的交互作用来解释调节作用,为解释交互作用的显著性构建交互作用曲线来验证在多层线性模型中的简单效应;MacKinnon等[45]引入系数生成法,通过验证因变量与自变量之间间接关系的显著性来解释中介作用,通过自变量与因变量之间直接关系的显著性可以区分完全中介作用和部分中介作用,通过自变量与因变量之间直接关系的不存在来解释间接中介作用。
第二是出现不少研究者开始应用结构方程模型进行面板数据的分析[6]。Willett等[46]证明一部分二层次增长模型也可以用结构方程模型来估计。例如结构方程模型中的测量模型对应于多层分析中的层次一模型,其潜在变量就是多层模型中的个人增长参数,即结构方程模型中的结构模型对应于多层分析中的层次二模型。这意味着一旦转变为结构方程模型框架,就可以利用结构方程模型中的所有协方差结构分析,包括自相关的层次一随机效应和异质性的层次二随机效应。但这种研究框架仍然存在一个与多元重复观测分析方法一样的局限,它要求数据具备平衡时间结构,即每个受访者都必须具有相同的受访次数和间隔,且所有层次一的自变量都必须具有相同的分布[13]。对于这一问题,已有结构方程模型的应用软件要求数据具有时间结构设计的同时,可以允许有随机缺失数据。
第三是关于多层线性模型和结构方程模型哪一个更适合面板研究的讨论[6, 47],现在二者在面板研究领域中已经出现并行使用的情况,由于多层线性模型对于变量间关系的探讨是对于直接影响关系的分析,结构方程模型则可以合理地对变量之间复杂因果关系进行进一步的分析,因此基于结构方程模型基础上较新的对于面板数据进行分析的统计方法,即潜变量增长曲线模型,则可以同时对个体的发展趋势和个体间的差异进行解释,而且可以对变量之间复杂的因果关系进行分析,现在已有软件可以对于潜变量发展进行多层次分析,相信未来在面板研究的分析领域会不断有更高效度的模型陆续涌现。
5结论
本研究对面板研究中多层线性模型的构建和应用进行评述。近年来,面板研究作为纵贯面研究领域的一种重要类型,国外在面板研究领域运用多层线性模型取得了一系列理论和应用上的进展。本研究通过面板数据的特征分析,结合相关研究文献介绍传统研究分析方法的局限性,同时对面板研究的发展情况、国际相关面板数据库的建立情况进行简要回顾和介绍,在与传统统计分析方法进行比较的基础上,重点分析多层线性模型在面板研究领域的贡献,如多层线性模型对于数据的解释(个体随时间的增长趋势)是在个体与重复观测交互作用基础上的解释,即不仅包含不同观测时点的差异,也包含个体之间存在的差异,多层线性模型可在最大似然或限制性最大似然估计的基础上处理缺失值,因此对原始数据的要求相对较低;同时通过对层次二的引入解决个体异质性的问题,也不要求研究对象个体内的观测值相互独立,从而大大扩展面板研究的范围。另外重点阐述多层线性模型的一般建模方法和过程,分为线性发展模型、曲线发展模型和三层发展模型进行解读,其中二次方曲线发展模型和多元多层线性模型的构建是研究者应给予较多关注的领域,如多元多层线性模型较好地解决了多个因变量随时间发展变化的速度之间的关系。通过多个实例分析不同类别的多层线性模型在面板研究中的应用情况,指出现存的面板研究中多层线性模型应用需要注意的时间变量设定及中心化、固定效应和随机效应的选择和样本量等问题。在应用多层线性模型进行面板研究时,还应考虑对于调节作用和中介作用的检验,结构方程模型或其他新涌现的统计分析方法与多层线性模型的比较以及在面板研究中的应用实践。
就中国的具体情况而言,目前面板研究多集中于经济学研究领域,心理学和管理学等研究领域几乎没有面板数据积累,应用面板研究的条件自然不存在。这种现状既有缺乏足够的财力支持的原因,也有学者们缺乏有意识积累研究数据的原因。目前,国家科技部已相继支持了两个重大基础数据库建设,相信面板研究未来会在更多的研究领域内兴盛。
参考文献:
[1]Bijleveld C C J H, Van der Kamp L J. Longitudinal data analysis: Designs, models and methods[M]. London: Sage Publications, Inc., 1998: 1-79.
[2]Hsaio C. Analysis of panel data[M]. 2nd ed. Cambridge: Cambridge University Press, 2003: 1-3.
[3]Lindley D V, Smith A F M. Bayes estimates for the linear model[J]. Journal of the Royal Statistical Society, 1972, 34(1): 1-41.
[4]Korendijk E J H, Maas C J M, Moerbeek M, Van der Heijden P G M. The influence of misspecification of the heteroscedasticity on multilevel regression parameter and standard error estimates[J]. Methodology: European Journal of Research Methods for the Behavioral and Social Sciences, 2008, 4(2): 67-72.
[5]Duncan T E, Duncan S C, Strycker L A. An introduction to latent variable growth curve modeling: Concepts, issues, and applications[M]. 2nd ed. New Jersey: Lawrence Erlbaum Associates, 2006: 163-200.
[6]Laird N M, Ware J H. Random-effects models for longitudinal data[J]. Biometrics, 1982, 38(4): 963-974.
[7]Hox J J. Multilevel analysis: Techniques and applications[M]. Mahwah, NJ: Lawrence Erlbaum Associates, 2002: 23-89.
[8]Thomson R, Holland J, Elliott J. Longitudinal and panel studies[C]//Alasuutari P, Bickman L, Brannen J. The Sage Handbook of Social Research Methods. London: Sage Publications, Inc., 2008: 228-243.
[9]Lichter D T, McLanghlin D K, Ribar D C. Welfare and the rise in female-headed families[J]. American Journal of Sociology, 1997, 103(1): 112-143.
[10]McManus P A, DiPrete T A. Losers and winners: The financial consequences of separation and divorce for men[J]. American Sociological Review, 2001, 66(2): 246-268.
[11]Budig M J, England P. The wage penalty for motherhood[J]. American Sociological Review, 2001, 66(2): 204-225.
[12]Frees E W. Longitudinal and panel data: Analysis and applications in the social sciences[M]. Cambridge: Cambridge University Press, 2004: 1-17.
[13]Raudenbush S W, Bryk A S. Hierarchical linear models: Applications and data analysis methods[M]. 2nd ed. Thousand Oaks, CA: Sage Publications, Inc., 2002: 31-198.
[14]Stevens J. Applied multivariate statistics for the social sciences[M]. New Jersey: Lawrence Erlbaum Associates, 1996: 23-99.
[15]Bickel R. Multilevel analysis for applied research: It's just regression![M]. New York: The Guilford Press, 2007: 285-329.
[16]王济川,谢海义,姜宝法.多层统计分析模型:方法与应用[M].北京:高等教育出版社2008:81-127.
Wang Jichuan, Xie Haiyi, Jiang Baofa. Multilevel models: Methods and applications[M]. Beijing: Higher Education Press, 2008: 81-127.(in Chinese)
[17]Cheung M W-L. Comparison of methods of handling missing time-invariant covariates in latent growth models under the assumption of missing completely at random[J]. Organizational Research Methods, 2007, 10(4): 609-634.
[18]Bodner T. Missing data and small-area estimation: Modem analytical equipment for the survey statistician[J]. Psychometrika, 2007, 72(1): 115-116.
[19]刘红云,孟庆茂.纵向数据分析方法[J].心理科学进展,2003,11(5):586-592.
Liu Hongyun, Meng Qingmao. A review on longitudinal data analysis method and it's development[J]. Advances in Psychological Science, 2003, 11(5): 586-592.(in Chinese)
[20]Heck R H, Thomas S L. An introduction to multilevel modeling techniques[M]. 2nd ed. London: Psychology Press, 2008: 163-200.
[21]Maas C J M, Snijders T A B. The multilevel approach to repeated measures for complete and incomplete data[J]. Quality and Quantity, 2003, 37(1): 71-89.
[22]Bryk A S, Raudenbush S W. Toward a more appropriate conceptualization of research on school effects: A three-level hierarchical linear model[J]. American Journal of Education, 1988, 97(1): 65-108.
[23]温福星.阶层线性模型的原理与应用[M].北京:中国轻工业出版社,2009:217-244.
Wen Fuxing. Methods and applications of multilevel models[M]. Beijing: China Light Industry Press, 2009: 217-244.(in Chinese)
[24]Leeuw J D, Meijer E. Introduction to multilevel analysis[C]//Leeuw J D, Meijer E. Handbook of Multilevel Analysis. New York: Springer, 2008: 1-68.
[25]Graham S E. Singer J D, Willett J B. An introduction to the multilevel model for change[C]//Alasuutari P, Bickman L, Brannen J. Handbook of Social Research Methods. London: Sage Publications, Inc., 2008: 377-394.
[26]Lucas R E, Clark A, Georgellis Y, Diener E. Reexamining adaptation and the set point model of happiness: Reactions to changes in marital status[J].Journal of Personality and Social Psychology, 2003, 84(3): 527-539.
[27]Bliese P D, Chan D, Ployhart R E. Multilevel methods: Future directions in measurement, longitudinal analyses, and nonnormal outcomes[J]. Organizational Research Methods, 2007, 10(4): 551-563.
[28]Luhmann M, Eid M. Does it really feel the same? Changes in life satisfaction following repeated life events[J]. Journal of Personality and Social Psychology, 2009, 97(2): 363-381.
[29]Mac Callum R C, Kim C, Malarkey W B, Kiecolt-Glaser J K. Studying multivariate change using multilevel models and latent curve models[J]. Multivariate Behavioral Research, 1997, 32(3): 215-253.
[30]Deadrick D L, Bennett N, Russell C J. Using hierarchical linear modeling to examine dynamic performance criteria over time[J]. Journal of Management, 1997, 23(6): 745-757.
[31]Skrondal A, Rabe-Hesketh S. Multilevel and related models for longitudinal data[C]//Leeuw J D, Meijer E. Handbook of Multilevel Analysis. New York: Springer, 2008: 275-299.
[32]Chan D, Schmitt N. Interindividual differences in intraindividual changes in proactivity during organizational entry: A latent growth modeling approach to understanding newcomer adaptation[J]. Journal of Applied Psychology, 2000, 85(2): 190-210.
[33]Enders C K, Tofighi D. Centering predictor variables in cross-sectional multilevel models: A new look at an old issue[J].Psychological Methods, 2007, 12(2): 121-138.
[34]Cheadle J E. Parent educational investment and children's general knowledge development[J]. Social Science Research, 2009, 38(2): 477-491.
[35]Smokowski P R, Rose R A, Bacallao M. Acculturation and aggression in Latino adolescents: Modeling longitudinal trajectories from the Latino acculturation and health project[J]. Child Psychiatry and Human Development, 2009, 40(4): 589-608.
[36]Bliese P D, Ployhart R E. Growth modeling using random coefficient models: Model building, testing, and illustrations[J].Organizational Research Methods, 2002, 5(4): 362-387.
[37]Ployhart R E, Hohz B C, Bliese P D. Longitudinal data analysis: Applications of random coefficient modeling to leadership research[J]. The Leadership Quarterly, 2002, 13(4): 455-486.
[38]Longford N T. Random coefficient models[M]. Oxford: Oxford University Press, 1993: 44-67.
[39]Snijders T A B, Berkhof J. Diagnostic checks for multilevel models[C]//Leeuw J D, Meijer E. Handbook of Multilevel Analysis. New York: Springer, 2008: 141-175.
[40]Singer J D, Willet J B. Applied longitudinal data analysis: Modeling change and event occurence[M]. Oxford: Oxford University Press, 2003: 23-56.
[41]刘红云.如何描述发展趋势的差异:潜变量混合增长模型[J].心理科学进展,2007,15(3):539-544.
Liu Hongyun. How to abstract development variations: Latent growth mixed model[J]. Advances in Psychological Science, 2007, 15(3): 539-544.(in Chinese)
[42]Raudenbush S W, Sampson R. Assessing direct and indirect effects in multilevel designs with latent variables[J]. Sociological Methods & Research, 1999, 28(2): 123-153.
[43]Edwards J R, Lambert L S. Methods for integrating moderation and mediation: A general analytical framework using moderated path analysis[J]. Psychological Methods, 2007, 12(1): 1-22.
[44]Preacher K J, Curran P J, Bauer D J. Computational tools for probing interactions in multiple linear regression, multilevel modeling, and latent curve analysis[J]. Journal of Educational and Behavioral Statistics, 2006, 31(4): 437-448.
[45]MacKinnon D P, Lockwood C M, Hoffman J M, West S G, Sheets V. A comparison of methods to test mediation and other intervening variable effects[J]. Psychological Methods, 2002, 7(1): 83-104.
[46]Willett J B, Sayer A G. Using covariance structure analysis to detect correlates and predictors of individual change over time[J]. Psychological Bulletin, 1994, 116(2): 363-381.
[47]Engel U, Gattig A, Simonson J. Longitudinal multilevel modeling: A comparison of growth curve models and structural equation modeling using panel data from Germany[C]//Montfor K V, Oud J, Satorra A. Longitudinal Models in the Behavioral and Related Sciences. New Jersey: Lawrence Erlbaum Associates, 2007: 295-312.
教育频道,考生的精神家园。祝大家考试成功 梦想成真!
经济学
面板研究中的多层线性模型应用述评
http://www.newdu.com 2018/3/7 《管理科学》(哈尔滨)2011年3期第111~120页 郑昱 王二… 参加讨论
Tags:面板研究中的多层线性模型应用述评
责任编辑:admin相关文章列表
没有相关文章
[ 查看全部 ] 网友评论
没有任何评论