三、Tobit模型的估计Ⅰ:非联立方程模型
1.Tobit模型的MLE。1974年之前的文献对Tobit模型的估计都是采用了MLE,这种方法的特点是估计过程比较复杂,计算相当繁琐,而且需要选择一个合理的初始值,但是用这种方法估计出来的结果具有较好的性质,估计值的有效性较好。Tobin(1958)采用MLE,并给出选择初始值的方法,Heckman(1974)将Tobit模型扩展成联立(simultaneous)系统方程,沿袭了Tobin(1958)及Gronau(1974)的MLE。
Tobin(1958)关注了被解释变量有下限、上限或者存在极限值这类问题的研究,后来人们把具有这种特征的问题研究的模型称为Tobit模型。Tobin认为受限因变量的重点主要有两个方面,一是受限因变量和别的变量之间的关系,另一是这种关系的假设检验问题。在这样的问题的研究中,解释变量不仅影响受限变量的概率,也影响非受限因变量的规模大小。对于这类问题,如果不考虑非受限因变量的解释,而是只考虑受限因变量或是非受限因变量的概率问题,那么Probit分析就能提供一个合适的统计模型;如果不关注观测值的限制性,只是要解释某些变量,多元回归分析也是一种合适的统计技术。不过,当因变量的信息是有用的时候,丢失这些信息显然会使得研究丧失效率。Tobin以不同家庭的不同行为选择问题为例,建立了如下受限因变量模型。
假设W是受限因变量,具有下限L:

根据一阶条件公式,带入初始值运用牛顿迭代法计算,这就是著名的“得分法”,迭代直到Δa的值的变化非常小时,得到的估计值就是受限因变量模型的估计值。Tobin选择的初始值是函数-Z(x)/Q(x)的线性近似值,也可以说是lnQ(x)的二次方程的近似值。为了研究这类模型的特点,Tobin用1952年和1953年的数据对耐用品的支出问题进行了分析,目的是探求耐用品支出与年龄及流动性资产持有之间的关系。

2.Tobit模型的Heckman两步法估计。
1974年以后对Tobit模型的估计方法不再以MLE为核心进行突破,而是对Heckman两步法不断扩充和改进,主要是因为Heckman两步法计算比较简单,而且估计的结果是一致的,也无须考虑初值的问题。但是两步法的估计效率不如MLE,且这种估计方法要求两个方程的解释变量不能完全相同。Heckman(1976)介绍了两步法的推导过程,并证明了两步法的估计性质,以及应用两步法需要注意的问题。Amemiya(1974)将Tobit模型扩展到多变量模型,推导了模型估计方法。
Heckman(1976)对样本选择、截断、受限因变量等统计模型做了一个概括性的分析,扩展了Gronau(1974)和Lewis(1974)等的研究成果,证明了文中所提到的估计方法的应用环境、估计值的性质等。Heckman指出审查(censored)数据模型和截断(truncated)的区别在于截断数据不能使用有用的数据估计有完整数据的观测值的概率,但是审查数据可以。受限因变量模型需要考虑选择性偏差的影响,样本选择性偏差问题的研究最初起源于Gronau(1974)和Lewis(1974)关于工资选择偏差问题的研究,把未出现在工资方程中的额外的变量引起的工资率的变化称为选择性偏差。如劳动工资方程中,婚姻状态、小孩数量等虽然不是工资率的直接解释变量,但这些因素影响了工作选择的决定,因而通过限制性条件的方式对受限变量产生了选择性偏差。在实证部分Heckman用美国33-44岁女性的纵向(longitudinal)调查数据研究了女性工资率及工作时间的问题。


Amemiya(1974)将截断(truncated)因变量的单方程回归模型扩展到多变量方程模型和联立方程模型,提出了一个简单的可计算的一致估计法。对这类模型的研究主要集中于三个方面:一是参数值及协方差的估计;二是考虑估计值的一致性及有效性;三是渐进分布的推导用于对估计值进行假设检验。
对于多变量回归方程模型,假设n维随机变量:
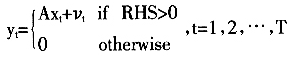
Amemiya为了解决上述三个核心问题,对多变量回归模型作了如下假设:
假设1:参数空间是紧致的并且是一个具有真实值的开邻域。


四、Tobit模型的估计Ⅱ:联立方程模型
联立方程Tobit模型估计方法与非联立Tobit模型有较大的区别。这种模型估计涉及到两个问题,一是如何判断所建立的方程是否是联立方程的问题。Lee(1978)明确提出了检验的方法。二是如何估计模型的问题,以往研究文献提出了不同的估计方法,总体上来说这些估计方法都是将联立方程估计方法与Heckman两步法估计方法结合的结果,但是各文献中具体估计方法之间是存在差异的。
Amemiya(1978)建立了多变量联立方程模型,模型基本结构如下:

与以往的受限因变量联立方程模型不同,Amemiya的模型中考虑了只有部分因变量受限的联立方程模型的估计方法、估计性质以及识别条件的问题。
Amemiya指出要识别结构式模型,需要作如下几点假设:
假设5:Γ的每个主子式最小值是正的。

Amemiya(1979)认为FMLE(完全极大似然法)求解Tobit模型太耗成本而且估计结果往往是最不可行的。Amemiya提出了求解联立方程Tobit模型的一致性估计值的广义最小二乘法(GLS)方法。作者在文中主要比较了普通最小二乘值、Nelson & Olson(1977)估计值、广义最小二乘估计值、Heckman估计值等几种估计值的方法以及估计值的效率的问题。
Nelson & Olson(1977)的联立方程模型的基本结构如下:

当审查或者截断的两方程模型含有内生变量时,这种模型就具备了一般联立方程模型的特征,文中计算估计值以及渐进方差、协方差很直接,但是渐进方差、协方差的计算难度随着方程个数的增加而增加。对于联立方程Tobit模型,先计算简化式再计算结构式得到的参数估计值,比间接最小二乘估计法得到的估计值更有效。
Lee(1976)主要关注了受限因变量模型的两阶段估计的问题,论文主要围绕着两个问题展开分析:一是寻找一致的初始估计值的问题;另一个问题是寻找估计模型的更简单一些的估计方法。Lee提出用工具变量法估计模型,用全部样本代替子样本估计模型,这个方法在简单的受限因变量模型中一方面可以获得好的一致的初始值,计算也比较简单,但是如果是复杂模型,该方法的计算量将非常大。包含内生变量的迭代模型与非市场均衡模型是转换回归模型的一种,Lee建议对后四种模型采用两阶段估计法。具有联立结构的转换回归模型假定转换取决于潜在条件:可以实现样本分割。因变量是截断数据的多变量联立方程模型的估计方法,与Amemiya(1974)的间接最小二乘估计法不同,对每种类型模型采用两阶段最小二乘法进行估计,计算比较方便,也容易解决模型的过度识别问题,模型的识别条件沿用了Amemiya(1974)中的结论。Lee将这一方法用于分析工资率的问题,比较了两阶段最小二乘法与间接最小二乘法,发现用修正后的OLS估计简化式方程的两阶段最小二乘法得到的估计值,比较恰当地反映了各影响因素对受限因变量的作用。
Lee(1978)研究了受限变量模型估计在住房需求中的应用问题,这篇文章的主要目的有两个:一是推荐一个获得某类受限变量模型的较好的初始估计值的方法,另一个是证明这种模型和估计技术如何被用于研究住房需求问题。

在实证部分,Lee(1978)将需求面的参与主体分成租房者和买房者两大类,分析中低收入者住房需求问题。政府对公共住房的政策分两个方面,公共住房及FHA补贴的贷款是对供给面的调控,住房补贴及转移支付是对需求面调控。中低收入者住房需求问题的分析要研究的实际上是两个问题,第一个问题是购买或是租住的选择问题,第二个问题是支出多少的问题,对这类问题分析的关键在于确定模型是联立方程还是非联立方程,并选择恰当的估计方法。Lee(1978)用购房支出量、租房支出量、选择买房还是租房作为因变量,以家庭支柱者(年龄、种族、性别)、家庭背景(移动、家庭持久收入、家庭规模)、区域性变量(城市规模、距离中心城区的距离)、房屋的相对价格作为解释变量。Lee(1978)指出检验模型是否是联立方程的统计量是似然比率

Lee(1978)认为在一般情况下,受限因变量使用Heckman两步法在一般情况下可以得到一致估计量,在这个估计量的基础上,得到的两步法极大似然估计(2SML)值是渐进有效的。买方或者租房的问题不同于以往样本选择模型,因为要考虑模型是否存在联立性的问题。理论证明和实践结果都表明,2SML法在标准误以及解释波动方面的效果很好,经验结论与经济理论也很吻合。
Lee(1979)介绍了具有离散和连续内生变量的一般联立方程的统计模型,这种模型可以被看成是转换联立方程模型的新形式,建议使用一些简单的二阶段方法估计模型,并证明了这些估计值的一致性问题。
Lee(1979)的联立方程不同于Tobin(1958)、Heckman(1974)、Nelson(1976)的受限因变量模型,主要区别在于Lee(1979)的方程中考虑了选择方程中含有内生变量的情况。模型基本结构为:

该系统方程中的误差项序列相互独立,具有0均值和协方差矩阵∑。


2SML得到的估计值是一致的,协方差矩阵∑也可通过方程之间的关系式估计出来。
Lee(1999)分析了动态Tobit模型、具有自回归条件异方差(ARCH)或者广义条件异方差(GARCH)的扰动项的Tobit模型在时间序列中的仿真(simulation)估计问题。激励Lee研究这类问题的经济活动,如政府对商品、金融股票、外币市场的干预活动,防止价格跌得低于某个水平,或者涨得高于某个水平,变量的动态行为也可能受限。
对这类模型的估计,Lerman & Manski(1981)建议使用仿真(simulation)极大似然估计(SML),McFadden(1989)建议使用仿真矩估计法(MSM),Hajivassiliou & McFadden(1990)建议用仿真得分法(simulation scores)、Gourieroux & Monfort(1993)建议采用仿真伪极大似然法(pseudo-maximum likelihood),McFadden(1989)提出了SML估计值(SMLE)。
基本模型如下;


Lee(1999)详细介绍了似然仿真法(likelihood simulation)在Tobit ARCH(p)、Tobit GARCH(p,q)及动态Tobit模型估计中的应用,也分析了方差递减以及在似然仿真中可能出现的数值下溢的问题,用蒙特卡洛(Mente Carlo)实验验证了SL法在这三种估计模型中的效果。似然仿真中的方差递减技术可用于具有重建性质的模型中,而长时间的序列样本中可能出现似然仿真中的数值下溢问题,用公式
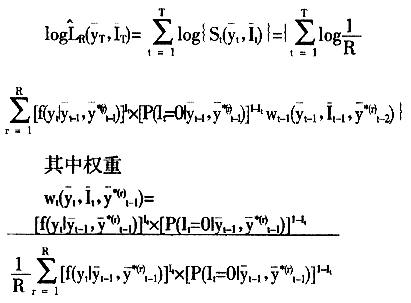
避免数值下溢问题。
Lee的研究结果表明,对于动态自回归Tobit模型,SMLE方法比Laroque & Salnie(1993)推荐的SPML方法要准确和好得多,用SL方法估计的SMLE对仿真所取的数据的变化不敏感。ARCH Tobit、GARCH Tobit的回归方差中的系数值是可以完全被估计出来的,但是方差方程中的参数的SMLE估计值是存在偏差的,而且GARCH Tobit模型中的方差方程无法估计出来。
Blundell & Smith(1994)分析了联立受限因变量模型及联立定性变量模型的估计和推断问题,文章的主要目的是寻求这种非线性模型的唯一的隐含的简化式的一致性条件,将审查或者分组的联立方程模型称为Type IIS的联立模型。


(未完待续)