【内容提要】
本文以罗默提出的R&D模型的知识生产函数为基础,根据科技统计数据估计中国的知识生产函数;并将实证结果与国外的相关研究进行比较,最后给出了提高中国知识生产率的建议。
【关 键 词】内生经济增长/研究与开发/知识生产函数/向量自回归模型/协整
中图分类号:F204文献标识码:A
一、理论模型的设定
知识生产函数是描述新知识的产出和投入要素之间关系的数学表达式,在不同的知识生产函数中,新知识的生产依赖现有知识存量的程度是有差异的,这样知识跨时期溢出对研究人员的作用也不相同,由此得出的长期均衡关系和相关的政策含义也不相同,本文以文献研究中广泛采用的知识驱动模型(Romer(1990)、Rivera-Batiz和Romer(1991)提出)为基础进行研究。Romer(1990)的知识驱动模型包括四个变量,产出(Y)、资本(K)、劳动(L)和技术(A),经济中有三个生产部门:研究部门使用人力资本和知识存量进行新产品设计;中间产品部门向研究厂商购买生产新产品的专利权,利用新产品设计和其他投入品生产中间产品;最终产品部门利用中间产品、人力资本和劳动生产消费品。在这个模型中,假定经济中的劳动者总数(L)不变,劳动者可以自由地进入研究部门和最终产品部门,设生产部门的劳动者为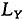
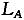
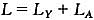

这里δ为生产率参数,方程式(2)是知识生产方程,这个方程有两个含义:一个是知识战技术的增长率与研发部门的劳动者人数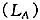

上述研究表明,新知识的产生依赖于现有的知识存量和研发部门的劳动者人数,新知识的增长率与现有知识的增长率和研发部门劳动者人数的增长率存在稳定的长期关系,而知识的增长率和研发部门劳动者人数的增长率具有长期的稳定关系。(6)式和(9)式是对中国知识生产函数实证研究的理论基础,在进行实证研究时,要选择合适的变量对新知识、现有的知识存量以及研发部门的劳动者人数进行测度。对于新知识的测度采用专利申请量(注:专利申请量来测度创新活动在文献中被广泛使用,如Hansman, Hall and Griliches(1984)、Kortum(1997)、 Griliches(1989,1990)和Joutz and Gardner(1996)认为相对于R&D支出来说,专利申请量是更好的测量新知识的指标,原因是R&D支出是新知识产生的投入要素,而专利申请量是新知识产生的产出。)这个指标,而知识存量的测度需要利用专利申请量的数据,根据一定的折旧率进行估算。在研究的文献中,Jones(
二、中国知识生产函数的协整检验
(一)数据的来源及处理
考虑到我国科技统计数据的实际情况,本文以我国1987~2003年的全要素生产率、知识存量和专利申请量以及R&D人员为样本,对中国知识生产函数进行实证研究。对于专利申请量和R&D人员直接可以从中国科技统计网(注:中国科技统计网的网址:http: //www. sts. org.cn。)中的《中国主要科技指标数据库》获得,但知识的存量和全要素生产率要采用一定的方法进行测算。这里知识存量采用永续盘存法(注:永续盘存法估算知识存量的公式是: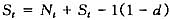
(二)实证模型的设定
考虑k阶向量自回归模型:

(三)单位根检验
变量的平稳性是建立时间序列模型的重要前提,在进行模型回归之前有必要对模型的前提假设进行检验,否则,对非平稳性的时间序列直接进行回归,可能出现“伪回归”问题。时间序列的单位报检验方法较多,代表性的方法有DF检验、ADF检验、PP检验、KPSS检验和NP检验,并且采用不同的检验方法,可能得出不同的检验结果。本文采用常用的ADF法检验全要素生产率(TFP)、知识存量增长率(KSR)和专利申请量增长率(PR)以及R&D人员增长率(RDR)的单整阶数。
从表1可以看出,ADF检验结果表明,水平项没有一个变量是平稳的;一阶差分后所有变量在5%的显著性水平下均是平稳的。因此;在5%的显著性水平下,所有变量都服从I(1)过程。
(四)协整分析
时间序列变量的单整和协整性质决定了专利申请量、R&D人员和知识存量(或全要素生产率)间的模型形式。如果时间序列变景之间是协整的,那么方程(6)和方程(9)应该树看作平任期均衡关系,否则只能作为一种短期关系来解释。由于四个变量均服从I(1)过程,因而可以考察它们之间的协整关系,即变量间的长期关系。本文采用Johansen方法对四个变量进行协整检验,在检验过程中,根据 AIC和SC准则,选择合适的向量自回归阶数。检验结果见表2和表3。
表1变量单位根的检验结果
变量ADF检验统计量 1%的显著性水平5%的显著性水平TFP -2.792(c,2)-4.011-3.100水KSR -1.623(c,3)-4.137-3.148平PR-1.511(c,3)-4.068-3.122项RDR -2.689(c,2)-4.068-3.122一TFP -5.080(c,2)-4.011-3.100阶KSR -3.512(c,3)-4.137-3.148差PR-4.338(0,2)-2.776-1.970分RDR -6.037(c,1)-4.068-3.122 |
注:括号里的第一个字符表示检验的类型(0:不含常数项,c:含常数项;t:含线性趋势),
第二个字符表示滞后的阶数。
(1)专利申请量、R&D人员和知识存量的协整检验:
表2变量间的协整关系检验结果
零假设 特征值 检验统计量 临近值 结论5%的显著性水平 1%的显著性水平r≤0 0.93466.989 29.68 35.65 拒绝r≤1 0.84828.919 15.41 20.04 拒绝r≤2 0.1652.5183.76 6.65 接受 |
从表2可以看出,Johansen迹统计检验结果表明,在5%的显著性水平下,专利申请量、R&D人员和知识存量之间存在两个协整方程,这两个协整方程形式如(13)对式和(14)式所示:
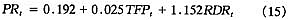
协整方程(13)表明知识存量增长率每增加1%,专利申请量增长率增加0.453%,研究与开发的劳动者增长率增加1%,专利申请量增长率增加0.792%。这两个系数完全符合模型的理论含义,其中系数0.453表明在现存知识下,研发部门的生产率是递增的,知识存在溢出效应,知识存量会带来新知识的发现;而系数0.792表明研发存在复制或模仿的“踩脚尖”效应,即研发部门的人员增加1倍。新的知识并没有随之增加1倍。协整方程(14)表明研究与开发的劳动者增长率增加1%,知识存量增长率增加1.297%,系数1.297在合理的区间之内,说明实际的协整关系符合理论模型的含义。从这两个协整方程的参数估计值可以看出,针对中国的实际数据,中国的知识生产函数与Jones(1995b)假定的形式非常符合,但不是Romer(1990)假设的知识生产函数形式。
(2)专利申请量、R&D人员和全要素生产率的协整检验:
表3变量间的协整关系检验结果
零假设特征值 检验统计量临近值 结论 5%的显著性水平 1%的显著性水平r≤0 0.944940 54.14390 29.6835.65拒绝r≤1 0.435767 13.55333 15.4120.04接受r≤2 0.326863 5.541287 3.76 6.65- |
从表3可以看出,Johansen迹统计检验结果表明,在5%的显著性水平下,专利申请量、全要素生产率和R&D人员之间存在一个协整方程,这个三个变量的长期均衡方程如(15)所示:
协整方程(15)的结果表明全要素生产率每增加1%,专利申请量增长率增加0.025%,研究与开发的劳动者增长率增加1%,专利申请量增长率增加1.152%。全要素生产率的系数0.025表明在现存知识下,研发部门的生产率是递增的,知识存在溢出效应,知识存量会带来新知识的发现;而系数1.152不符合Romer(1990)知识驱动模型中的参数含义。协整方程(15)表明用全要素生产率测度知识存量可能是不合适的,而从方程(13)可以看出,根据专利申请量这个指标构建知识存量还是比较合适的。符合Jones(1995b)模型中的知识生产函数的理论含义。
三、结论和建议
知识生产函数是基于R&D的经济增长模型的核心,其描述了知识生产率与知识存量和从事R&D活动的劳动者之间的关系,新知识则知识存量的弹性就是知识溢出的程度,不同程度知识溢出的假设,就会得出不同的长期经济增长关系和政策含义。程度大的知识溢出假设意味着长期的经济增长依赖于 R&D补贴等政策变量的变化,而程度小的知识溢出假设意味着长期的经济增长不随R&D政策变量的变化而改变,这对研究中国经济增长和知识生产率都具有重要的意义。在一些微观的实证研究文献中, R&D活动具有不同种类的溢出形式,主要有市场溢出、网络溢出和知识溢出等等,本文没有考虑市场溢出、网络溢出,分析局限在宏观层次的知识溢出,只是以Romer(1990)知识驱动模型为基础,采用协整技术研究中国知识生产函数的参数值以及知识溢出的程度,研究的结果表明,中国的知识溢出程度不高,新知识才知识存量的长期弹性只有0.453,对从事R&D劳动者的弹性是0.792,但与世界发达国家的研究是一致的,如Kortum(1993)研究的专利和R&D的比率时,得出知识溢出系数估计值在0.1~0.6之间,Yasser Abdih(2002)得出的美国的知识生产函数中的知识溢出系数为1.3,其研究结果支持Romer(1990)模型中的知识生产函数的参数假设,但本文的研究结果表明中国的生产函数符合Jones (1995b)模型中提出的知识生产函数形式,而不符合Romer(1990)模型中的知识生产函数形式。另外,当采用全要素生产率测度知识存量时,得出的参数估计值不符合理论模型的实际含义,说明使用全要素生产率测度知识存量可能不太合适,而专利申请量还是一个比较合适的指标,得出的计量结果比较令人满意。
上述研究结果表明,中国的生产函数符合Jones(1995b)模型中提出的形式,在这个模型中,新知识产生的决定要素是现有的知识存量和从事R&D的劳动者,而经济系统的均衡路径是经济增长率和各要素的增长率都等于从事R&D活动的劳动者的增长率,这样均衡的经济增长率和知识生产率都取决于 R&D人员的增长率,与其他的政策变量无关。在这个经济系统中,R&D人员是新知识生产的重要条件,是生产率提高和经济增长的内在动力,对发达国家经济增长的长期统计资料表明,R&D人力资本投资的扩大,是发达国家经济增长越来越重要的源泉,当知识取代了劳动和物质资本在生产和再生产中的地位,知识的生产扩散和应用成为经济增长的核心和动力时,拥有现代知识和知识生产能力的劳动者将是推动经济增长的原动力,因此,政府应加强R&D人力资本投资,使其不断获取新的知识,加快新技术的发展,实现中国经济增展方式的彻底转变。
【作者简介】吕忠伟袁卫中国人民大学统计学院,北京100872