王晓军/蔡正高CCWANG Xiao-jun CAI Zheng-gao
【内容提要】
20世纪后半叶以来,世界范围内,人口死亡率整体上呈现下降趋势。而依据传统死亡模型对死亡率的预测往往高于实际水平,这给养老金财务安排和养老年金的成本核算带来了严重的不利影响。本文沿着死亡率模型的发展轨迹,回顾和总结了各类死亡率预测模型,对死亡率预测模型的最新进展做出评述,并对中国死亡率预测模型的选取给出了建议。
【关 键 词】确定型死亡率模型/随机死亡率模型/小波转换
引言
在世界各国,依据过去经验数据和模型对未来死亡率做出的预测大多低于实际结果。死亡率的降低和预期寿命的延长,特别是死亡率的非预期性降低,给养老金制度安排和养老年金财务核算带来无法预期的财务压力。死亡率预测作为养老金财务规划的基础,对政府养老金制度、雇主职业年金、保险公司的团体和个人养老金业务等都有重要的影响,关系到各类养老计划的财务安全和可持续发展。
本文回顾和总结了各类死亡率预测模型,对死亡率预测模型的最新进展做出评述,同时对中国死亡率预测模型的选取给出了建议。
一、确定型死亡率模型

其中:A,B,C,D,E,F,C,H为参数,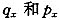
这些确定型模型,从参数假设出发,依据死亡率的经验数据确定参数,没有考虑未来死亡率变动的不确定性,因此一般只用于对死亡率数据的拟合,很少用于外推。近20年来陆续有学者提出不同的随机死亡率模型,并用于对未来死亡率的预测。
二、离散时间随机死亡率模型
在死亡率预测方面,大多数的研究和实际工作都建立在对年度死亡率数据统计分析的基础上,依据统计分析,预测未来的死亡率。最近的一些研究也采用了P-样条函数(惩罚样条函数)的方法以及离散时间市场模型的方法预测死亡率。
一般地,统计部门公布的死亡率数据是年度分年龄死亡率。因此,在预测中往往也直接预测分年龄的死亡率。t年(x)分年龄死亡率定义为,
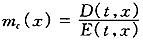
其中:D(t,x)表示(x)在日历年t的死亡人数;E(t,x)表示在日历年t的(x)平均人数(暴露)。有些研究也直接根据调查数据计算分年龄的死亡概率q(t,x)(日历年t刚好(x)在t+1之前死亡的概率)。分年龄死亡率和死亡概率有如下近似关系,
q(t,x)=1-exp[-m(t,x)] |
或者:
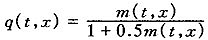
下面将介绍几种常用的离散时间随机死亡率模型。
(一)Lee-Carter模型
Lee-Carter(1992)模型如下:
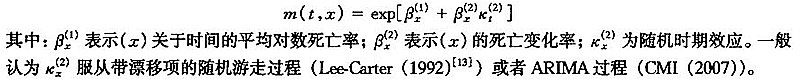
该模型参数的估计有很多方法。最早的方法是Lee-Carter在1992年文章中提出的。后来又有不少学者提出一些统计方法(Delwarde等(2007)[11]、Czado等(2005)[8]、Brouhns等(2002)[3])。这些方法都尽量拟合历史数据,考虑对所有经验数据的拟合优度。也有的方法(Lee-Miller(2001)[12])侧重对最近年份数据的拟合优度。Lee-Miller认为死亡率模型的主要用途是预测未来的死亡率,因此.最近年份的数据对未来的影响更大。他们建议选取最近年份
还有一些学者试图改进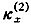
Lee-Carter模型被广泛用于死亡率预测,但应该指出,Lee-Carter模型本身存在一定缺陷。首先,模型是单因素的,结果是各个完全相关年龄的死亡率都会改变。其次,通常用(x)平均死亡变化率来测度年龄效应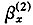

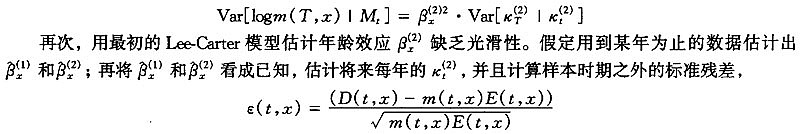
如果模型本身和参数估计方法都正确,那么ε(t,x)应该是独立同分布的并且近似标准正态分布。初步数据分析表明:如果年龄效应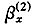
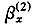
Lee和Miller(2001)[12]验明了Lee-Carter模型在预测中的偏差问题,并且提出了基本的解决方案。Brouhns等(2002)[3]提出的统计方法假定,死亡人数D(t,x)为独立的Poisson随机变量,均值和方差都等于m(t,x)E(t,x),其中,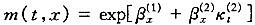
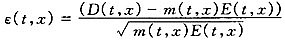
Lee-Miller方法只是改善了短期预测的偏差问题,但对长期死亡率预测的统计性质很差。
(二)多因素年龄-时期模型
近些年来,有学者提出了多因素死亡率模型。Renshaw和Haberman(2003)[14]提出的模型为,

在实际数据模拟中,Renshaw-Haberman模型表现出来的稳健性较差。CMI(2007),Cairns(2007)都指出用于拟合模型的年龄范围的变化会导致一系列参数估计值的本质区别;他们还认为缺乏稳健性与似然函数的形状有关,稳健模型的似然函数可能只有惟一的最大值,这个值不会随着用于拟合模型的年龄范围的变化而改变。而缺乏稳健的模型,似然函数可能不止一个最大值。
(四)Cairns-Blake-Dowd队列效应模型
Cairns等(2008)注意到Renshaw-Haberman模型中拟合队列效应的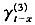

(五)P-样条函数(惩罚样条函数)模型
近年来,在英国比较常用的一种方法是采用惩罚样条函数(P-Spline)方法(CMI(2006)[6]、Currrie等(2004)[7])。常见的模型如下,
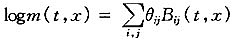
其中: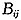
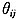
(六)CMI(1999)模型
该模型的主要研究对象是英国60岁以上的退休公务人员。基于英国死亡率变动比较平稳的实际,在未来发达的医疗条件和完善的社会福利制度下,假设未来死亡率改善幅度下降的趋势趋于平缓,提出了下面的模型。
g(t+k,x)=q(t,x)·R(t+k,x) |
其中:t表示基础年;q(t,x)表示t年时,x岁的人在未来一年内的死亡率;q(t+k,x)表示t年时,x岁的人在t+k年时的死亡率;R(t+k,x)表示t年为基础年,x岁的人在t+k年时的死亡率改善幅度,R(t+k,x)具体的表示如下,
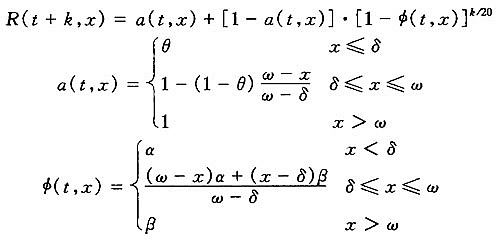
这里:ω表示生命表的极限年龄;a(t,x)表示根据基础年死亡率在x岁时的比率下限;φ(t,x)表示对x岁的人来说,根据过去20年经验得出的所有死亡率下降的百分比;0<θ<1,0<α<1,0<β<1。
该模型的计算不是很复杂:先选定一个基础年,计算各年的R(t+k,x);再用非线性回归方法以及误差最小平方和原则计算各参数值,代入模型即可求出各年龄的调整因子R(t+k,x);进而估计各年龄组未来的死亡率。当k→+∞,模型会趋近于死亡率改善幅度的下限a(t,x)。
这一模型因其自身的背景关系,应用的范围较小。对于发展中国家来说,死亡率依旧在改善,可能一开始死亡率改善幅度下降的速度比较快,后来会趋于平缓。基于这种情况,台湾学者郑汉卿[16]提出了一个用于拟合台湾死亡率的改进版CMI(1999)模型:
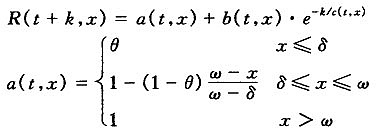
这里:a(t,x)表示根据基础年死亡率在x岁时的比率下限;k(t,x)表示死亡率下降的比率;c(t,x)表示死亡率改善幅度曲线平缓的趋势。
该模型运用离散小波转换(wavelet transform)对各年龄组的死亡率改善幅度进行多维度分解,分成低频和高频两部分,同时预测趋势线和随机振幅部分,趋势线影响低频部分,高频部分完全是平均数为0的随机项,再找出死亡率改善的近似函数,最后提供了预测的置信区间。这个模型对发展中国家的死亡率预测有很大的借鉴意义。
三、连续时间随机死亡率模型
在连续时间随机死亡率模型中,大多数研究关注短期死亡率模型(short-rate)。近期,一些学者也提出了类似远期利率模型以及市场利率模型的连续随机死亡率模型。Cairns-Blake-Dowd(
(一)短期死亡率模型
连续时间的短期死亡率模型是比较成熟的新型模型。一般形式如下,
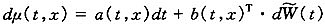
其中:a(t,x)为漂移项,b(t,x)为n×1维向量,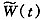
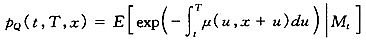
Dahl和Mφller(2006)[9]提出了一个单因素模型,并引入死亡率改善因子的概念将未来的死亡率和当前的死亡率联系起来。形式如下,
μ(t,x+t)=μ(0,x+t)·ξ(t,x+t) |
其中:ξ(t,x+t)为死亡率动态改善因子,满足下式
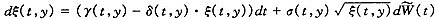
(二)远期死亡率模型结构
该模型主要是仿照Heath,Jarrow和Morton(1992)提出的远期利率模型。模型的一般形式如下,
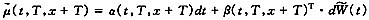
其中:α(t,T,y)为标量,β(t,T,y)为n×1维向量,
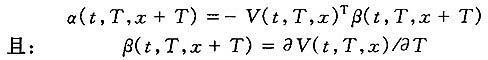
连续时间的随机死亡率模型有自身独特的背景,比较符合实际。但必须选择那些在生物学上能够解释的带跳过程来模拟,这也是今后的研究方向。
四、对中国死亡率模型选取的建议
对于死亡率模型的选择,Cairns,Blake和Dowd(
依据这些基本标准,对中国人口死亡率数据进行分析,可以判断中国死亡率模型的选择。
中国人口统计年鉴(1995~2007年)提供了从1994年到2006年的分年龄人口死亡率数据。
60岁以上每个年龄组的死亡率都有不同程度的下降,但60~64、65~69、70~74、75~79年龄组的变化幅度不大,而80岁以上组死亡率变化却呈现不同程度的跳跃过程。因此,直观的分析,可以用Lee-Carter模型进行模拟,并用ARIMA模型来拟合其随机时期效应。同时,考虑到中国在过去20多年经济一直处于转型期,贫富不均明显,城乡医疗卫生条件差异显著,可能导致死亡率的波动,因此,可以尝试基于小波转换的随机死亡率改善幅度建模。基于篇幅有限,有关中国死亡率预测模型的讨论将另辟专文。
【参考文献】
[1]Antolin P. Longevity Risk and Private Pensions[J]. OECD Working Paper on Insurance and Private Pensions, 2007.
[2]Booth H., Maindonald J., Smith L. Applying Lee-Carter under Conditions of Variable Mortality Decline[J]. Population Studies, 2002, 56:325-336.
[3]Brouhns N., Denuit M., Vermunt J. K. A Poisson Log-linear Regression Approach to the construction of Projected Life Tables[J]. Insurance: Mathematics and Economics, 2002,31:373-393.
[4]Cairns A. J. G., Blake D., Dowd K. Pricing Death: Frameworks for the Valuation and Securitization of Mortality risk[J]. ASTIN Bulletin,
[5]Cairns A. J. C., Blake D., Dowd K. A Two-factor Model for Stochastic Mortality with Parameter Uncertainty: theory and Calibration[J]. Journal of Risk and Insurance, 2006b, 73:687-718.
[6]Continuous Mortality Investigation(CMI) Stochastic Projection Methodolosies: Further Progress and P-Spline Model Features, Example Results and Implications[J]. Working Paper20, 2006.
[7]CurrieI D.,
[8]Czado C., Delwarde A., Denuit M. Bayesian Poisson Log-linear Mortality Projections[J]. Insurance: Mathematics and Economics, 2005,36:260-284.
[9]Dahl M., Mφller T. Valuation and Hedging of Life Insurance Risks with Systematic Mortality Risk[J]. Insuranse: Mathematics and Economics, 2006, 35:193-217.
[10]De Jong P., Tickle L. Extending the Lee-Carter Model of Mortality Projection[J]. Mathematical Population Studies, 2006,13:1-18.
[11]Delwarde A., Denuit M., Eilers P. Smoothing the Lee-Carter and Poisson Log-bilinear Models for Mortality Forecasting: a Penalized Log-likehood Approach[J]. Statistical Modeling, 2007,7:29-48.
[12]Lee, R. D., Miller T. Evaluating the Performance of the Lee-Carter Model for Forecasting Mortality[J]. Demograhy, 2001,38:537-549.
[13]Lee, R. D., Carter, L. R. Modeling and Forecasting
[14]Renshaw, A. E., Haberman, S. Lee-Carter Mortality Forecasting with Age-specific Enhancement[J]. Insurance: Mathematics and Economics, 2003,33:255-272.
[15]Renshaw, A. E., Haherman, S. A Cohort-based Extension to the Lee-Carter Model for Mortality Reduction Factors[J]. Insurance: Mathematics and Economics, 2006, 38:556-570.
[16]郑汉卿.动态死亡率改善幅度模型之研究.逢甲大学硕士论文.^
【原文出处】《统计研究》(京)2008年9期第80~84页
【作者简介】王晓军,女,1963年生,山西人,中国人民大学统计学院风险管理与精算学专业教授,博士生导师,中国人民大学统计学院副院长、风险管理与精算中心主任。研究方向为保险精算,社会保障,养老金。
蔡正高,男,1980年生,安徽安庆人,中国人民大学统计学院风险管理与精算学专业2007级博士,天津财经大学统计学院讲师,研究方向为寿险精算,风险管理。