摘要:运用统计学相关原理与数据挖掘的理论和方法,对电信套餐资费动态预演中新增客户量(新入网选择新套餐的客户)与转移客户量(网内转移至新套餐的客户)的预测展开研究。对于新增客户量,可基于相似套餐的历史数据进行时间序列法预测;对于转移客户量,可通过数据挖掘工具学习新套餐推出后用户选择的规则,由此预测转移客户量。最后,以某地市电信套餐为例进行实例分析,分别使用线性回归分析法与指数平滑法建立新增客户量预测模型,并对两种方法进行比较分析,使用数据挖掘中的决策树算法对客户转移规则进行挖掘。
关键词:电信资费预演,客户量预测,线性回归分析,指数平滑法,决策树算法
1引言
随着电信市场的规范化管理和用户市场的多元化发展,运营商之间的市场竞争日益激烈,传统的价格战、赠送式促销等策略已无法满足新的市场需求,套餐营销愈发受到运营商的青睐。为了抢占市场先机,吸引更多的新客户,提高经营业务收益,电信运营商会不失时机地推出新业务套餐。然而,经过一段时间的运营,发现某些新推出的套餐市场反映平淡,给企业造成了损失。因此,在新套餐推向市场前,通过对该套餐进行科学有效的预演,估计其推出后的用户数量、成本、收益等情况,并据此及时调整套餐,能够大大减少套餐推出的营销风险,提高市场竞争力。
本文聚焦于电信套餐资费动态预演方法这一难题,运用统计学相关原理与数据挖掘的理论和方法,对电信套餐资费动态预演中新增客户量与转移客户量的预测展开研究,文章研究成果对于提高电信套餐资费动态预演的科学性、减少业务套餐的营销风险、提高电信企业的业务收益具有重要的理论意义和实用价值。
2相关研究
电信业务资费预演是国内外电信运营商都比较关注的热点问题,如何有效地利用数据挖掘方法对新套餐进行预演是目前数据挖掘应用的一个非常热门且具有重要应用价值的研究课题[1]。
参考文献[2]中采用“逆向思维”,先把用户按品牌分群,在分群的基础上,使用关联规则算法,发现群中用户的消费规律,根据规律制定相应套餐,使得新套餐刚推出时就能符合细分市场的规律,在套餐总数受限的前提下,能有效避免盲目性,减小企业风险。参考文献[3]提出了一个电信套餐预演的整体分析模型,并结合某市联通公司的套餐数据对此模型进行了应用分析,验证了该模型的有效性。参考文献[4]详细介绍了中国移动辽宁公司经营分析系统平台的资费预演功能的方案设计和实现细节,提出了确定参与预演用户、确定参与预演数据、后台重新计费以及后台展示折损和估损等一系列的设计思路,实现了基于企业数据仓库——经营分析系统海量业务数据的资费预演。参考文献[5]对资费预演系统的建设作了整体的介绍,并融合其他系统给出了资费预演系统的功能框架,从功能模型与技术实现上指出了构建电信行业资费预演系统的关键要素,同时还对资费预演系统的市场发展前景作了大胆的预测,提出了资费预演系统的3步发展规划。参考文献[6]认为经营分析系统提供的资费预演功能,可以帮助使用方在推出新资费政策前了解新资费可能造成的估损,同时根据该估损调整使用方的资费政策和营销计划,对经营分析系统中资费预演子系统的构建提出了完整的系统用例模型。
综上所述,目前关于电信套餐资费预演的研究大都比较关注预演指标的分析,而对预演环境的研究则主要局限于静态预演,即都假定客户消费行为不变,按照客户理性选择原则构建资费预演的环境,能够有效实现资费动态预演的研究几乎没有。虽然有一些网络文献报道资费预演系统已经在部分中国移动分公司进行了实施,但是由于相关理论研究没有跟上,其系统功能难免会受到质疑。
3电信套餐资费预演的理论基础
电信业务资费预演,就是通过模拟新套餐推出后的真实环境,采用多次演化的方法决策出使企业整体效益最大的资费水平,为新套餐设计、套餐资费定价等环节提供科学、准确的参考依据,并最终为电信运营商推出更符合市场需要、更吸引客户的新套餐提供有效的决策支持。根据在预演时所作的关于用户消费行为等因素的不同假设,可分为静态预演和动态预演。其中,静态预演是在假定用户消费行为不变的条件下,用户按照理性选择原则对待新套餐资费,若使用新套餐收益为正值,则其将会按照理性选择原则选择新资费套餐而放弃原有套餐;动态预演则是考虑到新资费推出后带来的各方面影响,包括对客户量的影响(客户是否发生转移,哪些客户发生转移,客户的转移规则如何)以及对客户消费行为的影响(客户受到新资费的刺激,是增加还是减少业务的使用量),从而更科学地预测新套餐推出后企业客户量与业务量的变化。
本文以实现动态预演为目标,重点是对新套餐推出后可能发生的客户量的预测方法研究。在此,根据电信行业的特点,将新套餐的可能客户分为两类:新增客户(新入网选择新套餐的客户)与转移客户(网内转移至新套餐的客户)。
3.1新增客户量预测思路
新增客户量的预测,目前可行的方法主要有两种。
第一种是基于套餐等级与客户群细分预测新套餐的新增客户量。具体步骤为先预测电信运营商在一段时期内的新增用户客户总量,利用数据挖掘工具对以往发生的新增客户群进行客户细分,找到各种客户群体对应的套餐等级,从而找到细分后的客户群与套餐种类的对应关系,计算相应的不同群体选择不同套餐的系数矩阵,最终求得新套餐的新增客户量。
第二种是基于相似套餐预测新套餐的新增客户量。首先找出与要推出的新套餐最相似的已有旧套餐,并且有效计算新套餐与已有旧套餐的相似度,通过预测旧套餐在未来某段时期内的新增客户量计算新套餐推出后可能发生的新增客户量。
由于第一种方法需要对运营商目前所有的套餐划分等级,还需要在客户细分的基础上,将新增客户划分为不同的群体,并且需要计算出不同客户群体选择不同套餐的系数矩阵,方法较为复杂。因此选择第二种方法,根据已有的相似套餐的历史数据采用时间序列法预测其未来可能发生的新增客户量,然后通过已有旧套餐与新套餐的相似度计算,得出新套餐的新增客户量。
3.2转移客户量预测思路
客户发生网内转移的影响因素有很多,套餐资费、促销力度、客户消费能力、客户消费历史、客户消费习惯等,都会在一定程度上左右客户是否选择套餐转移,而且其中的很多因素均很难量化,因此要想百分之百完全准确地预测客户转移行为,几乎是不可能的。
从另一方面,客户的历史消费数据与客户是否发生转移有较强的相关性,如南京电信“我的e家”129套餐额定的每月上网时长是180h,超出额度按1.2元/h收取,那些每个月使用宽带超过300h的用户自然比每月使用180h的用户更有可能发生升档(即转移至档次更高的套餐),而那些使用不超过100h的用户自然也有更高的概率发生降档(即转移至档次更低的套餐)。通过挖掘这些发生套餐转移的规则,有助于分析新套餐在推出后可能有哪些已有套餐的客户转移过来。因此,选择的方法是根据历史数据学习新业务推出后用户选择的规则,在提取大量客户历史消费数据的基础上,使用数据挖掘方法,发现客户发生套餐转移的规则,由此预测新套餐的转移客户量。
转移客户量预测的基本思路为:首先找出与新套餐相似程度较高的套餐,记为套餐A、B、C、D等,然后利用数据挖掘中的决策树算法,发现相似套餐A的客户转移至相似套餐B、C、D等的规则,利用此规则判断由相似套餐A可能转移至新套餐的客户;在执行完相似套餐A转移规则的分析之后,需要对相似套餐B进行相同的分析,再对相似套餐C、D等进行分析,直到将所有的相似套餐都推演完毕,从而得到从已有相似套餐转移至新套餐的客户量。
4实例分析
本文实例基于某地市电信运营商计划于2011年推出“我的e家”e8套餐的下一代产品,新套餐的相似套餐为e8套餐(包含的子套餐有e8-88、e8-118、天翼宽带家庭版-38、天翼宽带家庭版-68)。根据§3.2对两种客户量的预测思路,新套餐在推出后一段时期内的新增客户量可以通过e8套餐客户量预测模型得出,其基本公式为:新套餐的新增客户量=e8套餐的新增客户量×套餐相似度。因此,本实例中主要建立e8套餐在未来一段时期内的新增客户量预测模型。另外,新套餐的转移客户量预测模型可通过对e8套餐的各个子套餐客户消费数据进行挖掘,发现客户转移规则,由此预测新套餐转移客户量,本实例中以e8-88套餐为例进行客户转移模型的构建(其余相似子套餐的转移模型构建类似,故在此不再赘述)。
4.1新增客户量实例
4.1.1数据准备
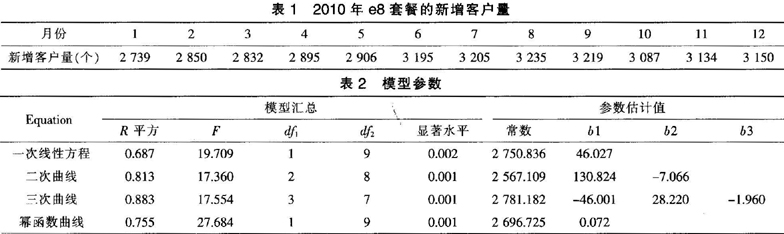
为了有效预测新增客户量,提取某地电信运营商2010年的“我的e家”e8套餐的新增客户量数据,新增客户量见表1。
从表1可以看出,该地运营商e8套餐1~5月新增用户数比较稳定,6~9月有一个较大幅度的提升,10~12月又回落到之前的水平,经了解,该地运营商于暑期推出了一系列的办理e8套餐的优惠活动,促进了新增客户量的增长。
4.1.2结果分析
为了使预测结果更为准确,使用线性回归预测法与指数平滑法分别建立模型,并以12月份的数据为例,比较两种模型得出的预测值与实际值的误差率,验证两种模型的适用性。
(1)线性回归预测法
由于e8套餐的新增客户量数据没有体现简单的线性关系,实验中用多种线性与拟线性模型(一次线性(Linear)方程、二次曲线(Quadratic)、三次曲线(Cubic)以及幂函数曲线(Power))进行拟合,找出拟合度最高的模型。模型参数见表2,拟合结果如图1所示。
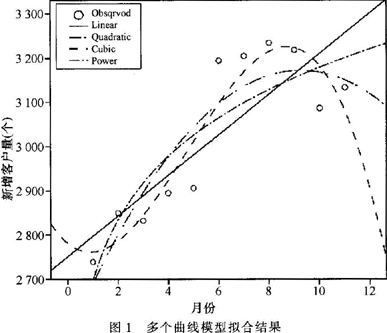
由图1可以看出,Cubic的决定系数为0.883,为所选模型中最高,即拟合程度最佳,故采用三次曲线模型作为该地运营商e8套餐新增客户量的回归预测模型。对此三次曲线模型的回归方程作详细求解,结果见表3。
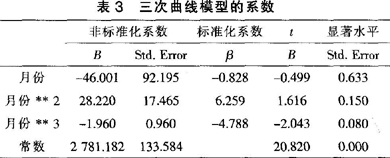
可得三次曲线模型为:
y=2781.2-46x+28.2x2-1.96x3(1)
由式(1)可得,新增客户量为y(12)=2903,即e8套餐第12月的新增客户量为2903个。
(2)指数平滑法
首先利用SPSS工具建立简单指数平滑预测模型,设置平滑指数取值范围为0~1,以0.1为单位,找出最优平滑指数(MSE为最小),结果见表4。
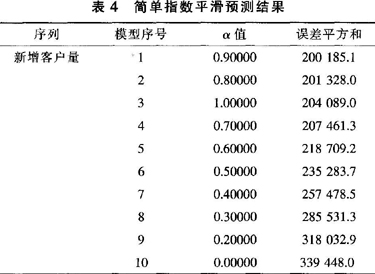
从表4可以看出,当a=0.9时,模型的异方差均值(mean of the squared errors,MSE)为最小,也就是拟合点与实际点之间的距离差的平方和最小,模型排名(model rank)列在第一,即a=0.9为最优平滑指数。其模型方程为:
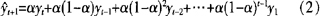
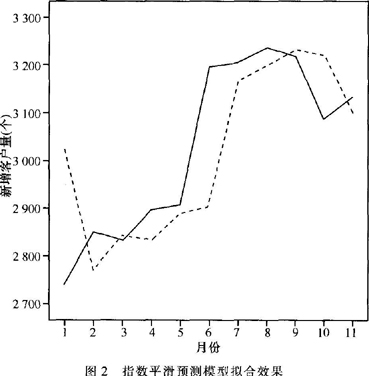
其中,a=0.9。其拟合效果如图2所示。
从图2可以看出,简单平滑指数基本可以反映新增客户量随时间序列的变化趋势。根据式(2)可得出12月的e8套餐新增客户量为3130个。
4.1.3模型解释
根据§4.1.2的实验结果,12月的e8套餐新增客户量用两种方法预测出来的结果并不一致:预测值(线性回归法)=2903个,预测值(指数平滑法)=3130个。通过引入变量预测值与实际值的误差率,判断两种方法对这部分统计变量的适用程度。误差率的定义如下:
误差率=(预测值—实际值)/实际值×100%
计算可得:
误差率(线性回归法)=(2903-3 150)/3 150×100%=7.8%;
误差率(指数平滑法)=(3 130-3 150)/3 150×100%=0.006%。
由此可看出,指数平滑法比线性回归预测有更加出色的性能,其模型的拟合程度较好,对12月份的预测值相对更准确。通过比较,发现两种模型都有一定的局限性。
(1)采用线性回归法预测新增客户量,要求统计变量与时间变量有比较强的线性(或拟线性)关系,否则,较难得到准确的预测。此次实验样本中的新增客户量,由于在7、8月份有运营商促销,其呈现出随时间变化增加、减少再增加的趋势,其曲线较为复杂,因此没有得到最理想的拟合结果。
(2)采用指数平滑法预测新增客户量,主要是要求统计变量总体有很强的时间序列性,体现与时间序列之间一定的规律性,并且历史数据越多,得到的预测模型越准确。如果样本中历史数据较少,则不宜采用此方法。
4.2转移客户量实例
4.2.1数据准备
由于本研究以e8-88套餐为例进行其客户转移规则挖掘,因此提取2010年12月留存的e8-88套餐客户以及在12月由e8-88套餐转移到其他相似套餐的客户在2010年的消费数据作为基础数据,分别为客户基本信息表(主要包含客户编号、套餐ID、入网时间等基本属性)、宽带产品消费数据表(包含产品编号、上网时长、接收流量与发送流量等属性)与固话产品消费数据表(包含产品编号、通话时长、通话日期等属性)。
为了使数据更能反映客户的消费特点,从而保证挖掘出的转移规则的有效性,引入两个中间变量:消费趋势与套餐匹配度。
消费趋势主要反映用户近期的消费倾向,其基本公式定义为:消费趋势=近3个月消费均值/全年消费均值。在宽带产品方面,针对时长、接收数据、发送数据变量,分别引入中间变量:宽带_时长趋势、宽带_接收趋势、宽带_发送趋势;在固话产品方面,分别引入固话_通话次数趋势、固话_通话时长趋势。
套餐匹配度主要反映客户消费额与套餐额度的匹配情况,其基本公式定义为:套餐匹配度=消费均值/套餐额。由此可以看到,套餐匹配度越接近“1”,则该客户的消费与套餐的额度越吻合,理论上客户因此发生套餐转移的概率就越小。套餐匹配度也可分为“近期匹配度”与“全年匹配度”,为了简化不必要的变量对模型带来的干扰,最终只引入中间变量“近期匹配度”,其公式为:近期套餐匹配度=近期消费均值/套餐额。在本实例中,e8-88套餐最主要的额度就是宽带时长,所以最终需要引入的中间变量为“宽带_近期匹配度”。
通过使用SQL Server工具进行数据清洗并进行表的连接,最终模型选择的输入变量包含了固话与宽带两方面的消费数据,其中,固话产品包含固话_呼叫次数、固话_呼叫次数趋势、固话_通话时长、固话_通话时长趋势,宽带产品包含宽带_费用、宽带_费用趋势、宽带_时长趋势、宽带_近期匹配度、宽带_接收、宽带_接收趋势、宽带_发送、宽带_发送趋势。模型选择输出变量为变量DATA_FLAG,此变量只有两个值:转移与未转移。
4.2.2结果分析
将准备好的数据导入数据挖掘软件Clementine 12.0,选取C5.0算法,生成决策树模型,结果如图3~5所示。

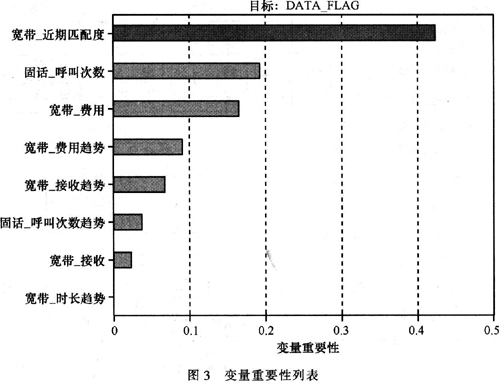
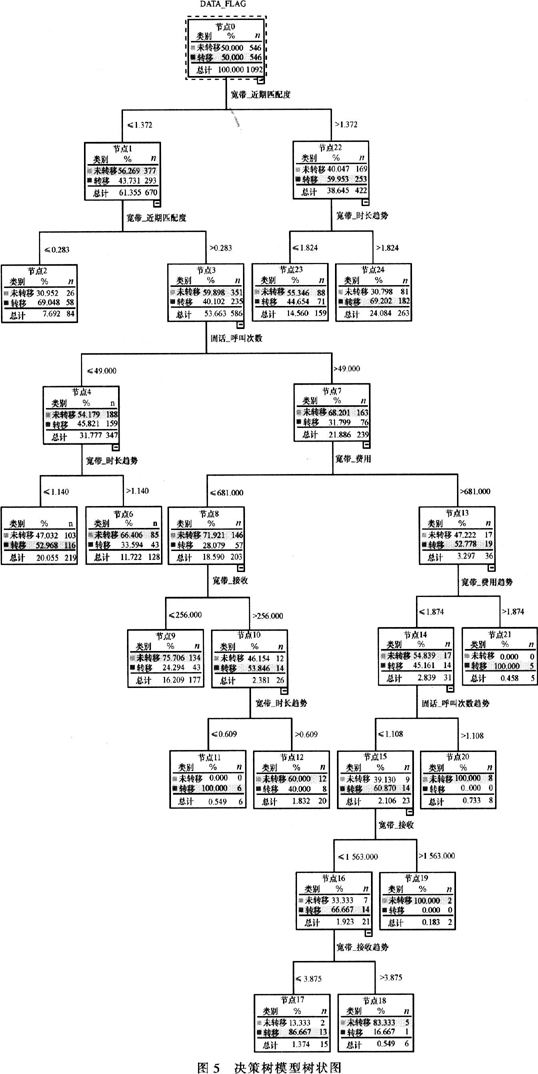

从图3~5可以看出,生成的树状图深度为8级,变量“宽带_近期匹配度”、“固话_呼叫次数”、“宽带_费用”是对模型影响最大的3个变量。从图4、图5可以看出,决策树模型还是较为显著的,也得到了预期的结果。
4.2.3模型解释
在决策树模型中,树状图比规则集更加直观。结合图5得到以下有益的客户转移规则,见表5。
从表5中最终得出了4条显著而且健康的转移规则,主要与两个变量有关:宽带_近期匹配度与宽带_时长趋势。这两个引入的中间变量,主要反映了客户近期对宽带产品的使用情况,那些近期使用宽带较多的客户很可能将现有套餐升级至宽带时长档次更高的套餐(从规则1与规则5可以得出),反之,则很可能将现有套餐降低至宽带时长档次更低的套餐(从规则3可以得出),而那些消费情况变化不大的客户则有很大的可能性保持现有套餐不变。
从另一个方面看,全年消费均值对客户的套餐选择行为影响比较小。这也与实际情况相符合,全年消费均值无法反映客户近期消费需求的变化,而在实际过程中,客户套餐发生转移通常都是由消费需求变化引起的。
根据§4.2.2得到的决策树模型,如果新套餐宽带时长额度大于e8-88套餐,则有60%的可能吸引近3个月宽带时长均值大于82h的客户;如果新套餐的宽带时长额度小于e8-88套餐,则有69%的可能吸引近3个月宽带时长均值小于17h的客户。这两部分客户都可以作为新套餐可能发生的转移客户量,至于那些转移规则不明显的客户,可在实际运用中设置一定的参数,基于一定的抽样策略将这部分客户抽取出来,从而最终形成e8-88套餐可能转移至新套餐的客户群。
5结束语
本文从电信套餐资费预演的基本理论出发,在对前人的研究文献进行学习综述的基础上,指出电信套餐资费动态预演的重点在于科学地测算新套餐推出后可能发生的客户量,然后将新套餐的可能客户分为两种类型:新增客户与转移客户,分别讨论两类客户的预测方法。
在新增客户量预测方面,分别使用了时间序列预测法中的线性回归法与指数平滑法建立模型对客户量进行预测,并对两种方法进行比较,分析其预测结果的准确性与各自的适用情况。在转移客户量预测方面,结合具体的套餐客户消费数据,利用数据挖掘中的决策树算法,发现客户转移规则,并据此对新套餐可能发生的转移客户量进行预测。
由于本研究中提取的数据样本有限,建立的预测模型还有许多不足之处,需进一步完善与验证。总之,希望本文对新套餐客户量预测方法的探讨,能够对电信运营商未来的资费动态预演有充分的参考价值。
*国家科技支撑计划资助项目(No.2007BAH17B04)
参考文献
1 Hung Shin Yuan, Yen’David C, Wang’Hsiu Yu. Applying data mining to telecom churn management. Expert Systems with Applications, 2006, 31(3):515~524/2 马季兰.基于决策树分类算法和Apriori算法的数据挖掘在电信行业的应用研究.太原理工大学硕士学位论文,2008
3 刘永、陈治平.数据挖掘在电信套餐预演中的应用研究.计算机工程与设计,2008,29(15):4032~4039
4 魏磊.经营分析系统资费预演设计与实现.现代通信,2007,9(10):34~38
5 雷柏先.电信行业资费预演系统建设论.http://soft.ccw.com. cn/engineering/htm2007/20070605_267996.shtml
6 李文广.基于数据挖掘技术的经营分析系统.山东大学硕士学位论文,2005
(作者:南京邮电大学经济与管理学院 贾丹华 王润润 中国移动通信集团公司江苏有限公司南京分公司 王鹏)