内容提要:将自组织数据挖掘理论引入贝叶斯分类中,提出一种新颖的贝叶斯分类器结构学习算法。算法将基于依赖分析和评分搜索两种贝叶斯网络结构学习思想相接合,根据互信息测度值选择初始模型,用贝叶斯评分作为筛选中间模型的外准则,能够在不同数据集上完成自适应建模过程,包括选择进入模型的变量、确定具有最优复杂度的模型结构等。在10个UCI数据集上进行分类测试,结果表明,贝叶斯分类器结构学习算法分类器的分类精度要高于常用的朴素贝叶斯、树扩展朴素贝叶斯以及基于K2算法的分类器。进一步地,在信用卡客户分类数据集german上的学习曲线和抗干扰试验还表明,与朴素贝叶斯、树扩展朴素贝叶斯以及K2等分类器相比,贝叶斯分类器结构学习算法分类器具有更加稳定的分类性能和更强的抗干扰能力。
关键词:贝叶斯分类器 结构学习 自组织数据挖掘 客户分类
作者简介:肖进(1983-),男,四川广安人,四川大学工商管理学院博士研究生,研究方向:数据挖掘及建模、客户关系管理等(成都610064)
引言
分类技术是数据挖掘中最有应用价值的技术之一,被广泛应用于机器学习、模式识别等各个领域。近年来,随着客户关系管理的兴起与发展,对客户分类方法也提出了更高的要求,探索新的分类方法、不断提高分类精度意义十分重大。目前,常用的分类技术有决策树方法、遗传算法、神经网络等,随着朴素贝叶斯(Na ve Bayes,NB)的发现及其不断发展,贝叶斯网络(Bayesian Network,BN)[1]已成为强有力的分类工具,它以其坚定的理论基础、自然的知识表示方式、灵活的推理能力和方便的决策机制受到越来越多的重视[2,3]。
ve Bayes,NB)的发现及其不断发展,贝叶斯网络(Bayesian Network,BN)[1]已成为强有力的分类工具,它以其坚定的理论基础、自然的知识表示方式、灵活的推理能力和方便的决策机制受到越来越多的重视[2,3]。
一、文献评述
目前,国内外很多学者对贝叶斯分类器进行了深入而又细致的研究。Duda等提出了朴素贝叶斯结构[4],NB因其简洁性以及不可思议的良好分类性能受到极大关注,NB的不足在于忽略了各属性节点之间的依赖性,为此人们提出了很多改进方法。Friedman等提出了树扩展朴素贝叶斯(tree augmented Na ve-Bayes,TAN)结构[5],各个属性节点之间形成最大扩展树结构;Cheng等提出贝叶斯网络扩展朴素贝叶斯(BN augmented Na
ve-Bayes,TAN)结构[5],各个属性节点之间形成最大扩展树结构;Cheng等提出贝叶斯网络扩展朴素贝叶斯(BN augmented Na ve-Bayes,BAN)结构[6]。这些都是贝叶斯网络结构较好的扩展,但仍有不足之处,如TAN分类器在NB的基础上生成一个最大扩展树结构,允许所有变量进入分类器,从而也将数据集中可能存在的冗余变量引入模型中[7]。文献[8]已经证明,当模型中包含冗余的预测变量时会损害其分类精度。BAN允许属性间的联系编码为贝叶斯网络,对表示属性之间的联系十分有利,但其结构学习一般存在搜索空间大、计算复杂、容易陷入局部最优解等问题[9]。
ve-Bayes,BAN)结构[6]。这些都是贝叶斯网络结构较好的扩展,但仍有不足之处,如TAN分类器在NB的基础上生成一个最大扩展树结构,允许所有变量进入分类器,从而也将数据集中可能存在的冗余变量引入模型中[7]。文献[8]已经证明,当模型中包含冗余的预测变量时会损害其分类精度。BAN允许属性间的联系编码为贝叶斯网络,对表示属性之间的联系十分有利,但其结构学习一般存在搜索空间大、计算复杂、容易陷入局部最优解等问题[9]。
上述贝叶斯分类器之间最大的不同在于它们的结构学习算法[10]。理论上,为找到与真实系统完全相符的网络结构,有必要准确地了解它的数学输入-输出关系。然而,在缺乏对系统了解的情况下,要建立准确的数学模型是非常困难而且不容易处理的。相反,软计算模型关注于不精确系统上的近似估计问题[11],它在解决复杂非线性系统的识别和控制问题时表现出了很好的能力,因而受到极大的重视。常用的软计算方法有粗糙集、模糊逻辑、神经网络等,已有学者将神经网络与贝叶斯分类相结合,构建了贝叶斯神经网络分类器[12]。神经网络用于分类有很多优点,但也有其不足之处,如建模过程需要建模者反复调试[13]、容易产生过拟合[14]等。在各种软计算方法中,自组织数据挖掘(self-organize data mining,SODM)是一种启发式自动建模技术[15],于1960年由Ivakhnenko提出,是多变量分析的复杂系统建模和识别方法。SODM方法能根据外准则和终止法则找到最优复杂度模型,自动完成建模过程,包括自动选择进入模型的变量、自动确定多层SODM网络的层数等[16]。因此,利用SODM学习贝叶斯分类器的结构,可以在很大程度上弥补TAN分类器可能存在的变量冗余问题、神经网络容易产生的过拟合和需要反复调试以及TAN分类器容易陷入局部最优解等不足。近年来,SODM方法在工程、科学、经济等领域都得到了成功的应用[15~21]。
本研究在已有贝叶斯分类器的基础上,将SODM方法引入贝叶斯分类中,提出一种新颖的贝叶斯分类器结构学习算法GMBC(Bayesian classification based on GMDH),并根据算法构建GMBC-BDE分类器。GMDH(group method of data handing,GMDH)是数据分组处理方法,它是SODM的核心技术;BDE(Bayesian dirichlet equivalent,BDE)是贝叶斯评分。
二、贝叶斯结构学习
通常,贝叶斯网络的结构学习有两类方法,一类是基于依赖分析的方法,另一类是基于评分搜索的方法。后一种方法应用得更普遍,该方法将结构学习看做是一个最优化问题。这类算法需要定义一个评分来描述每个可能的模型与观测数据集的拟合度,贝叶斯评分是较为常用的评分函数[22]。

在定义了评分函数之后,贝叶斯网络的学习问题就变成了一个搜索问题,通过搜索算法寻找具有最佳评分的网络结构,这是一个NP难题。通常采用启发式搜索方法,如爬山法、模拟退火法等。但由于搜索空间太大,往往会导致学习效率较低,且容易陷入局部最优结构。
三、SODM的基本原理
SODM的核心技术是数据分组处理方法,它是一种进化计算技术,从参考函数出发,通过遗传、进化、变异、选择和拒绝等一系列操作,决定系统模型的输入变量、结构以及参数,并最后通过终止法则选择最优模型[23]。在GMDH中,组合算法(单层算法)和多层算法(GMDH多层神经元网络)是两种最重要的算法,GMDH多层神经元网络的应用更为广泛[16]。
GMDH以参考函数的形式建立输入输出变量之间的一般关系。一般取Volterra函数级数或Kolmogorov-Gabor多项式[17]的离散形式作为参考函数,即

GMDH算法将观测样本数据分为训练集和测试集,在训练集上利用内准则(最小二乘法)进行参数估计得到中间待选模型(遗传、变异),在测试集上利用外准则进行中间候选模型的选留(选择)。其终止法则是由最优复杂度原理给出的,即当模型的复杂度逐渐增加时,具有外补充性质的称之为外准则的准则值会呈现先减小后增大(或先增大后减小)的变化趋势,外准则全局极小值(或极大值)对应最优复杂度模型[23]。此外,当训练样本数据存在噪声时,利用GMDH的外准则能找到一个具有最优复杂度的非物理模型[16],与一个完全的物理模型相比,它的预测能力更高,结构更简单。而且随着噪声水平的增加,GMDH更倾向于选择结构比较简单的非物理模型。因此,在训练样本数较少或训练样本含有较高水平噪声的情况下,GMDH也能得到很好的结果[18]。如果能适当地选取初始模型,GMDH可使许多领域的建模过程更客观,如本研究的初始输入模型是只含有一条边的贝叶斯网络结构。
四、GMBC-BDE分类器的构建
用GMDH多层神经元网络进行贝叶斯分类器的结构学习,必须选择适当的外准则评价中间待选模型,而BDE评分函数正好可以用来评价贝叶斯网络模型。同时,为保证算法的收敛性,作为GMDH的外准则还应该满足最优复杂度原理,为此有如下命题。
命题1将BDE评分作为GMBC算法的外准则,随着贝叶斯网络复杂度(边)的增加,其外准则值(BDE评分)将先增大后减小,存在一个全局极大值。
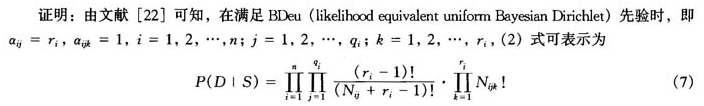
进一步地,
容易证明,对于网络中每一个节点而言,随着 的增加,也即节点i的父亲节点的增加,
的增加,也即节点i的父亲节点的增加, 的值将先增大后减小,总存在一个最大值。特别地,对于只能作为根节点的节点,它本身的评分已经达到最大,当为其增加父亲节点时,其评分将不断减小。
的值将先增大后减小,总存在一个最大值。特别地,对于只能作为根节点的节点,它本身的评分已经达到最大,当为其增加父亲节点时,其评分将不断减小。
在用BDE评分作为GMDH的外准则学习贝叶斯分类器的结构时,从GMDH网络的初始层开始,每一层都由贝叶斯模型两两组合,得到若干个待选的中间模型,然后将各待选模型中最大的BDE评分作为该层的外准则值,根据 的性质可知,这样做能使算法的外准则值不断增加,直到每个
的性质可知,这样做能使算法的外准则值不断增加,直到每个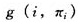 的值达到最大,从而外准则值也达到最大值,此时若进一步增加贝叶斯网络的复杂度,其外准则值必将减小,从而命题得证。
的值达到最大,从而外准则值也达到最大值,此时若进一步增加贝叶斯网络的复杂度,其外准则值必将减小,从而命题得证。

互信息值越大,两个节点之间的依赖性越强,其间存在边的可能性越大,则选择包含该条边的初始模型的可能性就大。
GMBC算法利用GMDH多层神经元网络学习贝叶斯分类器结构,将基于依赖分析和评分搜索两种结构学习思想相结合,用互信息测度两两变量之间的依赖关系并作为选择初始模型的依据,用BDE评分作为筛选中间模型的外准则,并根据准则值的大小筛选若干较优的模型进入下一层操作,重复这样一个组合、评分、选择的过程,直到得到具有最优复杂度的贝叶斯网络结构(见图1)。算法的输入是样本数据集D以及n个变量之间的顺序(确定变量之间顺序的方法有很多,这里采用文献[24]的方法),输出是具有最优复杂度的贝叶斯网络模型,具体步骤如下。

步骤6选择前 个评分最大的模型进入GMDH网络的下一层,将k个模型两两组合,得到新的待选模型,在测试集上计算每个待选模型的BDE评分并按大小排序,将最大的评分作为该层的外准则值,同时令t=k,更新t值;
个评分最大的模型进入GMDH网络的下一层,将k个模型两两组合,得到新的待选模型,在测试集上计算每个待选模型的BDE评分并按大小排序,将最大的评分作为该层的外准则值,同时令t=k,更新t值;
步骤7重复步骤6,直到根据最优复杂度原理找到最优复杂度网络模型。

注:黑体字是该数据集上的最高分类精度。
五、实验分析
(一)分类器分类精度分析
为集中研究结构学习问题,本研究假设没有数据的缺失,因此对于有数据缺失的数据集需要预先对其进行处理。对于连续属性的缺失值以其未缺失值的均值代替,而对于离散属性,则取众数(在一系列观测数据中出现次数最多的值)来代替。同时,对于连续属性,本研究采用Fayyad等的方法进行预离散化[25]。
实验使用的数据集从UCI(University of California in Irvine)下载[26],文章选取了其中的10个标准数据集,利用GMBC-BDE算法学习得到各分类器结构,并结合样本数据进行参数学习和推理。参数学习采用BDeu先验[22],先验值取1,推理算法采用Self-important随机模拟算法。全部实验通过matlab 6.5编程实现,准确性评估采用10层交叉验证方法(CV10)和保留方法,训练集和测试集的划分与数据集已有的划分方式完全一致,其评估结果用分类准确率表示,实验结果见表1。GMBC-BDE是本研究构建的分类器,K2是基于K2结构学习算法构建的分类器,NB和TAN分别表示朴素贝叶斯分类器和树扩展朴素贝叶斯分类器。
从表1可以看出,在10个实验数据集中,GMBC-BDE分类器在german、monk2、pima和vehicle上具有最高的分类精度,而另外3种分类器分别只是在2个数据集上具有最高分类精度。具体来看,GMBC-BDE分类器在breast-cancer、chess等8个数据集上的分类精度要高于K2分类器,在vehicle、wine等8个数据集数据集上的分类精度高于NB分类器,GMBC-BDE分类器分类精度在7个数据集(如german、zoo)上也优于TAN分类器。因此,本研究构建的GMBC-BDE分类器的分类性能要优于另外3种分类器。
(二)各分类器稳定性及抗噪能力分析
为进一步分析各分类器的稳定性,选取其中的german数据集进行试验。german是一个著名的关于客户信用卡的数据集,该数据集共有1000个客户的样本信息,包含20个属性变量和1个类变量,其中有7个数值型属性变量,13个定性变量,类变量有2个不同的状态,相应地将全部的客户划分成两类,即信用好的客户和信用差的客户。同时,该数据集还引入了一个分类成本矩阵,即假设分类正确的成本为0,将一个信用好的客户归为信用差的客户的成本为1,而将一个信用差的客户归为信用好的客户的成本为5。本研究仍采用10层交叉验证方法(CV10)进行分类实验,每次从800个训练样本中随机抽取100,200,…,800个样本进行结构学习和参数学习,在余下的200个样本上进行分类测试,其结果见图2。
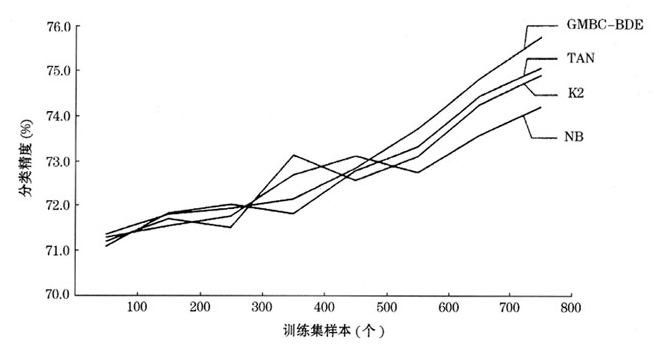
图2german数据集上的学习曲线

图3german数据集上的抗噪声实验
图2是数据集german的学习曲线,其结果是取20次实验结果的平均值。从图2可以看出,随着训练集中样本数的增加,4种分类器的分类精度在总体上都是逐渐上升的。但它们之间又存在很大的差异,对于GMBC-BDE分类器而言,其分类精度是随着训练集样本的增加而不断上升,中间没有出现大的波动;而其他3种分类器,特别是K2分类器,则存在较大的波动。这表明,GMBC-BDE分类器较之其他3种分类器具有更好的稳定性。
同时,现实中的分类数据大多含有较高水平的噪声,因此研究分类器的抗噪声能力十分重要。在数据集german的训练集中加入一定水平的随机噪声,再分别利用GMBC-BDE、K2、NB和TAN分类器进行分类实验,在每一噪声水平下反复实验20次,取平均值作为最终分类结果,其实验结果统计如图3。从图3可以看出,随着噪声水平从0%逐渐提高到20%,各分类器的分类精度均在下降,但是下降速度却并不相同。总的来说,K2和TAN分类器分类精度下降较快,其次是NB分类器,而GMBC-BDE下降得最慢。随着噪声水平的提高,分类精度下降速度越快,表明其对噪声越敏感、抗干扰能力越弱。这从一个侧面表明GMBC-BDE分类器具有较强的抗干扰能力。
六、结论
本研究在已有贝叶斯分类方法的基础上,提出基于SODM的贝叶斯分类器结构学习算法。在10个UCI数据集上进行分类测试,结果显示,与已有的一些方法(如K2、NB、TAN)相比,GMBC-BDE分类器具有较高的分类性能。进一步地,在著名的信用卡客户分类数据集GMBG-BDE分类器具有较强的稳定性和german上进行了稳定性和抗噪声能力测试,表明GMBC-BDE分类器具有较强的稳定性和抗噪声干扰能力,为客户分类提出了一种新的方法。
同时,从表1还可以看出,GMBC-BDE分类器也不是绝对最优的,它只是在适合于该方法的数据集上表现出较好的分类性能,各种分类方法的分类结果具有很强的信息互补性。因此,考虑如何将上述各种不同分类器的分类结果进行融合,进一步提高分类精度和稳定性是后续的研究内容。
参考文献:
[1]J Pearl. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference[M]. Morgan Kaufmann, 1988.
[2]Z C Qin. Naive Bayes Classification Given Probability Estimation Trees[C]//Proceedings of the 5th International Conference on Machine Learning and Applications(ICMLA), 2006:34-42.
[3]G Peter, L John. Suboptimal Behavior of Bayes and MDL in Classification under Misspecification[J]. Machine Learning, 2007,66(223):119-149.
[4]R O Duda, P E Hart. Pattern Classification and Scene Analysis[M]. New York: John Wiley & Sons, 1973.
[5]N Friedman, D Geiger, M Goldszmidt. Bayesian Network Classifiers[J]. Machine Learning, 1997,29(2):131-163.
[6]J Cheng, R Greiner. Learning Bayesian Belief Network Classifiers: Algorithms and System[C]//Proceeding of the 14th Biennial Conference of the Canadian. Society on Computational Studies of Intelligence: Advances in Artifical Intelligence, 2001:141-156.
[7]A Perez, P Larranaga, I Inza. Supervised Classification with Conditional Networks: Increasing the Structure Complexity from Naive Bayes[J]. International Journal of Approximate Reasoning, 2006,43(1):1-25.
[8]P Langley, S Sage. Induction of Selective Bayesian Classifiers[C]//Proceedings of the 10th Conference on Uncertainty in Artificial Intelligence, 1994:399-406.
[9]D M Chickering. Learning Bayesian Networks Is NP-complete, Learning from Data: AI and Statistics V[M]. New York: Springer, 1996:121-130.
[10]J G Li, C S Zhang, T Wang, Y M Zhang. Generalized Additive Bayesian Network Classifiers[C]//International Joint Conference on Artificial Intelligence (IJCAI), 2007:913-918.
[11]E Sanchez, T Shibata, L A Zadeh. Genetic Algorithms and Fuzzy Logic Systems[M]. Singapore: World Scientific, 1997.
[12]M A Kupinski, D C Edwards, M L Giger, C E Metz. Ideal Observer Approximation Using Bayesian Classification Neural Networks[J]. IEEE Transactions on Medical Imaging, 2001,20(9):886-899.
[13]A P Alves da Silva, U P Rodrigues, A J Rocha Reis, L S Moulin. Neuro Dem——A Neural Network Based Short Term Demand Forecaster[C]//IEEE Power Technical Conference, Portugal, 2001:2-6.
[14]I Tassadduq, S Rehman, K Bubshait. Application of Neural Networks for the Prediction of Hourly Mean Surface Temperatures in Saudi Arabia[J]. Renewable Energy, 2002, 25(4):545-554.
[15]A G Ivakhnenko. Heuristic Self-organization in Problems of Engineering Cybernetics[J]. Automatica, 1970, 6(2):207-219.
[16]J A Mueller, F Lemke. Self-organising Data Mining: An Intelligent Approach to Extract Knowledge from Data[M]. Hamburg: Libri, 2000.
[17]M Iwasaki, T Shibata, N Matsui. GMDH-based Autonomous Modeling and Compensation for Nonlinear Friction[C] //Proceedings of the 1999 IEEWASME International Conference on Advanced Intelligent Mechatronics, 1999:860-865.
[18]贺昌政.自组织数据挖掘与经济预测[M].北京:科学出版社,2005.
He C Z. Self-organising Data Mining and Economic Forecasting[M]. Beijing: Science Publish, 2005.
[19]D B Fogel. An Introduction to Simulated Evolutionary Optimization[J]. IEEE Transaction Neural Networks, 1994,5(1):3-14.
[20]H Iba, H deGairs, T Sato. A Numerical Approach to Genetic Programming for System Identification[J]. Evolutionary Compute, 1996,3(4):417-452.
[21]A Darvizeh, N Nariman-Zadeh, H Gharababei. GMDH-type Neural Network Modeling of Explosive Cutting Processof Plates Using Singular Value Decomposition[J]. Systems Analysis Modeling Simulation, 2003,43(10):1383-1397.
[22]G F Cooper, E Herskovits. A Bayesian Method for the Induction of Probabilistic Networks from Data[J]. Machine Learning, 1992,9(4):309-347.
[23]A G Ivakhnenko, J A Muller. Problems of an Objective Computer Clustering of a Sample of Observations[J]. Soviet Journal of Automation and Information SciencesC/C of Avtomatika, 1991,24(1):54-62.
[24]J Cheng, D Bell, W Liu. Learning Belief Networks from Data: An Information Theory Based Approach[J]. Artificial Intelligence, 2002,137(122):43-90.
[25]U M Fayyad, K B Irani. Multi-interval Discretization of Continuous-valued Attributes for Classification Learning[C] //Proceedings of 13th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann, 1993:1022-1027.
[26]UCI Repository of Machine Learning Databases[DB/OL]. http://www.ics.uci.edu/~mlearn/MLRepository.html.