内容提要:全球信息技术的迅猛发展,以及由此引发的统计部门源头数据信息化采集改革,都对当前CPI价格数据采集提出了更高的要求。而扫描数据的出现,或许能够解决这一问题。与传统的人工价格采集方式相比,扫描数据在降低企业回答负担、减少人工采价而产生的测量误差等方面,有着显著的优势。但是,作为一种高频海量数据,扫描数据对现有的指数计算方法也提出了挑战。目前,各国利用扫描数据编制CPI的方法不尽相同,而新提出的RYGEKS指数可能会有更广阔的前景。笔者对上述方法进行了比较研究,以期为我国利用扫描数据编制CPI提供理论依据。
关键词:CPI/扫描数据/数据采集/RYGEKS指数作者简介:陈相成,男,河南省人,河南财经政法大学教授,硕士生导师,中国统计教育学会常务理事,河南省统计学会副会长,研究方向为经济统计;乔晗,男,河南省人,河南财经政法大学统计学专业在读研究生,研究方向为经济统计。
一、引言
随着全球互联网以及信息技术的发展,各国统计部门都在试图利用信息化手段采集源头数据。其中对于CPI价格数据的采集,各国政府统计部门遵循的基本原则是:在提高价格采集的准确率和效率的同时,最大限度地降低成本和减少企业的回答负担[1]。扫描数据的出现,可能使这一原则得到很好的体现。
所谓扫描数据,就是消费者在购物完成进行结算时,结算人员通过扫描设备对商品的EAN码进行扫描时所记录的数据。[2]由于扫描数据提供了诸如产品销量、产品特性和产品价值等相关信息,因此它可以在很大程度上扩大编制CPI的数据来源。从21世纪初开始,很多国家就开始研究如何利用扫描数据编制CPI。目前,荷兰、挪威和瑞士三个国家在编制本国CPI的过程中正式使用了扫描数据。对于扫描数据的潜力,世界各国的学者和统计部门已达成了广泛的共识(Feldmann,2012)[3]。
本文根据当前世界各国利用扫描数据的经验,分析了其优势和不足,对目前利用扫描数据编制CPI的基本步骤和计算方法进行了比较研究,并在此基础上介绍了RYGEKS指数在扫描数据中的应用,以期为我国利用扫描数据编制CPI提供理论依据。
二、扫描数据的优势和局限性
(一)优势
扫描数据作为一种新的源头价格数据和传统的人工采集方式相比,具有以下优势:
第一,扫描数据提高了源头数据采集质量。扫描数据使得所有商品的价格及其销售数量等信息都可以非常详细和准确地得到,主要表现在以下几个方面:①可以在很大程度上增加代表规格品的数量;②价格调查的频率得到了极大的提高;③所有的销售记录,包括销售量、优惠促销活动等信息都可以获得;④使增加更多的价格采集点成为可能;⑤扫描数据是电子版的形式,减少了人工数据录入的环节,可以避免人工采价过程中产生的误差,包括:采价员录入价格时发生的错误;产品货架或是产品包装上错误的价格信息[2]。
第二,扫描数据得到的价格是实际的交易价格而非挂牌价格,而传统的采价方式得到的可能是挂牌价格而非实际交易价格。
第三,扫描数据为改进CPI的编制提供了可能。主要表现为以下几个方面:①扫描数据提供的商品交易数量和交易金额等信息,为编制CPI基本分类指数提供了权重信息,而权重信息扩大了编制CPI公式的选择余地;②降低了质量变化的偏差,质量变化的偏差在所有CPI偏差中所占比例较大[4],而hedonec方法是解决这一问题最常用的方法,hedonec分析的前提是大量的数据,扫描数据正好提供了这一条件,而在传统数据收集方法下要调整产品质量的变化,需要采价员具有一定的专业知识;③扫描数据可以得到超市的营业额,因此按营业额精确抽取价格调查点可以提高抽样精度。
第四,扫描数据减少了零售连锁商店负担的工作量。
第五,扫描数据提供了一种评价人工采价方式造成的测量误差的方法。
(二)局限性
目前扫描数据作为一种新型的采价方式,各国在进行实证研究的过程中,也发现其存在一定的局限性:
第一,对于代表规格品的选择和质量的调整,还不能达到完全自动化,需要人工进行操作(Reto M■iller,2010)[5]。
第二,扫描数据不可能完全替代人工采集价格的工作,因为目前扫描数据的适用范围还有限:一方面,有很多代表规格品,尤其是服务性商品,没有扫描数据;另一方面,很多传统的市场形态无法提供扫描数据,如我国的农贸市场。
第三,相关理论和概念还需要研究。因为扫描数据反应的是交易情况,而不是消费情况。在指数理论和相应的国民账户体系中,购买和消费是两个不同的概念。因此在概念方面还需要进一步研究,使得各种概念协调统一(高艳云,2008)[7]。
第四,统计部门编制价格指数是一项连续、前后一致的工作,需要有长期、连续、稳定的数据供给。这就需要相关企业的配合,包括零售企业和市场调查公司。如果没有好的配合,可能会导致数据收集工作出现中断,不利于指数的编制(高艳云,2008)[7]。
第五,对于高频海量数据,统计部门必须要有很好的处理能力才能进行有效利用。这对统计部门的数据处理能力是一种挑战。
第六,扫描数据的被动性,即商品的数据信息只有在发生交易的情况下才能被采集。
最后,对于获得扫描数据的成本问题,每个国家获得扫描数据的渠道不同,结果也相差很大。如瑞士,之前在这一领域的传统的价格采集主要是由私人市场研究机构代表政府统计部门来完成的,采用扫描数据之后,瑞士统计局直接从连锁超市获得,成本将大大减少(Reto M■ller,2010)[5]。在荷兰,扫描数据的运用能够有效降低成本,传统的采价方式中,采价员对采价样本点的走访是编制CPI开支中的最主要部分。但是,有的国家,比如美国和英国,扫描数据是从市场调查公司购买来的,因此成本比较大,甚至比人工采价成本更高。
三、扫描数据的采集
(一)扫描数据的获得途径
目前,扫描数据的获得途径有两种:一种是政府统计部门和大型连锁超市合作,由连锁超市的总部定期将扫描数据发送给国家统计部门;一种是由超市把扫描数据出售给市场调查公司,然后国家统计部门从市场调查公司购买扫描数据。
一般情况下,统计部门以第一种方式获取扫描数据是免费的。Johaansen和Nygaard(2012)指出,挪威的扫描数据是由本国几个大型连锁超市的总部每个月发送扫描数据到挪威统计局。Norberg等(2011)指出,瑞典统计局从一个拥有20家分店的零售连锁企业获得扫描数据。这家零售连锁企业从2008年12月开始,每月分三次(每周一次)通过Email的形式把扫描数据提交到瑞典统计局[8]。荷兰统计局每个星期(每个月的前三个星期)都会收到几家大型超市企业的扫描数据(Grient and Haan,2010)。
统计部门若以第二种方式获取扫描数据,则可能要花费较大的费用,这笔费用甚至可能比使用人工采价的方式更高。
(二)数据的采集内容
首先,每一条扫描数据中包括一个特有的EAN码和它包含的每周的销售额和销量、销售时间,以及尽可能简短的产品描述,通常包括的描述信息有产品重量、内容和包装的大小(Haan and Grient,2011)[9]。同时,还应该加入扫描数据来源的超市类型和地点(Johaansen and Nygaard,2012)。
还有一个重要产品信息是零售连锁超市自己的产品分类编码,以表明某一个EAN码是哪一个产品分类的,这对于提高统计部门CPI的编制效率,非常关键。因为扫描数据的数量非常大,如果由政府统计部门对所有扫描数据对应的产品进行分类,非常耗时。所以说,超市自身的分类对于统计部门的再分类来说,很有必要。一旦超市的分类方式和CPI统计的分类方式的对应关系建立起来,那么EAN码对应的每个代表规格品就会自动地分类到它们所属的CPI分类之中。
对于一些如新鲜水果、蔬菜和肉类等商品,超市会编制特有的PLU码进行识别。这也是扫描数据需要采集的数据内容。一般情况下,某一超市对于特定的商品(如猪肉的代表规格品之一“排骨”)会一直使用同一条形码,如果超市对PLU码所对应的代表规格品发生了变化,它们将在数据清理环节或是月度的常规检查和分析价格指数计算结果中被更正(Grient and Haan,2010)。
(三)扫描数据的采集范围
在利用扫描数据编制CPI时,很多国家都把它的使用范围限制在一个更为传统的目录下。
瑞士统计局于2008年7月第一次在CPI/HICP的编制中引入扫描数据,利用扫描数据的范围就是食品和类似食物的商品,选取的调查对象为瑞士一家最大的连锁超市(这家超市的食品销售市场份额占到全国的25%以上)。2010年1月,瑞士统计局引入了更多的超市(Reto Müller,2010),并把非食品的一些代表规格品引入进来。
挪威统计局于2005年开始利用扫描数据计算食品和非酒精性饮料的月度链式价格指数(在基本分类指数的层面上。2012年,挪威统计局计划把利用扫描数据编制CPI的范围扩大到医疗产品上,并且要覆盖几乎所有购买这些商品的销售记录的数据。
荷兰在开始利用扫描数据时,也同样把扫描数据的使用范围限制在食品领域,采集数据也仅在两家连锁超市内。但是最近几年,随着技术的成熟和研究的深入,荷兰统计局在相当程度上扩大了利用扫描数据进行价格采集的范围,采集数据的超市也扩大到了六家。目前,这一范围包括衣服、玻璃器皿、餐具以及其他家庭用具等,具体的范围在表1所示的COICOP(Classification of Individual Consumption by Purpose)目录中。
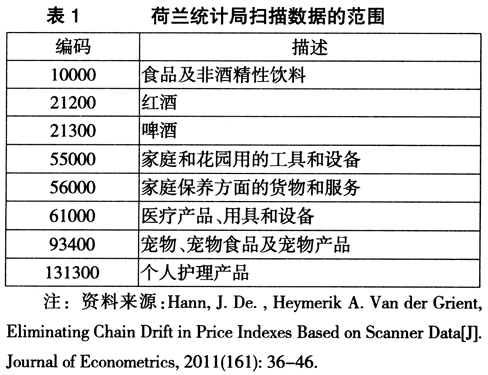
综合各国的情况,我们发现,其中有一些经验值得我们借鉴:每个国家都是先以CPI统计范围中的某一基本分类开始采集扫描数据,通常以食品及非酒精性饮料开始,然后逐步扩大,一方面扩大调查超市的数量,一方面扩大扫描数据的统计范围;在使用扫描数据的初期,以扫描数据代替原先人工采集的数据,使用传统的计算方法进行编制CPI,以检验其可靠性。
四、代表规格品的选择
传统的CPI价格采集方式,限制了代表规格品的样本数量。比如我国目前CPI统计中262个基本分类之一的“液体饮料”,国家统计局要求调查至少3种“液体饮料”的代表规格品。在实际操作中,由于是人工采价,可能调查的规格品数量虽然多于三种,但是和市场上“液体饮料”的商品数量相比,依然是非常少的。如果我们采用扫描数据的话,就可以在很大程度上增加“液体饮料”的代表规格品的数量。但是,增加多少,什么“液体饮料”需要被选为代表规格品,是一个需要考虑的问题。
(一)链式价格指数
目前,CPI的理论框架有两种:一种是以生活费用指数作为理论框架,一种是以固定篮子指数作为理论框架[10]。在扫描数据为价格数据源头的情况下,每个月会有很多代表规格品都会消失,同时又会有很多新的代表规格品出现。因此,固定篮子(A fixed item basket)很容易失去其代表性。
同时,Grient和Haan(2010)对代表规格品的高流失率做了一项实证研究。他们对“洗涤用品”对应的代表规格品个数的月度数据进行观察发现:2007年1月选定的67个代表规格品,到了2009年10月只剩下了19个规格品仍然有人在购买;而在这段时间里,“洗涤用品”产品种类变成了82个。而一个更实际的问题是,由于扫描数据使得每一个基本分类下的可以选择的代表规格品很多,所以每年对于代表规格品的选择和替换是一项非常耗时的工作。因此,现有的指数编制方法很难处理这些问题,而需要研究一种更为有效的方法来处理更多超市中的扫描数据,并减少人工参与。
最好的方法是(在基本指数层面上)使用月度链式匹配规格品的价格指数(a monthly chained matched-item index)。这种方法不需要建立固定的产品篮子,有效地解决了新旧产品的更替问题,而且可以及时反映市场的动态变化。
(二)隐形加权
Grient和Haan(2010)在研究中发现:基本分类中所有代表规格品的支出分布是高度偏差的:通常是40%~50%的规格品连10%的基本分类的支出份额都不到;相反的是,相对少数的代表规格品占据着绝大多数的支出份额。如果使用Jevons指数(未加权)就会忽视这种差距。因此,荷兰统计局使用了一种粗略的隐性加权形式来削减代表规格品:重要的代表规格品(表现为所占的支出份额较大)在计算中得以保留,而不重要的则删除掉。具体讲,如果一种代表规格品连续两个月的平均支出份额(与其对应的同一基本分类所有规格品相比)在某个门槛值以上,则这个规格品就被用于指数的计算。

五、数据准备
(一)数据清理
在进行价格指数计算前,价格数据(月度单位价值)要接受两个数据清理(data clean)程序的检验。
第一步,月与月之间的价格变动过大被认为是不可信的,并宣布无效。因此,那些价格是上一个月的价格的4倍或是1/4的规格品将会被删除。
第二步,一种称为倾销过滤(a dumping filter)的算法,用来排除那些由于销量急剧下降而引起的价格大幅下降的规格品。发生“倾销”情况的概率不大,只有在规格品以一个非常低的价格出售以达到清仓目的时才会出现。因此,这一产品将不会再被用来当作规格品用于计算CPI。在实际操作中,“倾销过滤”这一算法可能会删除更多的规格品,而不仅仅是涉及清仓的规格品,但这一问题不应看作和价格丢失一样严重。
(二)缺失数据的处理
扫描数据和人工价格采集相比,出现缺失值的可能性更大些。因为如果一个月时间都没有交易记录的话,就没有扫描数据的记录,形成了数据缺失。对于数据的缺失,我们有很多种补救途径。我们首先要分析数据缺失的原因是什么。造成数据缺失可能是暂时性的,也可能是永久性的和季节性的。如果是永久性的数据缺失,可以用相似的产品进行替代。如果数据缺失是暂时性的或是季节性的,一般有如下三种方法来处理:一是不做任何处理;二是采用上期价格进行替代;三是用推倒法进行估算。
六、指数计算
CPI指数计算一般都是遵循自下而上的顺序,即先计算各个基本分类指数,然后在进行高层次的汇总,一直到计算出最终的CPI。其中,在传统基本指数计算公式的选择上,由于缺乏代表规格品的权重信息,一般使用的是Jevons指数和Dutot指数这样的非加权指数。而扫描数据的出现,为我们在基本指数计算的层面上提供所有产品的价格和销售数量,这使得编制加权的价格指数成为可能。但是,扫描数据本身也有一些潜在缺陷,如数据的高流失率、价格和销量受促销影响波动较大以及临时性的规格品价格缺失等。为了克服这些问题,各国在CPI指数的计算上,尤其是在处理链式漂移(chain drift)的问题上,采取的方法也不尽相同。
(一)链式漂移
上文已经提到,为了反应价格市场动态变化,解决新旧产品更替的问题,在计算月度基本分类价格指数时采用了链式指数,然而链式指数会出现我们所熟知的链式漂移。《消费者价格指数手册:理论与实践》(Consumer Price Index Manual: Theory and Practice)指出:如果当一个链式指数的基期和报告期互换后得到的数值与原先的价格指数不一致,这说明这一链式指数发生了链式漂移[11]。因为链式指数不满足指数公理法中的时间互换检验。时间互换检验指如果一个价格指数的基期和报告期的价格和数量互换后,计算得到的价格指数等于互换之前价格指数的倒数,公式为:
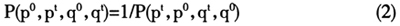
为了研究链式漂移对以链式价格指数方法、并以扫描数据为数据来源来编制CPI的影响,Haan等人(2011)进行了一项实证分析。他们分别利用Fisher指数、
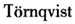 指数和Jevons指数,编制从2005年1月到2008年4月的洗涤用品(detergents,CPI基本分类价格指数)的周度、月度和季度的价格指数。分析结果表明:
指数和Jevons指数,编制从2005年1月到2008年4月的洗涤用品(detergents,CPI基本分类价格指数)的周度、月度和季度的价格指数。分析结果表明:(1)与先前学者(Feenstra和Shapiro,2003;Ivancic,2007;Haan,2008;Ivancic,2009)的研究结论一致,周度数据中,链式漂移在加权的链式指数中表现较为明显,而在非加权指数中表现不明显。
(2)月度链式指数能够显著地减少链式漂移。其中,Fisher指数和
指数的趋势几乎相同,并且在数值上高于Jevons指数。(3)季度链式Fisher和指数显示出了明显的向上趋势的链式漂移,而Jevons指数则相对平稳。
如何更好地避免链式漂移,是各国在利用扫描数据编制CPI时主要考虑的问题。就目前实际利用扫描数据编制CPI的三个国家来看,方法不尽相同,主要是基本分类价格指数的计算公式的选择。
(二)各国的实际应用
由于扫描数据本身的一些缺陷和指数计算公式选择的困难,瑞士统计局在利用扫描数据时仅仅是把它当作数据采集的一种方法,来替换人工采集,而依然采用传统的指数公式来编制CPI。因此,瑞士统计局避免了上述诸如链式漂移问题的发生。
由于扫描数据提供了代表规格品的销售份额,所以对应代表规格品的报告期的权重就变为已知。因此,挪威统计局在计算基本分类价格指数中使用了Fisher指数。使用Fisher指数有一个明显的优势,即能够同时考虑到某一代表规格品基期和报告期的权重。某一特定代表规格品的销售份额会随着时间发生变化,尤其是那些季节性较强的或是正在促销的规格品。因此,如果使用Laspeyre指数(以报告期权重计算)会高估价格的变化;而使用Paasche指数(以基期权重计算)会低估价格的变化。而Fisher指数正好能够抵消这两种偏差。又由于新旧产品的频繁变化,因此很容易想到使用月度链式指数,但是月度链式指数会出现上文提到的链式漂移。由于发生链式漂移主要是因为超市促销而引起的价格和数量的剧烈变动,所以,挪威统计局采取了一种简单而直接的方法,即把那些在促销的产品排除在代表规格品的范围之外。
与瑞士和挪威的方法不同,荷兰统计局采取了一种更为复杂的方法,即在代表规格品的选择上和指数公式都进行了改编,以达到消除链式漂移的同时,尽可能真实准确地编制CPI。尽管扫描数据提供了每一个代表规格品的基期和报告期的销售额和销售数量等相关数据,但荷兰统计局为了避免链式漂移,在基本分类指数层面上,并没有使用诸如Fisher指数或
指数这样的最佳价格指数,而是使用了Jevons指数。基本分类a在y年m-1月和y年m月间的价格变化的计算公式为:

对于那些在y年m月没有卖出的、而在之前一个月份卖出的规格品i,y年m月价格可以近似按公式(5)进行估计计算:
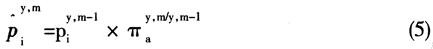
对于高层指数(如A)短期的汇总,很多国家仍然使用的是Laspeyres公式进行计算的,如公式(6)所示。其中价格指数的基期为y-1年。
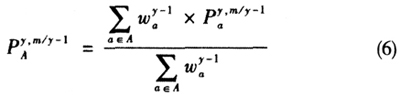
对于公式(6)的权重
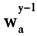 ,每个国家情况不同。如荷兰和瑞士,是根据每年所有属于基本分类a的产品的支出份额作为权重,而不仅仅考虑代表规格品的支出份额;有的国家是根据家庭支出调查的数据确定权重;还有的国家利用国民核算的相关数据在高层的指数汇总进行赋权。
,每个国家情况不同。如荷兰和瑞士,是根据每年所有属于基本分类a的产品的支出份额作为权重,而不仅仅考虑代表规格品的支出份额;有的国家是根据家庭支出调查的数据确定权重;还有的国家利用国民核算的相关数据在高层的指数汇总进行赋权。短期的指数序列在12月被链接起来以建立以某一规定时期为基期(我国每五年更换一次基期,目前的基期为2010年)的长期的价格指数,如公式(7)所示:

(三)GEKS指数和RYGEK指数
Ivancic等人(2009)提出建立一种新的价格指数方法,来利用扫描数据编制CPI,即对GEKS指数的改进。这种方法可以解决在使用最佳价格指数(a superlative price index)的同时,利用扫描数据这样的高频链式数据,编制基本指数,而且能够避免出现链式漂移的问题,所有的价格信息也能得到有效的利用[12]。
GEKS指数对Gini(1931)、Elteto和Koves(1964)和Szulc(1964)等人提出的多边GEKS指数(the multilateral GEKS index)进行了改进。GEKS方法通常在空间价格比较(即购买力平价)中使用,改编后使之用于不同时间的价格比较。


所以说,式(8)的GEKS价格指数满足循环性和传递性的要求。
GEKS多边指数经常用于比较不同国家或地区之间的价格水平(Diewert,1999)[13]。其中,传递性对于规避对基期国家和链接国家的选择非常关键。
为了利用扫描数据计算一个国家和地区的CPI,Ivancic等人(2009)改进了GEKS指数:其中式(8)和式(9)中的单位j和k变为需要计算价格指数的两个时期,ι为它们的连接时期。如果选择时期0为价格指数的基期,报告期为t(t=1,……,T),并且从基期0到T期的所有相关价格和数量的数据都是已知的话,则可以把GEKS价格指数变换成从基期0到报告期t的价格指数,如式(10)所示:

传统的指数计算公式中,进入到指数汇总的双边指数,只是相关代表规格品在两个时期的价格的比例。而GEKS多边指数是一种弹性篮子度量的方法,因此它能够最大限度地利用在任意两个时期内所有能够匹配的代表规格品。这也是GEKS指数最重要的一个特性。因此,也不存在数据缺失的情况。
但是,计算
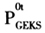 的前提是所有的时期(包括t+1,……,T)的价格和数量都是已知的。而在计算过程中,我们不可能使用未来的数据。因此,在实际计算中,最新时期T的价格指数的计算是使用所有可以利用的数据,并且及时更新时间序列数据。所以,更为方便地表示从0期到T期的GEKS价格指数如式(12)所示:
的前提是所有的时期(包括t+1,……,T)的价格和数量都是已知的。而在计算过程中,我们不可能使用未来的数据。因此,在实际计算中,最新时期T的价格指数的计算是使用所有可以利用的数据,并且及时更新时间序列数据。所以,更为方便地表示从0期到T期的GEKS价格指数如式(12)所示:

实际上,我们没有必要公布重新计算的指数,因为指数是没有链式漂移的。若令
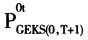 表示需要重新计算的指数,我们可以利用式(13)在T+1和T做变换,作为一个链式连接来更新时间序列指数。由于具有传递性,双边价格指数满足时间互换检验,因此,我们有式(14):
表示需要重新计算的指数,我们可以利用式(13)在T+1和T做变换,作为一个链式连接来更新时间序列指数。由于具有传递性,双边价格指数满足时间互换检验,因此,我们有式(14):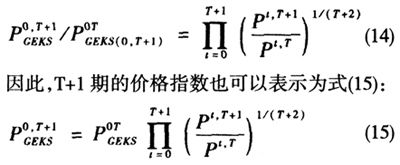
同理可得T+1,T+2,T+3期的价格指数。
Ivancic等人(2011)根据这一原理,提出一种称之为“滚动年GEKS指数”(a rolling year GEKS index,RYGKS)的方法。首先,和绝大多数的国家一样,他们假设CPI指数是一个月度价格指数(即每月公布CPI指数)。RYGKS指数利用持续的最新13个月的价格和数量的数据来计算GEKS指数。13个月的时长作为滚动时间是最佳的,因为这样可以和一些有很强季节性的规格品进行比较。使用
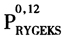 作为构建月度时间序列的起始点,则13个月时长的滚动时间RGEKS指数表示为式(16):
作为构建月度时间序列的起始点,则13个月时长的滚动时间RGEKS指数表示为式(16):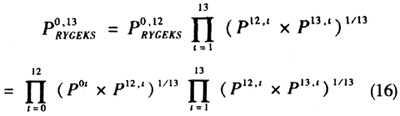
其中,
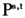 表示从基期s到报告期t的一种最佳价格指数,如Fisher指数。从基期0到报告期T(T≤12)的RYGEKS价格指数的一般表达式为:
表示从基期s到报告期t的一种最佳价格指数,如Fisher指数。从基期0到报告期T(T≤12)的RYGEKS价格指数的一般表达式为: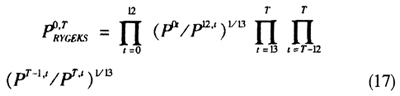
GKKS和RYGEKS指数都是基于以最佳价格指数作为双边指数的综合指数,因为最佳价格指数满足时间互换检验,以及其他一些良好的特性。
(四)评价
根据以上分析,我们可以发现,瑞士统计局利用扫描数据的方法较为简单,即仅仅把扫描数据作为CPI价格采集的一种手段。而扫描数据的大量信息,如产品的销售份额和大量的代表规格品都没有被有效利用。这种做法的优势是回避了目前利用扫描数据编制CPI可能出现的一些问题;同时不改变先前的CPI指数计算方法,具有延续性。但是,这一方法没有发挥出扫描数据的大部分优势,对数据资源和信息也是一种浪费。应该说瑞士统计局是利用扫描数据编制CPI初期的一种保守方法,但笔者认为这种方法对于那些希望利用扫描数据编制CPI,但又担心数据质量的国家来说,值得推广。
挪威统计局的方法发挥了扫描数据的基本优势。但是正如上文所说,为了适用于加权链式价格指数并且消除链式漂移,该方法将正在促销的代表规格品排除在外。这样做的弊端是那些促销的商品一般都较受欢迎并且销售量大,排除这些商品可能会导致指数的偏差。
荷兰统计局虽然在代表规格品中涵盖了绝大多数的商品,但该方法也有不足:在基本分类的指数计算中,在扫描数据能够给出权重的前提下,使用了Jevons指数而非加权指数。这也没有充分发挥出扫描数据的优势,对数据资源本身也是一种浪费。笔者认为,荷兰统计局目前的做法是在现有指数计算方法中实用性最强的一种。与瑞士和挪威统计部门的方法相比,荷兰统计局利用扫描数据计算的CPI数据质量最高。
而GEKS指数及其RYGEKS指数作为一种新的方法,从实证分析的角度来讲,有效地解决上述三种方法的不足,前景广阔。但是,目前还没有国家正式利用这种方法编制本国的CPI指数。因为RYGEKS指数在形式上不是直接的价格指数,不容易向CPI的使用者和计算者解释。同时,这种方法还未被统计界广泛接受。
七、结论
随着信息技术的发展和全球的一体化,消费者的购物习惯在不断地改变,产品和服务的定价方式也变得更加复杂,这要求政府统计部门的价格采集方法不断革新。笔者认为,和传统的价格采集方式相比,扫描数据能够从数据的覆盖范围和精确性等方面入手,提高价格数据的采集质量,并为CPI的编制提供更为丰富的信息。
目前,各国政府统计部门都在致力于创新CPI数据采集方法,以获取更丰富的数据信息和更高的数据质量,并降低企业回答负担和采集数据的成本。而扫描数据以及其他信息化数据采集方式的出现,使得这一目标有望实现。扫描数据利用电子结算系统及其数据库,为政府统计部门提供了大量可以利用的数据资源。但与此同时,海量数据在提供更多更有效信息的同时,也对现有的价格指数计算方法提出了更大的挑战。扫描数据降低了企业的回答负担和采集数据的成本,但并不意味着能够很容易实现提高CPI编制水平这一核心目标。因此,我们还需要进行大量的研究,以便更好地利用扫描数据。
参考文献:
[1]Ingvild Johaansen, Ragnhild Nygaard. Various data collection methods in the Norwegian CPI[A]. UNECE/ILO conference on Consumer Price Indices, Geneva, 30 May-1 June, 2012.
[2]陈相成,乔晗,温素清.扫描数据支持下的CPI调查[J].市场研究,2012(7):28-33.
[3]Berthold Feldmann. Scanner Data-next steps ahead[DB/OL]. Scanner Data Workshop, Stockholm 7-8 June 2012.
[4]James Ressiter. Measurement Bias in the Canadian Consumer Price Index[A]. Working Paper 2005-39, Bank of Canada.
[5]Reto Müller. Price collection with scanner data for the Swiss CPI/HICP[A]. Joint UNECE/ILO meeting on Consumer Price Indices Geneva, 10-12 May 2010.
[6]Heymerik van der Grient, Jan de Haan. The use of supermarket scanner data in the Dutch CPI[A]. Division of Macro-economic Statistics and Dissemination. Statistics Netherlands, 2010.
[7]高艳云.价格指数的理论与方法[M].北京:中国财政经济出版社,2008.12.
[8]Anders Norberg, Muhanad Sammar, Can Tongur. A study on scanner data in the Swedish Consumer Price Index. Twelfth meeting Wellington, 10-12 May, 2011.
[9]Hann, J. De., Heymerik A. Van der Grient. Eliminating chain drift in price indexes based on Scanner Data[J]. Journal of Econometrics, 201 1, (161): 36-46.
[10]徐强.CPI编制中的几个基本问题探讨[J].统计研究,2007(8):30-35.
[11]ILO, IMF, OECD, Eurostat, United Nations, World Bank. Consumer Price Manual: Theory and Practice[M]. Geneva, International Labour Organization, 2004.
[12]Ivancic, L., Diewert, W. E., Fox, K. J. Scanner data, time aggregation and the construction of price indexes. Discussion Paper 09-09. Department of Economics, The University of British Columbia, Vancouver Canada, 2009, V6T 1Z1.
[13]Diewert, W. E. Index number approaches to seasonal adjustment[J]. Macroeconomic Dynamics, 1999(3): 1-21.
[14]Hill, R. J., Superlative indexes: Not all of them are super[J]. Journal of Econometrics, 2004(130): 25-43.^