【内容提要】
伴随着计量经济学模型方法的广泛应用,错误也屡屡发生,重要原因之一是没有正确理解模型对数据的依赖性。本文从计量经济学模型类型选择、总体回归模型设定、模型估计和模型应用等方面分析了数据的作用,指出了容易出现的错误和产生错误的原因。
【关 键 词】计量经济学模型/模型类型选择/总体回归模型设定/数据依赖性
一、引言
在我国,计量经济学模型在经济理论研究和经济问题分析中已经被广泛采用,成为一种主流的实证研究方法。在一些社会问题的研究中,采用计量经济学模型方法也已经成为一种趋势。同时,模型对数据的依赖性愈发突出,数据的数量和质量成为计量经济学应用研究的一个重要制约因素。
计量经济学的创始人弗里希(R. Frisch)为计量经济学下了如下定义:“经验表明,统计学、经济理论和数学这三者对于真正了解现代经济生活的数量关系来说,都是必要的,但本身并非是充分条件。三者结合起来,就是力量,这种结合便构成了计量经济学。”1984年诺贝尔经济学奖授予著名的统计学家斯通(Richard Stone)是因为他“在发展国民核算体系方面做出了基础性贡献,并因此极大地改善了经验经济分析(即计量经济分析)的基础”。2000年获得诺贝尔经济学奖的赫克曼(J. Heckman)和麦克法登(D. McFaddan)的贡献是发展了微观计量经济学模型的理论方法,在瑞典皇家科学院发布的新闻公报中着重指出,他们“已经解决了对微观数据进行统计分析中出现的基本问题”。创立动态计量经济学的亨德里(David Hendry)认为,计量经济分析的过程就是发现客观的数据生成过程的过程。这些足以说明,计量经济学与统计学密不可分,统计学的发展催生了计量经济学,计量经济学的发展带动了统计学。具体表现于计量经济学模型和数据之间的紧密联系。
在计量经济学模型的应用研究中,经常有人提出类似于“鸡生蛋还是蛋生鸡”的问题,即究竟是根据数据设定模型,还是根据模型选择数据?不同的是,鸡与蛋的关系问题是没有答案的,而模型与数据的关系问题是有答案的。计量经济学应用研究中模型与数据之间的关系可以用图1表示。图中①表示计量经济学应用模型的类型依赖于表征研究对象状态的数据类型,不同类型的数据,必须选择不同类型的模型。在模型类型确定之后,依据对研究对象的系统动力学关系的分析,设定总体模型。在这个过程中,必须对在经济理论指导下所分析的系统动力学关系进行统计必要性检验,如图中②所示。当总体模型被正确设定后,接下来的任务是进行模型参数的估计,毫无疑问,模型估计必须得到样本数据的支持,模型估计结果依赖于样本数据的质量,即为图中③所示。模型经过估计和检验后进入应用,根据应用目的的不同,需要不同的数据支持,例如用于预测,必须首先给出预测期的外生变量的数据,这就是图中④所表示的步骤。
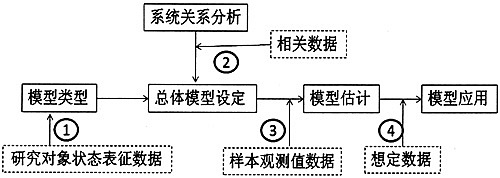
图1模型与数据之间的关系图
计量经济学模型对数据的依赖性的一个人所共知的例子是关于我国广义技术进步对经济增长的贡献的测算。国内外许多学者进行了经验研究,结果差异极大,技术进步对GDP增长的贡献率,最低的估计为0,最高估计达到40%。甚至所建立的模型都是C-D型总量生产函数模型,选择的投入要素都是资本和劳动,甚至选择的样本区间也是相同的,数据都来自于中国统计年鉴,仍然会得到不同的结论。为什么?关键是不同的研究者对资本投入的数据或者未进行任何处理,或者进行了不同方式的处理,以消除价格因素的影响。请注意,在统计中,固定资产原值(或者净值)数据是以资产形成年的价格计量的资产简单相加得到的。
最近几年,我们对农户借贷需求进行了较为广泛的调查,采集了青海、新疆、甘肃、河北、黑龙江、吉林、山西、湖南、湖北、河南、安徽、江西、陕西、山东、辽宁、内蒙古等16省区的72个县、440多个村庄的5100家农户的数据。其中,在一年中发生借贷行为的农户占55.3%(包括向亲友借贷),为2820户,其余2280户没有发生借贷。对于这一宝贵的数据资源,当然要充分利用。于是,为了对农户借贷行为进行因素分析,不同的研究者建立了不同的计量经济学模型。有人利用2820户发生借贷的农户的借贷额为被解释变量,建立经典的回归模型;有人认为应该将没有发生借贷的农户信息加以利用,其借贷额为0,于是利用5100农户为样本,建立经典的回归模型;有人认为不应该将没有发生借贷的农户的借贷额统统视为0,而应该视为小于等于0(≤0),于是利用5100农户为样本,建立了归并(censoring)数据模型(Tobit模型)。有人认为不应该将没有发生借贷的农户的借贷额统统视为小于等于0,因为其中一部分农户有借贷需求,只是因为各种原因(例如提出借贷被拒绝,担心借不到而不敢提出借贷要求等)而没有发生实际借贷。所以,应该按照Heckman两步法建立模型,即首先利用全部样本信息建立借贷是否发生的二元选择模型,然后再利用2820户发生借贷的农户为样本,建立借贷额的因素分析回归模型。显然,最后一种模型是正确的,其他都是不正确的。那么,为什么会发生这些现象?
上述例子从不同的角度反映了计量经济学模型与数据之间的关系。前者反映了计量经济学模型估计结果对数据质量的依赖性;后者反映了计量经济学模型类型对数据类型的依赖性。正如李子奈(2007)指出的,在我国计量经济学应用研究广泛开展的今天,问题和错误也普遍存在。重要的原因之一是对计量经济学模型方法论基础缺乏正确的理解,其中包括计量经济学模型的数据基础问题。①
下面将着重就当前计量经济学应用研究中有关模型与数据之间关系的几个迫切、重要的问题进行讨论。最后对“数据陷阱”问题进行简单的讨论。
二、模型类型设定对数据的依赖性
在经济、社会问题研究中,当研究对象确定之后,表征该经济、社会活动结果的数据自然地被确定了。例如,研究我国经济增长的影响因素以及各个因素对增长的贡献,那么表征经济增长结果的GDP时间序列自然地成为模型研究的对象;研究学生在本科4年内不及格的课程门数与什么因素有关,那么表征不及格门数的计数数据0、1、2、…自然地成为模型研究的对象;研究农户的借贷方式由哪些因素决定,那么表征农户向各种正规金融和非正规金融机构借贷的选择结果的离散选择数据0、1、2、…自然地成为模型研究的对象;等等。计量经济学应用研究的第一步,就是根据表征所要研究的经济、社会活动结果的数据类型确定应该建立什么类型的计量经济学模型,在这一步骤中,数据的类型决定了计量经济学模型的类型。李子奈(2008)指出,一个成功的计量经济学应用研究,最重要的是设定正确的总体回归模型;并且提出了总体模型设定的若干原则,包括惟一性、一般性、现实性、统计检验必要性和经济系统动力学关系导向原则。②但是这些是在模型类型确定之后的任务,确定模型类型仍然是首要的任务。
用于宏观和微观计量经济分析的数据分为三类:截面数据(Cross-sectional Data)、时间序列数据(Time-series Data)和面板数据(Panel Data,也译为平行数据、综列数据)。
对于截面数据,只有当数据是在截面总体中由随机抽样得到的样本观测值,并且变量具有连续的随机分布时,才能够将模型类型设定为经典的计量经济学模型。经典计量经济学模型的数学基础是建立在随机抽样的截面数据之上的。但是,在实际的经验实证研究中,面对的截面数据经常是非随机抽样得到的,或者是离散的,如果仍然采用经典计量经济学的模型设定,错误就不可避免了。事实上,20世纪70年代以来,针对这些类型数据的模型已经得到发展并建立了坚实的数学基础。
例如在前述的农户借贷的实例中,如果只利用2820户发生借贷的农户为样本,建立经典的回归模型,被称为“截断数据”(Truncation Data)。这类数据在实际经济分析中十分常见,特别在微观经济社会问题研究中大量存在。人们抽取的样本经常是“掐头”或者“去尾”的。对于这类数据,因为抽取每个样本的概率发生了变化,如果仍然采用经典计量经济学模型,其估计结果就产生了“选择性偏误”,应该建立截断数据模型,在这方面J. J. Heckman(1974,1979)做出了基础性贡献。③④
例如,如果我们分析学生的学习成绩与相关影响因素之间的关系,学习成绩的最高分为100,最低分为0。处于0与100之间的得分,是学习成绩的真实反映;而表现为100分和0分的学生,实际学习成绩是不同的,所以应该将100分看为大于等于100分的归并,将0分看为小于等于0分的归并。这类数据被称为“归并数据”(Censored Data)。它们在经济分析中也是常见的,例如受到供给限制条件下的商品需求量、尚处于失业状态下的失业时间。类似地,因为抽取处于归并点的每个样本的概率发生了变化,如果仍然采用经典计量经济学模型,其估计结果也会产生“选择性偏误”,应该建立归并数据模型,在这方面,J. J. Heckman(1974,1979)同样做出了基础性贡献。
例如,我们研究的对象是选择的结果,或者是二元选择问题,或者是多元选择问题。作为模型被解释变量的观测值只能是0、1或者0、1、2、……这类问题人们几乎每时每刻都面临着。选择结果受哪些因素的影响?各个因素的影响程度有多大?当然可以通过建立计量经济学模型来分析。但是,经典计量经济学模型显然是不适用的,应该建立专门的离散选择模型,在这方面,D. L. McFadden(1974)做出了基础性贡献。⑤
再如,我们经常要研究表现为计数数据(Count Data)的社会、经济活动结果受哪些因素的影响。例如,汽车一个月内发生事故的次数、学生本科4年内不及格的课程门数、大学毕业生参加工作前5年内调换工作的次数、个人一年内到医院就诊的次数,等等。这些数据都是离散的非负整数,在随机抽取的一组样本中,零元素和绝对值较小的数据出现得较为频繁,重复抽样的正态分布假设不再适用。显然,对于这样的问题,不可以建立以正态性假设为基础的经典计量经济学模型,应该建立专门发展的计数数据模型,Gilbert(1979)提出了泊松回归模型,Hausman,Hall & Griliches(1984)提出了负二项回归模型。
再如,以某项活动持续时间作为研究对象的经济问题,例如研究失业持续时间与影响因素之间的关系。在这类问题中,仅从数据方面看存在两个问题:一是失业已经持续的时间并不是失业持续时间的真实反映,不能作为失业持续时间的观测值;二是取得部分解释变量的样本观测值存在困难,因为它们在持续时间内是变化的。毫无疑问,持续时间数据(Duration Data)问题也不能建立经典的计量经济学模型,诸如风险比率模型等得到了发展和应用。
对于时间序列数据,经典计量经济学模型只能建立在平稳时间序列基础之上,因为只有对满足渐进不相关的协方差平稳序列,才可以适用基于截面数据的统计推断方法,建立时间序列模型。协方差平稳性和渐进不相关性为时间序列分析适用大数定律和中心极限定理创造了条件,替代了截面数据分析中的随机抽样假定(Wooldridge,2003)。否则,数据的时间序列性破坏了随机抽样假定,取消了样本点之间的独立性,样本点将发生序列相关。如果序列相关性不能足够快地趋于零,在统计推断中发挥关键作用的大数定律、中心极限定理等极限法则缺乏应用基础。很可惜,实际的时间序列很少是平稳的。由于宏观经济仍然是我国学者进行经验实证研究的主要领域,而宏观时间序列大量是非平稳的,于是出现了大量的错误。只有经济行为上存在长期均衡关系,在数据上存在协整关系的非平稳时间序列,才能够建立经典的结构模型,C. W. Granger(1974,1987)等的贡献解决了非平稳时间序列模型设定的数学基础问题。⑥⑦
至于面板数据,截面数据和时间序列数据存在的问题同时存在,并且还提出了模型设定的专门问题,例如变截距和变系数问题、随机影响和固定影响问题等,已经发展形成了一套完整的模型方法体系(见Cheng Hsiao,1986,2003)。⑧依据新的模型方法体系设定总体理论模型,才能进行可靠的经验实证。
三、总体回归模型设定对数据关系的依赖性
李子奈(2008)曾经用图2描述数据在总体回归模型设定中的作用。在经济学理论指导下,通过经济主体动力学关系分析,得到了对研究对象(在单方程计量经济学模型中被称为被解释变量)具有恒常的、显著的影响的因素。这些关系是否真的存在?这些因素如何被引入模型?仍然需要依赖数据。即经济关系的确认,是以数据之间存在统计相关关系为条件的。这就是总体回归模型设定对数据关系的依赖性。所以,在经济主体动力学关系分析的基础上,必须进行数据的统计相关性检验,包括时间序列的因果关系检验,对经济行为分析的结论加以“甄别”,去伪存真。
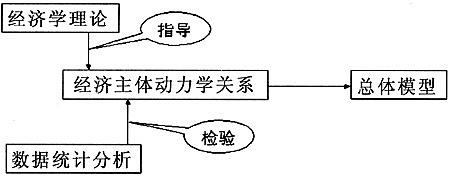
图2理论、数据、动力学关系与总体模型
这里必须强调的是,在图2中,首先是在经济学理论的指导下,对研究对象进行经济行为分析,然后利用数据进行统计分析,以检验行为分析得到的假设。如果简单地依据数据关系确定经济关系,显然是不正确的。数据之间存在统计相关关系,并不是存在经济关系的充分条件,而只是必要条件。李子奈(2008)列举了一个比较极端的例子。在一项关于我国农村居民消费影响因素分析的研究中,作者通过统计数据对城镇居民人均收入和农村居民人均消费两个时间序列数据进行了严格的统计检验。首先进行单位根检验,发现它们都是二阶单整序列。然后进行Granger因果关系检验,发现在5%的显著性水平上,城镇居民人均收入是农村居民人均消费的Granger原因。最后进行协整检验,发现它们之间存在(2,2)阶协整。于是据此将城镇居民人均收入作为农村居民人均消费的解释变量,得出了近乎荒谬的结论。这样的例子在我们目前的应用研究中并不少见。再列举一个错误不易被发现的例子,时间序列结构突变点的内生与外生问题。时间序列的结构变化是计量经济学应用研究中的一个普遍现象,它既是一个经济现象,也是一个统计现象。在时间序列分析中,将结构突变点外生,是从经济现象入手,然后用统计现象进行检验,将统计检验看作必要条件。近年来的许多应用研究将结构突变点内生,即从统计现象入手,然后用经济现象进行解释,将统计检验看作充分条件。结构突变点内生,从统计学方法技术上讲是先进的,但是从逻辑学上讲是存在问题的,误将必要条件作为充分条件。
另一个重要的问题是,用什么“变量”表征“因素”?经济系统的动力学分析,得到的只是“恒常的、显著的影响因素”。例如,资本和劳动是产出量的直接影响因素,收入和价格是需求量的直接影响因素。用什么“变量”来表征这些“因素”,并且作为解释变量引入模型?仍然需要依赖数据。根据数据的可得性和代表性原则,选择恰当的变量。例如,表征资本的变量应该是固定资本与流动资本之和,但是在很多情况下(例如以企业为研究对象)缺少流动资本的数据,只能采用固定资本,那么会带来什么问题?固定资本又有原值和净值之分,又应该如何选择?另外还大量涉及到总量与部分之间的选择问题,应该采用总量的必须采用总量,如果用部分代替总量,必须假设在所有的样本点上部分在总量中的比例是相同的,这又是一个需要利用数据进行检验的问题。
四、模型估计对数据质量的依赖性
确定了模型类型,并正确地完成了总体回归模型的设定,接下来的任务就是根据总体模型采集用于模型估计的样本数据。前述的关于我国广义技术进步对经济增长贡献的测算一例,已经说明了计量经济学模型的估计结果对样本数据质量存在着依赖性。
在20世纪80年代以前,国际统计界基本上是以提高数据准确性为出发点对数据质量问题展开研究,但是数据质量的内涵远超过单纯的数据准确的概念。之后,学者们更多地从数据使用者的角度去评判数据的质量,从而形成了数据质量的众多维度。李子奈(1992)将计量经济学模型的样本数据质量概括为一致性、完整性、准确性和可比性四个方面。⑨
所谓一致性,即母体与样本的一致性,样本必须是从母体中随机抽取的。在实际应用中,违反一致性的情况经常会发生。例如,用企业的数据作为行业生产函数模型的样本数据,用人均收入与消费的数据作为总量消费函数模型的样本数据,用31个省份的数据作为全国总量模型的样本数据,等等。
所谓完整性,即总体模型中包含的所有变量都必须得到相同容量的样本观测值。这既是模型参数估计的需要,也是经济现象本身应该具有的特征。但是,在实际中,“遗失数据”的现象是经常发生的。在出现“遗失数据”时,如果样本容量足够大,样本点之间的联系并不紧密的情况下,可以将“遗失数据”所在的样本点整个地去掉;如果样本容量有限,或者样本点之间的联系紧密,去掉某个样本点会影响模型的估计质量,则要采取特定的技术将“遗失数据”补上。
所谓准确性,有两方面含义,一是所得到的数据必须准确反映它所描述的经济变量的状态,即统计数据或调查数据本身是准确的;二是它必须是模型研究中所准确需要的,即满足模型对变量口径的要求。前一个方面是显而易见的,而后一个方面则容易被忽视。例如,在行业生产函数模型中,作为解释变量的资本、劳动等必须是投入到生产过程中的、对产出量起作用的那部分生产要素。以劳动为例,应该是投入到生产过程中的、对产出量起作用的那部分劳动者的实际劳动投入。于是,统计中的全体职工人数显然不能作为样本数据,尽管全体职工人数在统计上是很准确的,但其中有相当一部分与生产过程无关,不是模型所需要的。更严格讲,即使是与生产过程有关的那部分职工,也不宜直接作为样本观测值;作为样本数据的应该是他们的以劳动时间计量的实际劳动投入。如果不能得到这样的数据,而是以人数为观测值,相当于设置了一个很强的假设:在所有样本点上,每个职工实际投入的劳动(例如劳动小时)是相同的。
所谓可比性,也就是通常所说的数据口径问题,在计量经济学应用模型研究中可以说无处不在。而人们容易得到的经济统计数据,一般可比性较差,其原因在于统计范围口径的变化和价格口径的变化,必须进行处理后才能用于模型参数的估计。计量经济学方法,是从样本数据中寻找经济活动本身客观存在的规律性,如果数据是不可比的,得到的规律性就难以反映实际。正如前例所表示的,不同的研究者研究同一个经济问题,采用同样的变量和模型数学形式,选择的样本点也相同,但可能得到相差甚远的模型参数估计结果。为什么?原因在于样本数据的可比性。样本数据的可比性问题在截面数据模型中存在但不严重,在时间序列数据模型中十分普遍。例如,在前例的问题中,所建立的模型都是C-D型总量生产函数模型,选择的投入要素都是资本和劳动,数据都来自于中国统计年鉴。作为被解释变量的国内生产总值(GDP)一般采用按照不变价计算的数据,具有可比性;而劳动一般采用人数作为样本观测值,在不同的样本点上也具有可比性;如果固定资产原值(或者净值)数据是以资产形成年的价格计量的资产简单相加得到的,显然在不同的样本点上不具有可比性。于是不同的研究者采用不同的方法对固定资产原值(或者净值)数据进行调整,自然就会有不同的模型估计结果。
如何实现计量经济学模型样本数据的一致性、完整性、准确性和可比性?这些问题已经不完全属于统计学的范畴,而应该成为计量经济学应用研究本身的任务。改善数据质量和改善模型方法技术同等重要,前者甚至更加有效。而且只有认识到样本数据在质量方面存在的问题,才能有针对性地改善模型方法技术。
除了上述的四个方面以外,样本数据的结构变化或奇异点的诊断也对模型估计质量有重要影响。计量经济学模型方法是一种经验实证分析方法,试图从观测到的局部、特殊出发,经过抽象和假设,再经过检验,得到能够覆盖时序上所有时点或截面上所有个体的一般性法则。那么,对于观测到的时间序列的结构变化或者截面上的奇异点(为了方便,下面统称为奇异点),就有两种情况:从经济行为上可以解释和无法解释。例如自然灾害、战争等原因造成的经济时间序列中的奇异点,在经济行为上是可以解释的;而由于统计或调查的失误、道德问题,以及行为的极端非理性等原因造成的经济时间序列或截面数据中的奇异点,在经济行为上是无法解释的。凡是在经济行为上可以解释的奇异样本,在计量经济学模型估计过程中被建议保留,通过模型技术的改进加以消除,使之对一般性法则不产生影响,甚至它本身就是一般性法则的一部分;凡是在经济行为上无法解释的奇异样本,在计量经济学建模过程中被建议剔除,包括直接剔除或者通过引入毫无实际意义的虚拟变量加以消除。对于建模者而言,首先是必须从样本数据中发现奇异点,这就是数据诊断的任务。关于样本数据中奇异点的诊断,国内外学者已经进行了广泛的研究。例如赵进文(2000)、周建(2005)在数据诊断理论方法领域的研究成果,具有很好的应用价值。⑩(11)但是,在计量经济学应用研究中却经常被忽视。
五、模型应用对外生想定数据的依赖性
计量经济学模型的应用大体包括四个方面:结构分析、理论检验、经济预测和政策评价。如果将模型用于经济预测和政策评价,那么预测的结果和评价的结论除了依赖正确的模型外,还依赖于想定的外生变量值或者政策方案,它们都以数据的形式出现,一般统称为“想定数据”。那么就提出一个问题:什么数据是可以被准确“想定”的,什么数据是不可能被准确“想定”的?

模型中的“强外生性”变量不可能同时具有“超外生性”。而在我们已有的应用研究中,既用于预测又用于政策评价的模型却屡见不鲜。
六、结论与启示
前面讨论的问题,看上去都是很浅显的,但是却是目前我国计量经济学应用研究中最为严重的问题之一。数据问题,不是统计学的任务,而是计量经济学的任务。一项计量经济学应用研究课题,或者一篇计量经济学应用研究论文,必须将相当大部分工作或者相当大部分篇幅放在数据的采集和处理方面。否则研究课题是不可能成功的,研究论文也是没有价值的。计量经济学课程教学,必须将模型对数据的依赖性问题作为重要的教学内容,否则,学生学了一堆模型理论方法也是无法正确应用的。
强调计量经济学模型对数据的依赖性,也要避免模型研究掉入“数据陷阱”之中。社会经济数据是社会经济活动状态的表征,客观性是其最重要的属性,必须是真实、客观地反映事物的本来面目,不能有任何随意的假定、推测和想象。这样的数据是模型研究者可资依赖的。如何判断数据是否具有客观性?如前所述,已经有大量的数据诊断理论与方法可资采用。但是这些诊断方法仍然是基于数据的,主要利用数据的“关联性”属性。也就是说,用数据的“关联性”诊断数据的“客观性”。问题是明显存在的。所以,一个十分重要的启示是,模型研究者必须首先对客观的社会经济活动进行观察和分析,获得“感觉”。那些不进行任何调查研究,以通过某种渠道获得的“数据库”作为研究的起点,是很容易掉入“数据陷阱”之中的。这是“数据陷阱”在计量经济学模型研究中的第一个表现,也是当前严重存在的问题之一。例如前述的农户借贷数据,如果不进行亲身调查,只面对数据库,就不可能发现这样的事实:实际借贷额为0的数据并不是农户借贷需求小于等于0的真实反映。
“数据陷阱”在模型研究中的第二个表现是实用主义倾向。数据是客观的,但是被主观地选择使用。研究者往往按照自己的研究目的和希望得到的结论去选择数据,而在研究报告或者论文中将选择过程隐去,给人一种很“客观”的印象。为什么同样的问题,不同的研究者会得到不同的结论,这是原因之一。
注释:
①李子奈:《计量经济学模型方法论的若干问题》,《经济学动态》,2007年第10期。
②李子奈:《计量经济学应用研究的总体回归模型设定》,《经济研究》,2008年第8期。
③Heckman J. J.(1974), " Shadow prices, market wages and labour supply", Econometrica 42(4): 679-694.
④Heckman, J. J.(1979), "Sample selection bias as a specification error", Econometrica 47(1): 153-161.
⑤McFadden, D. L.(1974), "The measurement of urban travel demand", Journal of Public Economics(3): 303-328.
⑥Granger, C. W. J. & P. Newbold(1974), "Spurious regressions in econometrics", Journal of Econometrics(2): 111-120.
⑦Engle, R. F. & C. W. J. Granger(1987), "Co—integration and error correction: Representation, estimation and testing", Econometrica 55: 251-276.
⑧Cheng Hsiao(2003), Analysis of Panel Data, Cambridge University Press.
⑨李子奈:《计量经济学——方法与应用》,清华大学出版社1992年版。
⑩赵进文:《经济计量诊断学》,天津人民出版社2000年版。
(11)周建:《宏观经济统计数据诊断理论方法及其应用》,清华大学出版社2005年版。
【原文出处】《经济学动态》(京)2009年8期第22~27页
【作者简介】李子奈,清华大学经济管理学院