马键/王美今
【内容提要】
最近实证博弈研究的迅速发展为市场中的策略互动、政策分析和反事实实验提供了有效的工具。本文提出一种估计不完全信息连续策略博弈的两阶段方法,它可以处理私有信息的影响。第一阶段通过非参数分位数回归估计局中人的策略与期望支付函数;第二阶段利用贝叶斯一纳什均衡不等式构造模拟最小距离估计量,最终获得结构参数的估计。数值模拟显示本方法有良好的小样本表现。与现有文献的嵌套固定点方法相比,本方法不需计算均衡,极大降低了计算量,并减轻了多重均衡的干扰。本方法既可以用于估计离散状态博弈,也适用于连续状态博弈。
【关 键 词】连续策略博弈/两阶段估计方法/非参数分位数回归/模拟最小距离估计
一、前言
2009年1月,工信部发放三张第三代移动通信(
新近兴起的实证博弈研究对此提供了一个分析思路。这类研究结合博弈理论与计量方法,用于政策分析和反事实实验,已成为计量与应用经济学研究的一个热点,尤其在新实证产业组织(New Empirical Industrial Organization)研究中得到广泛的应用。其话题涵盖广告战、合谋、干中学(Learning-by-doing)、兼并、网络效应、研发等等。例如,Jenkins, Liu, Matzkin et al.(2005)[1]研究微软与网景之间的“浏览器战争”,估算出在微软的一系列“恶意竞争行为”中,捆绑IE浏览器对网景的伤害最大,造成约3.69亿美元的损失。Ryan(2006)[2]分析一项环保修正案对美国波特兰地区水泥产业的影响。与环境规制对企业不利的常识相反,他发现该法案增加了进入水泥行业的成本,反而增强了现有水泥厂的市场势力。
实证博弈研究的主要内容有两方面。一方面,研究者需要从观测数据中提取信息,估计模型的结构参数。另一项任务是计算均衡,以便进行预测或政策模拟。本文主要探讨估计问题。
一种直观的估计方法是嵌套固定点法,由Rust(1987)[3]首先提出①。其缺点是需要多次进行耗时的均衡计算,并且需要从多重均衡中挑选实际发生的均衡。由于这两点,在实证研究中实现该算法相当困难。
最近一些文献②提出的两阶段估计策略③避免了计算均衡,从而解决了这一难题。它们的实现过程与适用范围各有不同,但都可分为两个步骤。第一步,用非参数方法估计局中人的策略函数、支付函数与状态转移概率。第二步,把第一步的结果代入博弈的均衡,理性化局中人行为以估计结构参数。Ryan(2006)[2]贴切地用“What”与“Why”描述这两步:“第一步,……简单地描述了在不同的状态下,企业在做什么。第二步,……复原参数,解释企业为什么这样做。”这一估计思想最早见于Hotz and Miller(1993)[4]。
有时局中人的选择是离散集,例如在位者——进入者博弈;更多的时候则需考虑连续策略,譬如企业在决定产量、设定价格或投资研发时。一种处理连续策略的方法是离散化,例如Pakes, Ostrovsky and Berry(2007)[9]的市场进入模型把进入者的初始投资离散化为多重进入位置(Multiple Entry Locations)。对更复杂的博弈,这种办法效果不佳。Benkard, Bajari and Levin(2007)[8]提出一种估计连续策略博弈的方法。在他们的模型中,私有信息只影响策略的离散部分(进入及退出),不影响策略的连续部分(投资)。该文采用局部线性方法估计投资策略。Ryan(2006)[2]则用参数化的(S,s)规则估计投资策略。由于均衡策略与市场结构的关系通常是非线性的,参数化方法可能存在模型误设。
本研究考虑了私有信息影响连续策略这一更为实际的情形。在这种情况下,由于连续策略函数的部分解释变量不可观测,因此通常的非参数方法—例如Benkard, Bajari and Levin(2007)[8]的局部线性方法——不再适用。为了解决这一问题,本文采用非参数分位数回归估计策略函数。这使得模型既容许私有信息影响策略的连续部分,又避免了模型误设。其实现过程如下:首先用非参数分位数回归估计局中人的策略函数,并对给定的参数,通过模拟积分计算期望支付函数。然后把估计的期望支付函数代入贝叶斯—纳什均衡不等式,用模拟最小距离方法估计结构参数。与离散策略博弈相比,估计连续策略博弈存在几点困难。其期望支付函数依赖于未知的结构参数,给定结构参数,又需要对收益函数做多重积分,不像离散策略博弈可利用Hotz and Miller(1993)[4]的CCP(Conditional Choice Probability)方法方便地予以计算;此外,连续博弈估计算法的实现较复杂,不像离散策略博弈的估计过程可通过向量化转化为易于实现的矩阵运算。例如Bajari, Hong, Krainer et al.(2009)[7]提出一种可用STATA等标准统计软件实现的算法。
本文的章节安排如下。第二节设定博弈模型、定义均衡;第三节讨论模型的识别条件与估计过程,其中着重分析了多重均衡的影响;第四节以寡头古诺模型为例,通过蒙特卡洛实验检验该估计量;最后是全文的总结。
二、理论模型
(一)模型设定



达到均衡时,每一位局中人关于其他局中人行动的信念与其真实策略相吻合,或者说每一位局中人都正确地预测到其他人的行为模式。因此有如下的均衡定义。
定义1给定状态s与个体冲击ε,模型的贝叶斯—纳什均衡策略是同时满足下述N个方程的向量值函数σ(s,ε):

与基于选择(行动)的值函数相对,上式称为状态收益函数或事前收益函数(Ex ante Value Function)。二者的区别类似于消费者理论中直接效用函数与间接效用函数的区别。
对研究者而言,估计模型参数时可以不考虑信念的形成机制,仅假定局中人理性,且均衡已达到。因此有另一种等价的均衡定义。

成立,则称模型达到贝叶斯—纳什均衡,相应的策


三、两阶段估计
(一)多重均衡
估计模型之前,有必要先对多重均衡问题作一讨论。满足不等式(1)或(3)的均衡策略口可能不唯一,即多重均衡。它是博弈中一个普遍的现象,给均衡计算与模型估计带来许多困难。通常对具有单一均衡的模型可通过构造压缩映射,反复迭代计算其均衡;对多重均衡模型则可以利用连续同伦方法(Homotopy Continuation Method)计算不同的均衡;对于一般化的博弈模型,目前还没有方法可计算出全部的均衡或确定均衡的数目(Doraszelski and Pakes(2007)[13])。
多重均衡对模型估计的影响是多方面的。第一个问题在于数据生成过程(DGP)。多重均衡导致同一样本中不同的观测可能源于不同的均衡,而研究者无法区分哪一次观测来自哪一重均衡。为了避免这一问题,本文假定
假定1均衡选择假定:DGP生成的样本数据来源于同一个均衡。
这一假定容许模型存在多重均衡,但要求DGP有一致的均衡挑选机制。Aguirregabiria and Mira (2007)[5]等⑧有相同的假定,Aguirregabiria and Mira(2008)[14]则提出一种放松假定1的估计方法。
即使DGP满足假定1,多重均衡仍给均衡的计算带来困难,使模型难以预测。假设研究者知道模型参数,并能计算出全部的均衡,但究竟哪一个均衡会发生是难以预测的。由于这一原因,使得任何需要计算均衡的估计方法—例如嵌套固定点方法—难以实现。若采用嵌套固定点方法估计模型,在存在多重均衡时,研究者难以判断把哪一个均衡带入目标函数。更糟糕的是,由于嵌套固定点方法需要计算一族博弈的均衡,即使真实的模型不存在多重均衡,估计过程仍可能遇到多重均衡。本文的两阶段估计策略不需计算均衡,因此避免了挑选均衡的难题,这是该方法的最大优点之一。
(二)第一阶段:估计策略函数并计算期望支付函数
第一阶段估计的目的是从观测到的局中人行为推断局中人的均衡策略函数与支付函数,解决Ryan所说的“What”问题。本文假定研究者可以观测到局中人所处的状态,以及在该状态采取的行动,但观测不到局中人的收益,即研究者拥有(a,s)的数据。在产业组织研究中,这意味着企业的市场势力、生产能力或技术水平等状态变量是可观测的,企业的投资、广告等行为也可以观测到。这一假设由离散选择模型扩展而来,被许多文献采用。利用a|s的经验分布,研究者就可以估计出局中人的策略。
估计模型的第一个问题是识别。本模型的识别包含两个方面,第一阶段的估计要求收益函数可识别,第二阶段的估计则需结构参数可识别。下文先讨论收益函数的识别,结构参数的识别留待下一小节讨论。由于局中人依据收益的相对大小采取行动,因此缩放收益函数不会改变局中人策略。又因观测数据中只包含行动而没有收益,因而收益的绝对大小无法识别。需对收益函数进行标准化,以保证它可识别。本文的处理是标准化个体冲击。
另一个问题是上文没有限定收益函数的具体函数形式。有些函数不具有好的状态—行为关系,不适合作为收益函数。一个极端的例子是常数收益函数,它对应的均衡策略是整个行动集。下述假定可保证收益函数具有良好的性质。

这一假定由Benkard,Bajari and Levin(2007)[8]提出,适用于连续策略博弈。此前在离散策略博弈研究中,通常假定个体冲击关于不同的局中人以及同一局中人的不同行动独立分布。再结合加性可分(Additive Separability)假定,可保证个体冲击的确影响局中人决策。但连续策略博弈的行动集并非有限集,因此无法套用这两个假定。


Ackerberg,


至此已得到结构参数的估计,还需进一步计算标准误。上述估计过程中的误差来源有三处。首先,第一阶段的非参数分位数回归会产生误差。其次,用模拟积分计算期望收益函数会引起误差。最后,在模拟最小距离估计中,用抽样的有限个均衡不等式代替无穷多的均衡条件也会带来误差。最终参数估计的误差由这三部分误差累积而成。Benkard, Bajari and Levin(2007)[8]证明,如果在第一阶段获得策略函数的一致且渐进正态的参数估计,则第二阶段的模拟最小距离估计是一致且渐进正态的,该文亦求得此时估计量的渐进方差矩阵。对于策略函数的估计是非参数的情形,这一模拟最小距离估计的大样本性质仍未得到合适的证明。由于最终的参数估计的误差组成比较复杂,在实证研究中,采用Bootstrap或Subsampling方法计算标准误较为简便实用。
四、蒙特卡洛实验
为了检验这一估计方法,本节以寡头古诺模型为例,进行蒙特卡洛实验。具体模型如下。

其中i=1,2,…,N。上式代入式(13),即可算出单次博弈的支付,积分即得期望支付函数。有一点需要说明,在估计过程中,研究者只知道利润函数式(13)的函数形式,而不知道均衡产量式(14)的函数形式。实际上,在实证研究中,多数情况下均衡策略函数是没有解析形式的。这也是两阶段估计的第一阶段通常为非参数估计的原因。
下面估计这一古诺模型。为了考察不同样本容量下本估计方法的表现,分别设T={50,100,200,400},每种情况各进行500次实验。所有实验均采用同一DGP。在一次实验中,首先由DGP随机生成含T个观测的样本数据,再用两阶段法估计此样本的结构参数。重复这一过程,得到500个参数的估计。最后计算这些参数估计的均值、RMSE(Root Mean Square Error)与置信区间等统计量。
详细的参数设定如下。设市场中有N=2家企业,分别记为i=1,2。记t=1,2,…,T代表不同的观测。设定模型参数
均衡产量数据
程序实现采用Matlab软件,估计过程中有几点细节需稍加说明。对于式(6)的分位数回归,由于检查函数不光滑,拟牛顿法等优化方法失效,因此本文采用免梯度(derivative-free)的单纯形搜索方法(Simpkx Search Method)求解最优化问题。回归采用标准正态核,带宽由拇指规则确定。式(8)的模拟积分采用对偶抽样以加速收敛。模拟积分次数由研究者自主决定,本文分别设为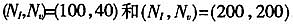
表实验结果

实验结果见下表,表中列有参数估计的均值、RMSE、5%和95%分位点。从中可见,此估计有良好的小样本表现。先观察参数几的估计。对于(100,40)的情况,样本容量为50时均值略偏小,随着样本增大逐渐贴近真值。RMSE不断减小,置信区间也越来越窄。对于(200,200)的情况,样本容量为50时估计的均值略微偏大,随着样本量增大逐渐减小。RMSE与置信区间也不断减小。α估计的变化趋势与之相似。略有不足的是,在样本容量是400时,参数
五、结论
本文提出一种不完全信息连续策略博弈的两阶段估计方法。与现有文献相比,该方法有几点优势。首先,本文通过第一阶段的非参数分位数回归,可以处理私有信息影响策略连续部分的情形。在分析企业的投资或定价行为时,忽略这一影响可能会导致错误的结果。其次,本估计方法仅对模型施加很少的约束,只要求满足均衡选择假定、单调选择假定与模型可识别,并未限定具体函数形式,因此适用范围较广。再次,本方法不需计算均衡,可大大节省计算时间,并减轻了多重均衡对估计的影响。最后,本方法既适用于离散状态博弈,也适用于连续状态博弈。
文中仍有一些问题有待解决。模拟实验表明这一估计有良好的小样本表现,但由于估计过程比较复杂,其大样本性质仍未得到合适的证明。对第一阶段有一致且渐进正态(CAN)的参数估计的情况,Benkard, Bajari and Levin(2007)[8]证明其渐进分布是CAN的。但对非参数的第一阶段,其大样本性质如何仍需进一步研究。
本文的写作得到斯坦福大学洪瀚教授的启发与指导,在此表示真诚的感谢。作者还要感谢匿名审稿人的建设性评论与建议。当然,文责自负。
注释:
①Rust(1987)[3]及下文提到的Hotz and Miller(1993)[4]的研究内容均为单体规划,并非多体博弈。
②包括Aguirregabiria and Mira (2007)[5]、Bajari, Chernozhukov, Hong et al.(2009)[6]、Bajari, Hong, Krainer et al.(2009)[7]、Benkard, Bajari and kevin (2007)[8]、Pakes, Ostrovsky and Berry(2007)[9]等。
③Ackerberg,
④一些文献提出几种方法处理这种相关。例如Aguirregabiria and Mira(2007)[5]容许存在观测不到的固定效应,Bajari, Hong, Krainer et al.(2009)[7]则引入市场波动(影响支付的)效应(Market Specific Payoff Effect)。
⑤下文交替使用收益、利润、效用或支付的说法表示局中人所得。
⑥Bajari, Hong and Ryan (2008)[12]考虑了混合策略。
⑦为简洁起见,此处及后文在不影响文意时将略去表达式中的θ。
⑧例如Aguirregabiria and Mira (2007)[5]、Benkard, Bajari and kevin (2007)[8]、Pakes, Ostrovsky and Berry (2007)[9]、Bajari, Chernozhukov, Hong et al.(2009)[6]、Bajari, Hong, Krainer et al.(2009)[7]等。
⑨参见Li and Racine(2007)[15]。
⑩即使结构参数不可识别,也可以从
(11)Pakes, Porter, Ho et al.(2006)[16]对此有更详细的讨论。
(12)例如Benkard, Bajari and kevin (2007)[8]、Bajari, Hong, Krainer et al.(2009)[7]、Ryan(2006)[2]。
(13)这一假定是为了便于在DGP中计算均衡的解析解,并不影响模型估计。
(14)计算过程较繁琐,这里省略,有兴趣的读者可通过电子邮件向作者索取。
(15)这与前文略有不同。前文的反需求函数中α前是减号,编程时写作加号,因此相差一个负号。
【参考文献】
[1]M Jenkins, P Liu, R Matzkin, et al. The browser war: Econometric analysis of Markov perfect equilibrium in markets with network effects[J]. Unpublished manuscript,
[2]S Ryan. The costs of environmental regulation in a concentrated industry[J]. Working paper, 2006.
[3]J Rust. Optimal replacement of GMC bus engines: An empirical model of Harold Zurcher [J]. Econometrica: Journal of the Econometric Society, 1987: 999-1033.
[4]V Hots and R Miller. Conditional choice probabilities and the estimation of dynamic models [J]. The Review of Economic Studies, 1993: 497-529.
[5]V Aguirregabiria and P Mira. Sequential Estimation of Dynamic Discrete Games[J]. Econometrica, 2007, 75(1):1-53.
[6]P Bajari, V Chernozhukov, H Hong, et al. Nonparametric and Semiparametric Analysis of a Dynamic Discrete Game[J]. Manuscript,
[7]P Bajari, H Hong, J Krainer, et al. Estimating static models of strategic interaction[J]. NBER Working paper, 2009.
[8]C Benkard, P Bajari, and J Levin. Estimating dynamic models of imperfect competition[J]. Econometriea, 2007, 75: 1331-1370. [9]A Pakes, M Ostrovsky, and
[10]D Ackerberg, L Benkard,
[11]A Gallant, H Hong, and A Khwaja. Estimating a dynamic oligopolistic game with serially correlated unobserved production costs[J]. Working paper, 2008.
[12]P Bajari, H Hong, and S Ryan. Identification and estimation of discrete games of complete information [J]. NBER Working paper, 2008.
[13]U Doraszelski and A Pakes. A framework for applied dynamic analysis in IO[J]. Handbook of industrial organization, 2007(3):1887-1966.
[14]V Aguirregahiria and P Mira. Structural Estimation of Games when the Data Come from Multiple Equilibria [J]. Working paper, 2008.
[15]Q Li and J
[16]A Pakes, J Porter, K Ho, et al. Moment inequalities and their application[J]. Unpublished Manuscript, 2006.^
【原文出处】《统计研究》(京)2010年6期第87~94页
【作者简介】马键,男,新疆乌鲁木齐人,中山大学岭南学院在读博士生,研究方向:计量模型及其应用;
王美今,女,福建厦门人,中山大学岭南学院教授、博士生导师,研究方向:计量模型及其应用、金融市场与投资。