李宝月/金欢/罗剑锋/姜庆五/赵耐青
【内容提要】
目的本次研究以第三次全国血吸虫病流行病学调查为背景,对其部分抽样过程进行计算机模拟,采用负二项分布抽样方法,得到感染率的无偏估计,并与传统的抽样方法比较,综合评价两种抽样方法的优缺点。方法分别在样本量相同及样本量不同两种情况下对抽样结果估计感染率的绝对误差、相对误差及正确率作统计学描述分析,并综合评价。结果在相同样本量下,两种抽样方法估计的感染率在绝对误差、相对误差、正确率及可信区间宽度方面差别的P值均大于0.05(当感染率为0.6%时,两者的正确率及可信区间宽度差别P值接近0.05);在样本量不同时,两种抽样方法估计的感染率在正确率方面差异无统计学意义(P值均大于0.05),在绝对误差、相对误差及可信区间方面差别的P值均小于0.01,仅在感染率较高时(大于10%)两者差异无统计学意义。结论在样本量一致情况下,两种抽样方法在不同的感染率范围内的估计精度相当。当实际感染率较小时(如小于1%),采用负二项分布抽样可实现抽到足够的患者;当实际感染率未知且无法预测时,该方法又是一种探索性的抽样方法。
【关 键 词】负二项分布/血吸虫感染率/随机模拟
一、研究背景
卫生部分别于1989、1995和2004年开展了第一、二、三次全国血吸虫病流行病学抽样调查,为防治规划提供了科学依据。第三次全国血吸虫病抽样调查,采取分层、整群、随机抽样方法,在抽样范围内抽取样本村作为调查点。抽样范围:湖北、湖南、江西、安徽、江苏、四川和云南七省中,未达到传播阻断标准乡镇的所有流行村。第一亚层:在抽样范围内,根据流行类型划分为8个不同层次:湖沼型流行区湖汊亚型、洲滩亚型,洲垸亚型、垸内亚型,水网型流行区水网亚型,山丘型流行区丘陵亚型、高山峡谷亚型、平坝亚型。第二亚层:在第一亚层的基础上,根据流行区县(市、区)血防所(站)的最近一次查病结果、钉螺分布现状以及多年血防信息的感染率粗略预估计,将各流行村的居民血吸虫估计感染率分为<1%、1%~、5%~、10%~等4个层次。各省每个第二亚层随机抽100个抽样点(行政村),每个抽样点随机抽1000人,并收集人口学资料,并用下列公式估计感染率[1]。
样本点的粪检感染率估计的基本公式


由于一些村的感染率的粗略预估计值远离实际的感染率,造成两种情况:抽样点的实际感染率远大干预估计值,样本量会相对太大而浪费资源;另一种情况是抽样点的实际感染率远低于预估计值,会出现因样本量太小而导致感染率估计的抽样误差大大增大。针对上述实际问题的方法,笔者建议采用负二项分布抽样的方法解决上述问题,推导出负二项分布的感染率无偏估计的公式及方差估计的公式,并用随机模拟比较负二项分布抽样与传统抽样方法的抽样误差情况。
二、方法
(一)负二项分布定义[2]
假定:
1.每次试验的可能结果只有二个:可以归结为成功或失败。
2.每次试验之间是独立,每次成功的概率均为π。
3.第r次成功的试验次数为N,则N的概率分布为


对于实际感染率低于预计时的感染率时,由于以达到预定感染人数为停止抽样准则,所以采用负二项分布的方式抽样,可以证明:不会导致估计误差增大,并且能够根据实际感染情况自动调节抽样人数,保证感染率的估计精度。
根据感染率估计π和95%可信区间的宽度,估计样本量n,并得到估计的感染人数期望值r=nπ,采用抽样的感染阳性人数达到预定的阳性人数,停止抽样。
在这种抽样中,阳性人数不是随机变量,抽样人数是随机变量,描述这样的随机变量可以归结为负二项分布(亦称巴士卡分布)。
三、随机模拟的结果
模拟试验设计:
1.感染率分别为0.6,1%,2.5%,5%和10%,预定阳性人数分别取6,10,25,50,100。先采用负二项分布抽样,得到样本量,再以此样本量用传统方法进行抽样,从而实现两种抽样方法的样本量一致,比较两种抽样方法估计感染率的绝对误差,相对误差和正确率,见表1~表3。
2.每一亚层感染率范围分别为:0.6%~1%,1%~5%,5%~10%,10%~12%,传统抽样方法在每个感染率范围内样本量均为1000,采用负二项分布方法,其患者数为96,96,92,122。比较两种抽样方法估计感染率的绝对误差,相对误差,正确率和95%可信区间平均宽度,见表4~表6。患者数具体计算方法为:

表1固定感染率相同样本下估计感染率的绝对误差|p-π|×100%
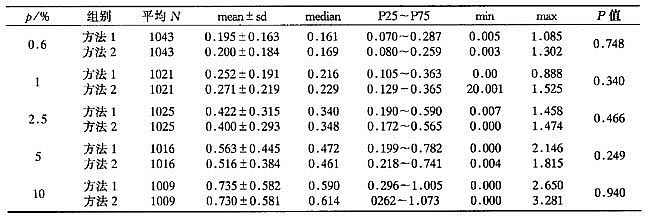
*:方法一为传统的抽样方法,方法二为负二项分布抽样方法,下同。
表1为固定各亚层的感染率,每一亚层抽相同样本量,采用两种方法,计算估计感染率绝对误差的均值、标准差、中位数、四分位数间距、最大值、最小值等进行比较。
表2固定感染率相同样本下估计感染率的相对误差|p-π|/π×100%
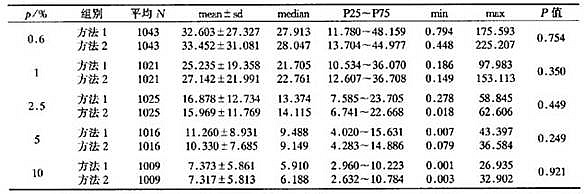
表2为固定各亚层的感染率,每一亚层抽相同样本量,采用两种方法,计算估计感染率相对误差的均值、标准差、中位数、四分位数间距、最大值、最小值等进行比较。
表3固定感染率相同样本下估计感染率的正确率及可信区间平均宽度比较(200次)

正确率:200次抽样中,估计感染率的95%CI包含实际感染率的百分比。
表3为固定各亚层感染率,每一亚层抽相同样本量,采用两种方法所得的估计感染率的正确率比较及估计感染率的95%CI平均宽度。
表4为当各亚层感染率在一定范围内浮动时,采用两种抽样方法,所得的样本量及估计感染率绝对误差的均数、标准差、中位数、四分位数间距、最大值、最小值等的比较。
表5为当各亚层感染率在一定范围内浮动时,采用两种抽样方法,所得的样本量及估计感染率相对误差的均数、标准差、中位数、四分位数间距、最大值、最小值等的比较。
表4不同亚层下估计感染率的绝对误差|p-π|×100%

表5不同亚层下估计感染率的相对误差|p-π|×100%
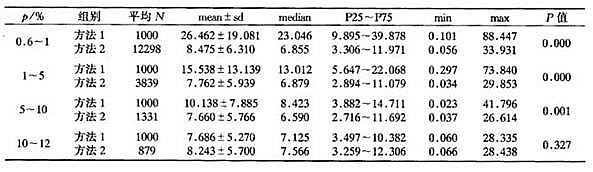
表6不同亚层下估计感染率的正确率比较(200次)
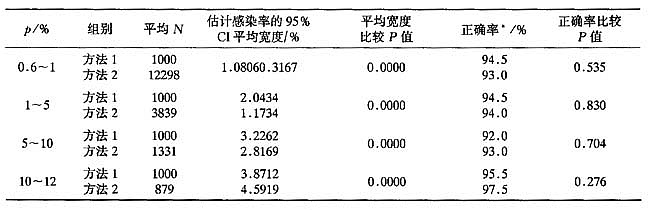
*正确率:200次抽样中,估计感染率的95%CI包含实际感染率的百分比。
表6为当各亚层感染率在一定范围内浮动时,采用两种抽样方法所得的估计感染率的正确率比较及估计感染率的95%CI平均宽度。
四、讨论
1.在感染率相同并且样本量一致的情况下,传统抽样方法与负二项分布抽样估计感染率的绝对误差和相对误差在均数、中位数、四分位数及最大值最小值方面均无明显差异,其正确率差别也没有统计学意义。因此,总体来说,在样本量一致情况下,两种抽样方法的估计精度相当。
2.结合第三次全国血吸虫病流行病学调查,当各亚层感染率在一定范围内浮动时,尤其在感染率较低情况下,采用传统的抽样方法,样本量均取1000是不够的,其绝对误差和相对误差较大,估计感染率的95%CI平均宽度也超过了可以接受的范围(感染率较低时尤为明显,如感染率范围为0.6~1%,估计95%可信区间宽度为1.08%,估计精度很低。);而采用负二项分布抽样,按照预计的容许误差计算样本量,其估计感染率的绝对误差和相对误差均较小(如在感染率为0.6~1%,其估计感染率的绝对误差为0.068±0.052,相对误差为8.475±6.31,远远小于传统抽样方法的0.208±0.15和26.462±19.081),估计精度也较高(同样在感染率为0.6~1%范围内,其估计感染率95%可信区间宽度仅为0.32%),可以看出,这主要是由于负二项分布抽样选择了更加合适的样本量。在感染率较低的情况下,由于负二项分布抽样的实际样本量远远超过第三次全国血吸虫病流行病学调查方案所制定的每个自然村的调查人数1000人,因此对于低感染率地区感染率的调查和感染人数的估计可能会有较大的误差。
3.在实际抽样中,感染率往往是未知的,有时尚无法预测,因此,采用传统的抽样方法即固定抽样人数有时是不合理的,尤其当实际感染率较低时,往往抽不到患者;而实际感染率较高时,又会因样本量过大而浪费人力物力。采用负二项分布抽样则可相对弥补以上缺点,能够保证在低感染率下抽到足够患者,使样本量随实际感染率变化而变化,实现资源的优化配置。
综上,在样本量一致情况下,两种抽样方法在不同感染率范围内的估计精度相当。当实际感染率可以预测时,负二项分布抽样在较低感染率下可保证有足够患者被抽中;当感染率不可预测时,负二项分布抽样又是一种探索性的抽样方法。
【作者简介】李宝月金欢罗剑锋姜庆五赵耐青上海复旦大学公共卫生学院卫生统计与社会医学教研室,上海200032