内容提要:在使用多个分类变量对样本进行交叉事后分层时,边缘总值已知、格子总值未知的不完全事后分层问题是估计时经常面临的情况。序贯调整估计量是本论文提出的解决这一问题的新方法。在详细介绍了序贯调整估计程序后,论文用随机模拟的方法研究了该估计量的数学性质,并将其与经典的不完全事后分层估计量做了比较。
关键词:不完全事后分层 搜索比率估计量 广义搜索比率估计量 序贯调整估计量
作者简介:钟卫中国人民大学财政金融学院,北京100872;袁卫中国人民大学应用统计研究中心,北京100872;黄向阳中国人民大学统计学院,北京100872
前言

完全事后分层的估计量比较简单,一般都会使用 作为权数对变量进行加权,但对于不完全事后分层而言,由于
作为权数对变量进行加权,但对于不完全事后分层而言,由于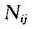 是未知的,估计起来就要麻烦一些。对于这一问题的讨论始于Deming和Stephan(1940),在这之后有大量的文献都对这一问题进行了阐述。综合这些文献,可以认为,对于不完全事后分层的估计主要使用了两个估计量:搜索比率估计量(Raking Ratio Estimators)(Deming, 1943; Stephan, 1942; Ireland & Kullback, 1968; Arora & Brackstone, 1977a, 1977b; Brackstone & Rao, 1979; Oh & Scheuren, 1987; Binder & Theberge, 1988)和广义搜索比率估计量(Generalized Raking Ratio Estimators)(Deville & Saimdal, 1992: Deville, Saimdal & Sautory, 1993; Singh & Mohl, 1996; Th6berge, 1999;金勇进、张琅,2002[14])。有关经典的不完全事后分层估计方法的总结见钟卫、袁卫(2006)[16]。
是未知的,估计起来就要麻烦一些。对于这一问题的讨论始于Deming和Stephan(1940),在这之后有大量的文献都对这一问题进行了阐述。综合这些文献,可以认为,对于不完全事后分层的估计主要使用了两个估计量:搜索比率估计量(Raking Ratio Estimators)(Deming, 1943; Stephan, 1942; Ireland & Kullback, 1968; Arora & Brackstone, 1977a, 1977b; Brackstone & Rao, 1979; Oh & Scheuren, 1987; Binder & Theberge, 1988)和广义搜索比率估计量(Generalized Raking Ratio Estimators)(Deville & Saimdal, 1992: Deville, Saimdal & Sautory, 1993; Singh & Mohl, 1996; Th6berge, 1999;金勇进、张琅,2002[14])。有关经典的不完全事后分层估计方法的总结见钟卫、袁卫(2006)[16]。
本论文将针对不完全事后分层问题提出一个新的估计量——序贯调整估计量,并给出序贯调整估计程序,这是第1部分的内容;第2部分是通过随机模拟的方法研究序贯调整估计量的性质;第3部分比较序贯调整估计量与经典的不完全事后分层估计的性质:第4部分是结论。
一、序贯调整估计量构造介绍
序贯调整估计量(Sequential Adjustment Estimators,简记作SAE)是借助序贯调整估计程序来实现的,其程序大体上分为两步:第一步是建立能较好代表总体结构特征的配额抽样框;第二步是利用该抽样框,重复、随机地从给定的母样本中抽取子样本,然后利用这些子样本构造估计量和方差的估计量。序贯调整估计量的具体构造过程如下:


这里解释一下序贯调整估计量的含义。“序贯调整”的概念来源于沃尔德1940年提出的序贯分析(袁卫等,1999)的思想。和古典统计不同的地方在于,序贯分析对样本的容量事先不做规定,而是按第一、第二的顺序逐个抽出检验。然后将每个观察值的信息累加起来,直到累加的信息能够做出接收或拒收的决定时为止。将此思想用在本论文中,就是先找出并删除样本中“受污染”最严重的单元,并就调整后的样本分布与已知总体的分布做 拟合优度检验。如果拒绝了原假设,则重复上述过程直至最终做出了接收的决定。
拟合优度检验。如果拒绝了原假设,则重复上述过程直至最终做出了接收的决定。
二、用模拟的方法研究序贯调整估计量
序贯调整估计量是一个新方法,短期内对估计量的无偏性、有效性等数学性质进行证明不是一件容易的事。因此,笔者尝试用随机模拟的方法来研究这个新的估计量。
(一)构造已知总体
不妨假设有限总体U的单元数目N=100000,每个单元具有两个反映其特征的分类辅助变量,其中,第一个辅助变量分成4类,第二个辅助变量分成5类。在两个辅助变量不独立(注:如果两个辅助变量相互独立,则有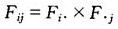 ,其中,
,其中,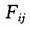 表示总体的两个辅助变量在第i行、第j列的频率。这是一种特殊的情形,这里不做考虑。)时,假设虚构的总体列联表如表1所示。
表示总体的两个辅助变量在第i行、第j列的频率。这是一种特殊的情形,这里不做考虑。)时,假设虚构的总体列联表如表1所示。

因为研究变量与分类辅助变量间存在一定的相关关系(否则就没有必要进行分层或者事后分层),我们不妨假定每个格子内的研究变量y服从均值和方差都不相同的正态分布。表2和表3分别给出了表 1中每个格子内研究变量y的均值和标准差。
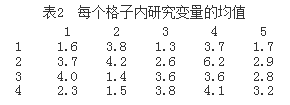
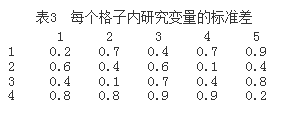
在有了每个格子内研究变量y的分布后,我们就可以对每个格子按照表1指定的频数产生随机数,将所有这些随机数放在一起构造研究总体,并计算该总体的均值和标准差。因为每个格子内的单元是随机产生的,因此总体的均值和标准差也不是固定,但相差不大。在进行程序模拟时,我们是对一个均值μ=3.1512、标准差σ=1.4675的确定总体进行研究的。
(二)随机模拟
对按照上述方法构造的已知总体,采用简单随机有放回抽样的办法,从中反复地抽取R=500个样

(四)模拟结果
表4给出了简单估计量和序贯调整估计量相对误差和均方误差的模拟结果。
从表4可以看出,简单估计量相对误差的绝对值和序贯调整估计量相对误差的绝对值都很小,在一定的误差范围内,可以认为序贯调整估计量和简单估计量一样,也是无偏估计量。从估计量的均方误差看,序贯调整估计量比简单估计量要小,这就有力地说明了序贯调整估计量是个有价值的估计量。

注:N=100000,f=0.01,α=0.99,m=100,R=500
(五)条件修改后的模拟结果
为了更加具体地考察序贯调整估计量的性质,我们还可以改变程序模拟时的一些条件,比较序贯调整估计量与简单估计量的相对误差和均方误差。
(1)子样本个数的变化
表5M变化时SRS和SAE估计量模拟结果
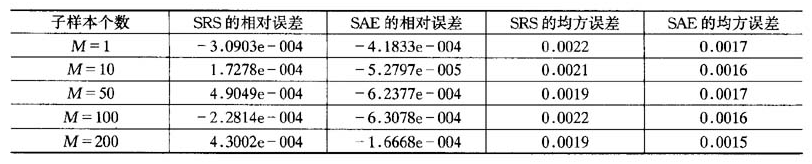
注:N=100000,f=0.01,α=0.99,R=500
从表5可以看出,随着子样本数M的减少,序贯调整估计量的相对误差并没有变大,该估计量依旧是无偏的,但是序贯调整估计量的均方误差稍稍有点增大。
(2)显著性水平的变化
表6中数据显示,不论α大小如何变化,序贯调整估计量的相对误差并没有变小的趋势,但均方误差却有变小的趋势,这就验证了显著性水平α应该尽可能的大。
表6α变化时SRS和SAE估计量模拟结果
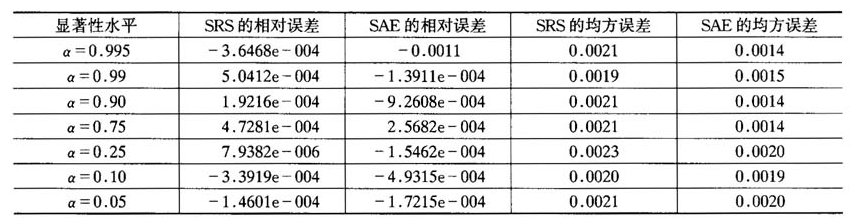
注:N=100000,f=0.01,M=100,R=500
三、序贯调整估计量和搜索比率估计量性质比较
钟卫、袁卫(2006)已经指出,如果广义搜索比率估计量的距离函数为G(x)=xlogx-x+1;x>0,则广义搜索比率估计量就是Deming和 Stephan提出的经典搜索比率估计量。因此,我们仅仅将搜索比率估计量与序贯调整估计量以及简单估计量作比较。
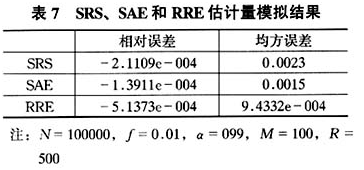
从表7可以看出,搜索比率估计量相对误差的绝对值和序贯调整估计量相对误差的绝对值、简单估计量相对误差的绝对值一样,都很小,所以,可以认为,在一定的误差范围内,搜索比率估计量和序贯调整估计量、简单估计量一样,都是无偏估计量。从估计量的均方误差看,搜索比率估计量比序贯调整估计量要小,序贯调整估计量比简单估计量要小,这就说明了序贯调整估计量的估计效果介于搜索比率估计量和简单估计量之间。
四、结论
本论文研究表明,尽管序贯调整估计量在精度上不是明显优于经典的方法,但是,这个有特色的新估计量构造起来容易、估计量形式也比经典的估计量简单,而且,它的提出对于如何更加有效地利用辅助信息提高估计量的精度、开拓不完全事后分层问题研究的新领域、以及解决样本的无回答问题等等都有着理论和实践上的积极意义。