关键词:抽样调查 列联表 对应分析 聚类分析
作者简介:陈上珠张奕徐敏浙江大学西溪校区,杭州310028
一、问题的提出
在调查问卷中经常会遇到处理样本点定性变量表类型的数据表。不仅要研究变量之间的关系,还需要研究样本之间的关系,并对潜在样本群特征进行分类。例如某媒体想了解读者对某报周末版版面的需求情况进行问卷调查,其中有一个内容如表1所示:
表1

希望通过分析能近似指出哪类读者群体更喜欢阅读哪几种版面,该群体具有那些特征,以便于今后对版面的调整作出科学的依据。这个问题是一种典型的属性数据处理的问题。所以我们采用属性数据的处理方法——多元对应分析来进行分析研究。
对应分析也称相应分析,它是主成分分析的拓广,依靠主成分分析中降维手段,从而能更直观明了地观察地分析定性变量多种状态间的相互关系。
二、数学原理
设有m个定性变量x[,1],…,x[,m]每个定性变量有p[,j]个状态,则共有
 个状态数。若有n个样本观测点,记变量x[,j]在第l状态上的观测频率是n[,jl],并给出记号x[,ijl]=1,表示样本点i在变量x[,j]的第l个状态上取值;否则x[,ijl]=0。于是x[,jl]为变量x[,j]在状态l的示性变量。
个状态数。若有n个样本观测点,记变量x[,j]在第l状态上的观测频率是n[,jl],并给出记号x[,ijl]=1,表示样本点i在变量x[,j]的第l个状态上取值;否则x[,ijl]=0。于是x[,jl]为变量x[,j]在状态l的示性变量。 是对应于变量x[,j]的择一式数据表(如后面表2的形式)。所以,数据表X=[x[,1],…,x[,m]]的形式如下:
是对应于变量x[,j]的择一式数据表(如后面表2的形式)。所以,数据表X=[x[,1],…,x[,m]]的形式如下:如何对数据表X实施分析?应用多元对应分析,其计算方法和过程完全与简单对应分析相同。所谓简单对应分析是指通常意义下对两个定性变量的多种状态进行对应性研究,对多个定性变量的研究,称多元对应分析。为便于原理的叙述,(A)首先对两个定性变量之间的数据表进行分析。由于x[,ijl]行间并无特殊约束,为叙述简单省去一个下标,设数据表:X=(X[,ij])[,n×m]i=1,…,n(不妨为样本数),j=1,…,m(为变量的状态数)。用x[,i.]、x[,.j]和x..分别表示X的行和、列和总和,即

在列联表中,行和列的性质是完全对称的,因此可以通过对列的分析来判断两个变量的关系。
在数理统计中,用x[2-]检验来验证两变量独立的显著性,假设H[,0]:两变量相互独立,备择假设H[,1]:两变量是相关的。
当n→∞时,在H[,0]成立条件下
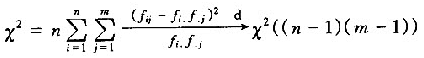 分布。
分布。若现在独立性假设H[,0]被否定后,研究变量各状态间的关系可从两方面进行主成分分析:

由此而产生的矩阵Z=(Z[,ij])[,n×m]分别对A=Z′Z与B=ZZ′进行主成分分析,就实现了对应分析。因为有关行分析与列分析的结果是互为对偶的,特别是它们同秩的主轴一定对应相同的特征值λ[,i],因此对应分析的计算结果可以在同一主平面图中打出样本点和变量的各个状态,从中可以分析样本点与变量各状态之间的关系。
(B)对多个定性变量的数据表X的研究,其计算方法和过程完全与简单对应分析相同。只是由于其数据的特殊性,它的边际和为一些特殊的值,它的行边际和
 现对多元对应分析的数据阵作如下
现对多元对应分析的数据阵作如下定义:对应于样本点i的行剖面点
f[i,j]=(…,f[,ijl]/f[,i],…)′=(…,x[,ijl]/m,…)′ |
对应于变量x[,j]中状态l的列剖面点
f[,jI]=(…,f[,ijl]/f.[,jl],…)′=(…,x[,ijl]/n[,jl,…)′ |
边际和
f[,I]=(…,f[,i],…)′=(…,1/n,…)′f[,J]=[…,n[,il]/nm,…)′ |
只要注意到符号的对应,原理同(A),所以多元对应分析的计算结果亦与对应分析有相同的特性,即有关行分析与列分析的结果是互为对偶的,它们同秩的主轴对应相同的特征值λ[,i],因此对应分析的计算结果在主平面图上亦是可以做叠置观察和分析。
有一点与主成分分析截然不同的性质,可以证明在对应分析中永远没有水平因子的存在,因此在运算前无需进行标准化处理。
三、多元对应分析在调查问卷中的应用
某媒体为进一步满足读者的需求,使双休日版面更受广大读者的欢迎,进行了读者问卷调查,本案例就是根据这次调查,应用了多元对应分析方法和聚类分析等多种方法对读者进行了比较详细的分析研究。设计变量如下:
1.生活空间7.个人电脑 13.星光灿烂19.阅读25.年龄
2.购物路标8.便民活动 14.综合体育20.视域26.性别
3.消费指标9.家居 15.全攻全守21.浓情小说27.职业
4.美食坊10.健康关怀16.足球阵线22.演艺 28.文化程度
5.休闲地带11.维权行动17.都市茶坊23.新现时·虚拟
6.好男好女12.服饰18.都市笔记24.新现实·民间
25~28只是对照变量并没有参加计算。原始数据见表2。(由于量大,只能象征性列出一个框架)
表2

对几十万个原始数据,应用SAS统计软件,编制了所有程序,完成了这大量繁琐的转换及计算工作,对应分析用CORRESP过程实现。结果如下,有关的特征值计算结果见表3。

有关行(样本点)和列(各变量的各状态)的主成分分析结果见表4和表5。
根据主成分得分再利用聚类分析方法将读者群划分为五大读者群。再根据这五类在各个因子上综合的均值,及相应的各个参考因子的分布,可以得出每个读者群的特征及它们之间的差异,分类描述见表6。这案例由于观测太大,变量又多,难以利用图形来做叠置观察和分析。
各类读者群的总述:
第一读者群(占总人数群13.9%),男性明显多于女性,且(18~40岁)的读者为多。感兴趣的版面多,且阅读认真、仔细。
第二读者群(占总人群32.9%),没有明显的性别偏好,且中年以上的读者较多,文化程度较高。他们以选择阅读为主要阅读方式。
第三读者群(占总人群42.2%),读者人数众多,且男性读者多。30岁以下人数占此群的45%以上,文化程度较高,学生为多。(这与调查正值暑期间有关)
第四读者群(占总人群4.3%)人数最少,女性偏多,年龄较大,文化程度较低,每版必看,但阅读程度不高。
第五读者群(占总人群6.8%),女性读者多于男性,职业层次低,版面偏好明显,不阅读的版面很多。
表6读者群特征描述


参考文献:
1任若恩,王惠文.多元统计数据分析——理论、方法、实例[M].北京:国防工业出版社,1997.
2方开泰.实用多元统计分析[M].上海:华东师范大学出版社,1989.
3高惠璇.SAS系统SAS/STAS软件使用手册[M].北京:中国统计出版社,1998.