关键词:福利彩票销售额回归分析强影响点变量选择主成分分析预测
作者简介:贾晨,谢衷洁,北京大学数学科学学院(北京100871)
引言
近些年来,中国的彩票事业正兴隆地发展着,而福利彩票作为在中国最早发起的一种彩票形式,已经有若干年的历史,并积累了丰富的数据,其中最重要的一项数据便是销售总额。试想,如果可以利用政府每年发布的各省份社会和宏观经济变量的数据对未来各省份的福利彩票销售总额进行预测,无疑对中国的公益事业(尤其是福利事业)是极为有利的。进一步,如果又知道这些社会和宏观经济变量对彩票销售额的作用是大是小,彩票的销售就可以更加有的放矢地进行。
Luke Zhang于2007年首次研究了中国各省份福利彩票销售额与各省份总人口数以及城镇人口百分比之间的关系,并给出了相应的预测方程(参考Luke Zhang. The Role of Population and Percentage of Urban Population in Increasing Welfare Lottery Sales. Technical Report, 2007)。但我们知道,彩票销售额这个复杂经济变量的变异显然不能由这两个变量所完全解释。本文的首要目的是尽可能多地找到彩票销售额的影响因素,尤其是那些看似与彩票销售额有关系,但具体关系搞不清楚的变量。通过对数据的合理分析,这些变量的作用便一目了然了。其次,尽管我们已经找到了彩票销售额的影响因素,但这些影响因素仍无法概括销售额全部的变异,这是由各省份民众的彩票购买力不同所造成的。这些因素被概括在回归分析的残差中。在本文中,我们通过对不同年份的残差进行主成分分析的方式,提取出了残差中的公共信息,以进一步解释彩票销售额的变异。最后,我们将通过上述分析所建立的预测方程对2007年的彩票销售额进行预测,并与真实数据进行对比,以验证模型的有效性。
在下文中,第一部分将利用2005年的彩票销售额数据与2004年各省份社会和宏观经济等变量的数据建立多元线性回归模型,并对变量的数据进行预处理;第二部分对完全变量集中进行变量选择,找出对彩票销售额有显著性影响的变量;第三部分将利用2005年、2006年彩票销售额的残差,对其结构进行深入的探讨并提取其公共信息;第四部分将确定最终的预测方程,并利用此方程对2007年的彩票销售额进行预测。
一、回归模型的建立及数据的预处理
(一)回归模型的建立
本文的目的是找出各省份福利彩票销售额与社会、宏观经济等变量之间的相关关系并试图对未来的彩票销售总额进行预测。很自然地考虑用多元线性回归模型对数据进行拟合。其中响应变量(或称因变量)是各省份的福利彩票销售总额;预测变量(或称自变量)则是各省份的社会、宏观经济等变量。但本文的问题与经典的回归问题有所不同。我们知道,如果想对未来的响应变量进行预测,必须要求未来的响应变量与建立模型时所用到的响应变量相互独立,但对于本问题,我们要用过去年份的彩票销售额建立模型并对未来的彩票销售额进行预测,它们显然不是独立的。面对这个问题,仅用回归分析是无法解决的。但回归分析对于找出那些对彩票销售额有显著性影响的预测变量已经是足够的了。
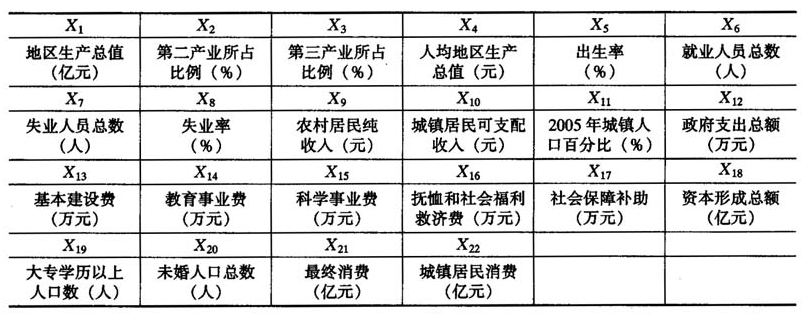
表1全体预测变量集
我们使用2005年各省份的彩票销售额作为响应变量来建立回归模型。注意到,我们的目的之一是对未来的彩票销售额进行预测,因此我们使用2004年各省份预测变量的数据来建立模型。这样,如果我们已知某一年各省份的相同预测变量的数据。就可以对未来一年、甚至几年的彩票销售额进行预测了。
基于这个想法,我们选取2004年的国民经济、就业人员和职工工资、财政、固定资产投资、人民生活这五个大项中的22个变量作为全体预测变量建立多元线性回归模型。它们或多或少都与彩票销售额有些关系,尽管有些关系在直观上是微弱的。它们的名称和单位如表1,一些重要变量(即在下文中被选中的变量)的具体的数值见附录A(略)。如果读者想对全部的变量有所了解,可以参考中国国家统计局官方网站:http://www.stats.gov.cn/,本文中所用到的除彩票销售额以外的所有数据都来源于此。
预测变量中的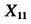 应给予特别重视,只有这个变量的数据来自于2005年。这是因为2004年这个变量的数据没有办法得到,又考虑到城镇人口百分比在相邻两年间的数值是不会有太大变化的,故用2005年的数据代替。用这p=22个预测变量
应给予特别重视,只有这个变量的数据来自于2005年。这是因为2004年这个变量的数据没有办法得到,又考虑到城镇人口百分比在相邻两年间的数值是不会有太大变化的,故用2005年的数据代替。用这p=22个预测变量 与响应变量y(即彩票销售额)建立多元线性回归模型如下:
与响应变量y(即彩票销售额)建立多元线性回归模型如下:
各省份的统计数据即为上述模型中变量的观测值。第i个省份的观测可以表示为

(二)变量的变换
通过对数据的观察可以发现,各省份的彩票销售额的数据差异甚大。山东省的数据最大,达到了531.37(单位为千万元,下同);而西藏自治区的数据最小,仅为4.33,两者相差了100多倍,对于其它预测变量也存在类似的现象。对这样的数据进行回归分析很容易出现异方差问题,也就是说误差的方差可能会随着某些预测变量的增大而呈现非常数的变化[1],这一点可以从彩票销售额Y对预测变量X[,1](简记为GDP)的散点图(图1)中明显看出。
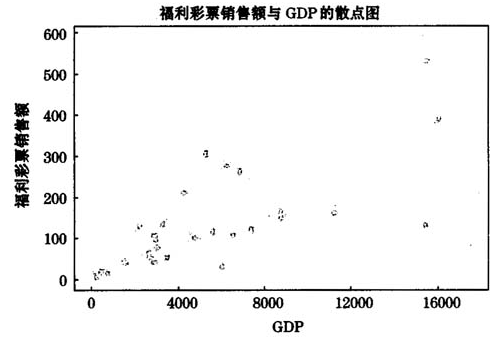
图1彩票销售额关于GDP的散点图
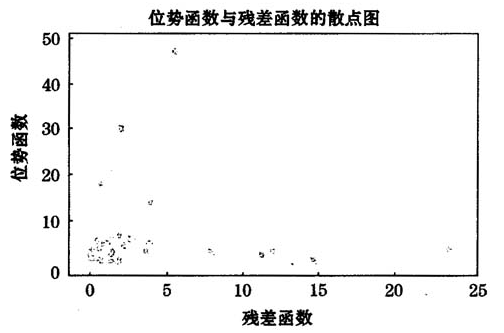
图2模型B的P-R图
上述讨论暗示着需要对变量作变换。当变量的取值范围很大的且此变量所有的观测值都严格为正的时候,对数据作对数变换是合适的。Weisberg[3]建议将所有最大数据与最小数据之比大于10的变量(包括预测变量和响应变量)作对数变换。目的是为了稳定方差以及使得残差更接近于一个来自相同正态总体的样本。

在以下的讨论中,我们将使用变换后的变量建立线性回归模型。
表2各变量回归系数的估计值和t-检验值
(三)预测变量的中心标准化
我们如果想要分析清楚每个变量的作用是大是小,就应该能够对它们的回归系数的大小进行统一比较。但由于各预测变量的量纲是不同的,它们的回归系数不能直接作比较,这对于分析是不利的。此外我们设想,如果用某年的宏观经济数据去预测未来几年的彩票销售额,由于中国的经济发展迅速,因此经济数据的增幅会很大,而彩票销售额的增幅可能不会那么大。因此,如果不对模型进行修正,则预测值肯定会比真实值明显偏大。面对这种情况,对预测变量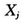 的数据作中心标准化是合适的,即作线性变换
的数据作中心标准化是合适的,即作线性变换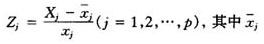 为第j个变量的样本均值而
为第j个变量的样本均值而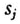 为其样本标准差。变换后,变量
为其样本标准差。变换后,变量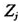 的样本均值为0,样本标准差为1。在下文中,我们总是使用经过中心标准化后的预测变量来建立模型。
的样本均值为0,样本标准差为1。在下文中,我们总是使用经过中心标准化后的预测变量来建立模型。
(四)参数的估计
有了上述对变量数据的预处理,我们可以对模型进行参数估计和其他一些统计推断[1]。得到的结果如表2所示。其中,“系数”这一列表示对模型中回归系数的最小二乘估计;“系数标准误”这一列表示各回归系数的标准误差,标准误差越小代表估计越精确;“T”这一列表示各回归系数的t-检验值,它是用以检验零假设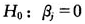 的统计量,用于衡量第j个预测变量对响应变量的作用是否显著;“P”这一列表示上述t-检验值所对应的p值,p值越小代表越有证据否定零假设,即认为
的统计量,用于衡量第j个预测变量对响应变量的作用是否显著;“P”这一列表示上述t-检验值所对应的p值,p值越小代表越有证据否定零假设,即认为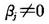 ,也就意味着第j个预测变量对响应变量的影响显著。
,也就意味着第j个预测变量对响应变量的影响显著。
复相关系数的平方[1-4](以下简称为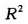 )在回归分析中有着特殊的重要性,它是回归模型好坏的重要衡量指标。可以计算,上述模型的
)在回归分析中有着特殊的重要性,它是回归模型好坏的重要衡量指标。可以计算,上述模型的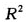 达到了0.967,这说明彩票销售额的全部变量中有96.7%的部分可以被预测变量所解释。无疑,上述22个预测变量的选取是成功的。
达到了0.967,这说明彩票销售额的全部变量中有96.7%的部分可以被预测变量所解释。无疑,上述22个预测变量的选取是成功的。
(五)强影响点的识别
在本小节中,我们将识别观测中的强影响点[1]。所谓的强影响点,是指会过度影响回归结果(包括回归系数估计、拟合值、t-检验值等)的观测点。强影响点与其它观测点一般不适宜用统一的回归方程去描述,如果把它们混在一起建立回归方程并用其进行预测的话,将会大大降低预测的精度,因此我们必须剔除观测中的强影响点。

一种实际的操作规则是将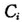 的值大于1的点归为强影响点[1]。
的值大于1的点归为强影响点[1]。
考查上述模型回归结果的Cook距离可以发现,第13号观测(福建省)的Cook距离为1.204,第26号观测(西藏自治区)的Cook距离为3.926,而其它观测的Cook距离都小于1,因此可以认为这两个观测是具有强影响的。仔细研究数据可以发现,福建省的国民经济、财政支出以及居民消费都处于一个比较高的水平,但彩票销售额却很低,属于响应变量取值异常的情形。而西藏自治区的预测变量的各个数据都比其它地区的小很多,属于预测变量取值异常的情形。
Hadi[1]还建议考察所谓的位势-残差图(P-R图)。第i个观测的位势函数定义为

其中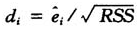 (RSS表示残差平方和)为正规化残差。位势函数衡量第i个观测的预测变量的异常程度。而残差函数衡量第i个观测的响应变量的异常程度。P-R图就是位势函数关于残差函数的散点图。
(RSS表示残差平方和)为正规化残差。位势函数衡量第i个观测的预测变量的异常程度。而残差函数衡量第i个观测的响应变量的异常程度。P-R图就是位势函数关于残差函数的散点图。
对于散点图中左上角的点,其位势函数很大,对应于预测变量取值异常的情形;而对于右下角的点,其残差函数很大,对应于响应变量取值异常的情形。对于上述模型,我们计算各观测的位势函数和残差函数的值,并画出相应的P-R图(见图2),可以看出,有两个点分别明显位于图中的左上角与右下角,它们分别是第13和第26号观测。也就是说第13号观测属于预测变量取值异常的情形而第26号观测属于响应变量取值异常的情形。这与用Cook距离得到的结论是吻合的。
剔除第13和第26号观测表示不能用我们建立的回归方程去预测这两个省份的彩票销售额,但删除这两个观测后的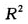 上升到99.6%表明得到的回归方程却可以对其它地区的销售额进行更加准确的预测。
上升到99.6%表明得到的回归方程却可以对其它地区的销售额进行更加准确的预测。
二、变量的选择
(一)根据VIF选择变量
在预测问题中,我们通常是采取吝啬原则(Parsimonic Princgle)的,指用尽可能少的变量对响应变量进行预测,使得模型更加稳健。此外,剔除那些对响应变量没有显著性影响的变量可以使得模型的结构更加清晰。
观察表2中回归系数估计值和系数标准误这两列,可以惊讶地发现系数标准误和回归系数达到了一个数量级,这表明回归系数的估计是非常不准确的。这个弊端通常是由预测变量间的多重共线性[1]造成的。多重共线性是指模型的预测变量间存在着多组潜在的近似线性关系。比如变量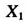 (地区生产总值)和变量
(地区生产总值)和变量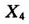 (人均地区生产总值)之间理应存在很强的线性关系。多重共线性会使得我们无法估计回归方程中单个变量独自的效应,而且会使很重要的变量的t-检验值偏低,这些对问题的讨论都是极为不利的。为此,我们采取如下的准则:首先用全部预测变量拟合模型,寻找方差膨胀因子[6](简记为VIF)大于R的一个变量(一般选取VIF最大的那个变量),将这个变量删除后再重新拟合模型。重复上述步骤,直到所有的预测变量的VIF值都小于k为止。
(人均地区生产总值)之间理应存在很强的线性关系。多重共线性会使得我们无法估计回归方程中单个变量独自的效应,而且会使很重要的变量的t-检验值偏低,这些对问题的讨论都是极为不利的。为此,我们采取如下的准则:首先用全部预测变量拟合模型,寻找方差膨胀因子[6](简记为VIF)大于R的一个变量(一般选取VIF最大的那个变量),将这个变量删除后再重新拟合模型。重复上述步骤,直到所有的预测变量的VIF值都小于k为止。
第i个预测变量的方差膨胀因子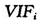 定义为
定义为
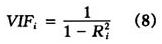

(二)向后删除法选择变量
在确定了没有明显多重共线性的变量子集后,我们就可以用普通的方法进行变量选择了。我们的目的是删除解释能力较弱的变量而保留解释能力较强的变量。为此,我们使用向后删除法(BE法)选择变量。我们选择选择向后删除法而不用向前选择法(FS法)或者逐步法的原因在于,向后删除法能更有效地抵御多重共线性带来的危害[1,7]。应用BE法删除变量需要考察各变量的t-检验值,每次删除t-检验值最小的一个变量,直到所有变量的t-检验值的最小绝对值大于1时停止(具体步骤请参看[1])。
表3利用BE法依次删除的变量和对应的t-检验值
|
|

将向后删除法应用于我们的模型,依次对变量进行删除,共删除了5个预测变量。删除的过程如表3所示,被删除变量的t-检验值都小于1。
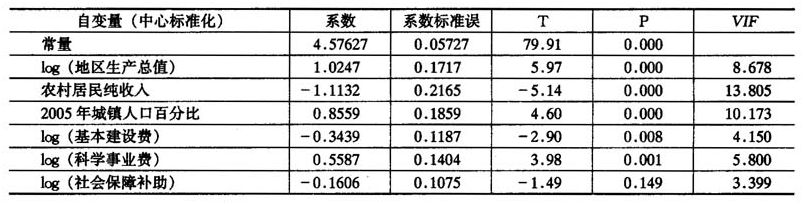
向后删除的过程终止后,剩余的预测变量只有6个。对这些变量作回归,所得到的结果列于表4中。最后得到一个既没有明显的多重共线性,且每个预测变量都有较强的解释能力的回归方程,其

表4用BE法删除变量后的回归结果
(三)模型的解释
通过对变量的合理删除,我们得到了t-检验值高度显著的6个变量,它们可以被认为是与彩票销售额最密切相关的6个变量,我们希望对其作用予以解释。它们分别是:
(1)国内生产总值。它反映了各省的经济水平,与彩票销售额正相关;
(2)城镇人口百分比。它反映了各省的城镇人口所占的比例,与彩票销售额正相关;
(3)基本建设费与科学事业费,它们在一定程度上反映了各省的财政支出。彩票销售额与它们是密切相关的;
(4)农村纯收入,它反映了各省居民的收入水平,它与彩票销售额负相关;
(5)社会保障补助费用,它反映了一个省的社会保障体系是否健全,它与彩票销售额负相关。
对于国内生产总值和城镇人口百分比,它们都与彩票销售额呈正相关。也就是说一个经济发展水平越高的地区,或是一个城镇人口比例越高的地区,其彩票销售额也越高。而对于农村纯收入和社会保障补助费用,它们都与彩票销售额呈负相关。也就是说一个收入水平较低的地区或是一个社会保障体系不健全的地区,其彩票销售额反而有增加的趋势。这或许是由于整体收入水平较低、社会保障体系不健全,造成居民的投机心理增强,总想以购买彩票的方式迅速达到致富的目的。
三、残差信息的提取
(一)残差的相关性
在第二部分中,我们已经找到了对彩票销售额有显著性影响的变量,但正如上文所说,如果想对未来的响应变量进行预测,必须要求未来的响应变量与建立模型所用到的响应变量相互独立,但对于本问题,我们要用过去年份的彩票销售额建立模型并对未来的彩票销售额进行预测,它们显然是不独立的。
在本部分中,我们将利用2005、2006年的彩票销售额数据与2004、2005年的六个预测变量的数据分析残差的内在结构。在第四部分中,我们将利用2006年预测变量的数据对2007年的彩票销售额进行预测。
用回归方程(9)拟合2005年与2006年的彩票销售额所得到的残差可以表示为
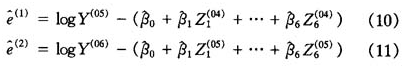
其中,预测变量和响应变量的上角标表示此变量的年份,例如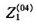 列表示2005年的彩票销售额,而
列表示2005年的彩票销售额,而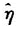 表示2004年标准化的log(地区生产总值)。可以计算,上述相邻两个年份残差的相关系数为0.768,这表明不同年份的残差之间有着很强的相关性。上述相关性意味着我们需要对不同年份残差中包含的公共信息进行提取。
表示2004年标准化的log(地区生产总值)。可以计算,上述相邻两个年份残差的相关系数为0.768,这表明不同年份的残差之间有着很强的相关性。上述相关性意味着我们需要对不同年份残差中包含的公共信息进行提取。
在下文中,我们将应用主成分分析的方法将上述的想法描述成数学模型,并提取出不同年份残差中包含的公共信息。
(二)残差信息的提取
由前面的讨论,6个预测变量解释了响应变量大约91%的变差,我们认为残差中包含了它们所不能解释的另一部分“信息”,用随机变量η表示。上述的回归方程(9)的右端加上η的估计值
我们要用拟合2005年与2006年的彩票销售额所得到的残差 来得出η的样本估计值
来得出η的样本估计值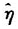 为简化处理,不妨设上述关系是线性的,即认为
为简化处理,不妨设上述关系是线性的,即认为


四、对2007年彩票销售额的预测
(一)2007年销售额的预测
事实上,本文第一和第二部分中的回归模型是根据2004年各省份的预测变量数据与2005年的彩票销售额数据建立的;第三部分中对于残差的讨论又用到了2005年各省份的预测变量数据与2006年的彩票销售额数据。现在,我们利用2006年的预测变量数据对2007年的彩票销售额进行预测。
根据上文讨论,最终的预测方程可以表示为

我们对2006年相应的预测变量的数据先作变换,然后作中心标准化,最后结合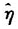 的数值带入预测方程(14),便可以得到2007年彩票销售额的预测值。表6中列出了若干重要的数值,包括残差公共信息11的估计值。彩票销售额的拟合值、实际值,以及相对预报误差。
的数值带入预测方程(14),便可以得到2007年彩票销售额的预测值。表6中列出了若干重要的数值,包括残差公共信息11的估计值。彩票销售额的拟合值、实际值,以及相对预报误差。
为了讨论预报的优良性,我们引入平均相对预报误差(记为APE)的概念,它衡量了拟合值与真实值的相对偏差的平均值,定义为
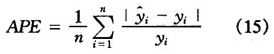
对于本问题,平均相对预报误差为18.92%(见表6)。它说明预报的偏差不到真实值的五分之一,这是相当令人满意的。
Luke Zhang(2007)对中国福利彩票销售额的影响因素作了开创性研究,选择了各省份的年底人口总数(pop)、城镇人口百分比(per),地区生产总值(GDP)、农村居民纯收入(RNI)、城镇居民可支配收入(UDI)这五个变量作为预测变量来拟合彩票销售总额(sales)。但上述文章中没有对变量的数据进行很好的预处理,没有剔除强影响点,也没有对残差的结构进行分析。此外,上述文章利用2005年各省份预测变量的数据拟合2005年的彩票销售额而得到回归方程,因此必须在得到2006年各省份预测变量的数据后才能进行预报,而不能提前进行预报。尽管如此,我们仍使用Luke Zhang文章中的模型所得到的回归方程,结合2006年各省份预测变量的数据对当年的彩票销售额进行预报(这里,我们利用政府更新后的数据对原文章中的数据进行了修正)。结果显示,回归方程的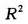 值仅为0.685,预测变量pop, per, GDP, RNI显著,回归可以表示为
值仅为0.685,预测变量pop, per, GDP, RNI显著,回归可以表示为
|
sales=-97.0+0.0124pop+6.79per+0.0150GDP-0.0652RNI |
用此回归方程对2006年的彩票销售额进行预测,结果显示福建和西藏的相对误差分别为94.29%与832.78%,明显高于其余省份,这正是被本文中剔除的两个强影响点。上述模型的平均相对预报误差(APE)为65.25%,显然无法与本文中18.92%的平均相对预报误差相比。
表6模型D对2007年彩票销售额的预测
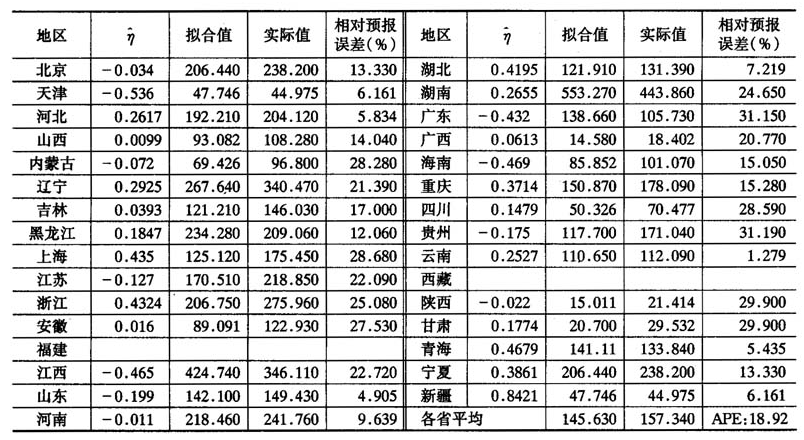
注:福建省和西藏自治区的彩票销售额不适合用上述的预测方程描述。
五、总结与讨论
本文利用2004年的国民经济、就业人员和职工工资、财政、固定资产投资、人民生活这五个大项中22个变量作为全体变量集对2005年的福利彩票销售额建立多元线性回归模型,最终挑选出对彩票销售额有显著性影响的6个变量,它们分别是地区生产总值、农村居民纯收入、城镇人口百分比、基本建设费、科学事业费和社会保障补助。此外,本文对残差的结构进行了深入的探讨,利用主成分分析的方法合理提取出来不同年份残差中的公共信息,最终成功用于对2007年彩票销售额的预测。可以看到,本文中使用的方法对销售额的预测获得了较小的平均相对预报误差。
在此,我们想说明本文第四部分的讨论是不可缺少的,即提取残差公共信息是必要的。我们可以仅用第二和第三部分中线性回归理论所得到的回归方程(即(9)式)对2007年的销售额进行预报,仿照上文的做法,计算出各省份的相对预报误差,所得到的平均相对预报误差(APE)为34.82%。它说明预测的偏差大约为真实值的三分之一,这个结果显然与加入残差的公共信息的预测方程(14)的预报效果有很大的差距。也就是说,对残差结构的深入分析以及对公共信息的合理提取使得预测结果大大改善,平均相对预报误差则减小了45.66%。
本文中得到的预测方程是通过2005年彩票销售额数据建立的,并应用于对2007年彩票销售额的预测。它虽然可以预测未来的若干年内的彩票销售额,但预测的年份越远,相应的误差也就会越大。为了预测的精确性,需要我们根据手上已知的经济、财政等方面的数据按照本文中所述的方法去更新(14)中的预测方程,这样才能真正做到与时俱进。
六、附录:原始数据(略)
参考文献:
[1]Catterjee S, Hadi A S. Regression Analysis by Example (4th Edition)[M].New York:John Wiley & Sons,2006.
[2]Draper N R, Smith H. Applied Regression Analysis (2ed Edition) [M]. New York: John Wiley & Sons, 1981.
[3]Weisberg S. Applied Linear Regression(3rd Edition) [ M]. Hoboken N J: John Wiley & Sons, 2005.
[4]陈家鼎,孙山泽,李东风,刘力平.数理统计学讲义[M].北京:高等教育出版社,2006.
[5]陈希孺,王松桂.近代回归分析:原理、方法及应用[M].合肥:安徽教育出版社,1987.
[6]Marquardt D W. Generalized inverses, ridge regression and biased linear estimation[J]. Technometrics, 1970,12:591-612.
[7]Mantel N. Why Stepdown Procedures in Variable Selection[J]. Technometrics, 1970,12:591-612.
[8]高惠璇.应用多元统计分析[M].北京:北京大学出版社,2005.
[9]Johnson R A, Wichern D W. Applied Multivariate Statistical Analysis(4th Edition)[M]. Englewood Cliffs N J:Prentice-Hall, 1998.