内容提要:文章从算法角度对关联规则的提出、演变过程和前沿研究进行了较为详细的考察,并在此基础上提出了关联规则未来研究的领域和发展趋势。文章先详细地考察了关联规则的三类典型算法,然后总结了基于复杂数据属性的关联规则算法扩展。为考察其他方面的算法扩展和介绍其他学科领域对关联规则的研究奠定了基础。
关键词:知识发现 数据挖掘 关联规则 频繁集
作者简介:来升强,朱建平,厦门大学经济学院计划统计系,福建厦门361005
引言
目前,数据挖掘的研究主要集中在关联规则挖掘、分类、聚类、路径发现、异常发现和趋势发现等方面。其中,关联规则挖掘侧重于确定数据中不同属性域之间的联系,找出满足特定要求的数据属性域之间的相互关系。而关联规则在医药、金融、商业和工业制造等行业中的成功应用,使关联规则成为了数据挖掘中最成熟、最重要、最活跃的研究内容之一。本文从关联规则的有关概念和定义着手,详细考察了关联规则的搜索算法、Aprori类算法和频繁模式增长算法,为跟踪在复杂数据属性和复杂数据组织形式方面的算法扩展和其他学科领域对关联规则的研究奠定基础。
一、关联规则的定义
(一)有关的概念
关联规则挖掘是指在数据库中挖掘出“某些特定组合的事件反复发生”的规则。这里,事件的发生被定义为特定属性值的出现或者不出现。关联规则中涉及到以下一些概念。
1.项、基本项集、项集、R-项集。项(Item)是相对于具体应用的概念,由不同的研究对象或用户要求决定。对于一项具体的关税规则挖掘任务来说,可以确定其要考察的所有的项,作为问题的论域,即可以确定一个基本项集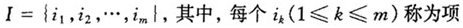 。而这个基本项集的子集称为项集,一般我们把包含k个项的集合称为k-项集(itemset),K为项集的大小(size)。
。而这个基本项集的子集称为项集,一般我们把包含k个项的集合称为k-项集(itemset),K为项集的大小(size)。
2.事务、事务数据库。事务T是由I中若干个项构成的集合,即 。事务数据库是所有事务的集合。事务数据库中每个记录代表一个事务,每个事务有一个惟一标识TID和一个组成该事务的项的列表,即有
。事务数据库是所有事务的集合。事务数据库中每个记录代表一个事务,每个事务有一个惟一标识TID和一个组成该事务的项的列表,即有
3.项集频数、频繁项集、频繁k-项集、包含某一项集的事务在整个事务数据库中的出现次数称为该项集的项集频数(occurrence),项集的频数等价于项集支持度。若项集满足最小支持度min_sup,则称它为频繁项集(或大项集)。频繁集是频繁项集的集合(注:为避免混淆,文中“频繁集”均指“频繁项集的集合(collection of frequent intemsets)”,“频繁项集”指“由项构成的集合”。)。若某频繁集中的所有子集都是大小为k的频繁项集,称为频繁k-项集。为便于叙述, 。
。
(二)关联规则的定义

关联规则可分两个部分:左边部分称为前件(the antecedent)。右边部分称为后件(the consequent)。关联规则的形式通常暗示一种从左到右的因果关系,但关联规则是属性之间内在的相互关联而不一定仅仅是因果关系。
二、关联规则挖掘的典型算法
由于关联规则挖掘是针对非量数据而言,首要考虑的是算法的效率(Efficiency)与可扩展性(Scalability)问题。所以,关联规则的研究中往往强调算法效率,而不是对规则的解释。
从算法实现看,关联规则挖掘可以分为两个阶段。第一阶段,扫描数据库生成频繁集;第二阶段,由频繁集生成关联规则。由于第二阶段相对容易。研究主要集中在频繁集的生成阶段。算法的设计主要考虑两个方面:第一,优化算法流程,减少内存占用和数据库扫描的次数。第二,寻找更具有压缩性的数据结构,建立更高效率的算法。
从算法发展看,早期有AIS[1]和SETM[2]等一次性搜索算法。接着Agrawal R等1994)提出了Apriori和Apriori Tid,Apriori Hylrid[3]算法,其他基于Apriori的改进有分区和采样两种优化策略。而另一类频繁模式增长算法[4,5]。通过建立压缩性的数据结构,摆脱了Apriori算法冗余的逐层扫描过程,无需候选集就能直接得到频繁集。
(一)搜索算法
搜索算法对每个事务计算所有候选集的支持度,因而只需要对数据库一次扫描即可得到所有的频繁集。有代表性的算法是AIS算法[1]和SETM算法[2]。在AIS算法中,候选集在读入事务时动态生成,如候选集中已有则增加支持度计数,否则加入新的候选项集,直至扫描完毕才能确定频繁集。SETM算法则通过标准SQL语言的排序和连接操作完成支持度计数和频繁集生成。
对于包含n项的事务,这类算法要产生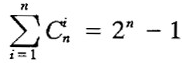 个项集以计算支持度,需要占用大量空间。因此这类算法仅适用于项数较少的关联规则挖掘。
个项集以计算支持度,需要占用大量空间。因此这类算法仅适用于项数较少的关联规则挖掘。
(二)Apriori类算法
Apriori及其改进算法都采用了逐层扫描的宽度优先策略,因此被称为Apriori类(Ariori-Like)算法。该类算法的核心思想基于两个单调性命题:(1)k-项集X是频繁项集的必要条件是它的所有(k-1)-项子集都是频繁项集。(2)如果k-项集X的任意一个(k-1)-项子集非频繁,则X也非频繁。

Agrawal等(1994)还给出了两个改进算法:AprioriTid和AprioriHybrid[3]。AprioriTid算法采用Apriori得到候选1-项集,但以 可以全部载入内存时,改用AprioriTid算法。
可以全部载入内存时,改用AprioriTid算法。
以上二种算法主要是对算法流程的改进,而从减少输入算法的数据量方面有以下两种优化策略。
第一,对数据库分区。Partition[7]先把原始数据库D划分为n个相等大小且不相交的部分,每个部分只需一次扫描就可得到所有的局部频繁集,再合并为全局候选集。然后再次扫描数据库就可得到全局频繁集和对应的支持度。而DIC算法[8]在同一次扫描中,对所有大小的候选集支持度计数并生成频繁集,可预先得到较长的候选集,以此减少对数据库的扫描次数。

(三)频繁模式增长算法
这类算法以Agrwal R等(2001)提出的Tree-projection算法[4]和Han J等(2000)提出的FP-Growth算法[5]为代表。它们都采用树形数据结构存储项集,只要对树进行递归搜索就可以发现所有的频繁模式。这种数据结构是紧凑和密实的,可大大减少算法搜索的空间。
Tree-projection算法建立一种字典序树(lexicogaphical tree),并根据已发现的频繁模式,将原始数据库映射到这种基于频繁项的简化的树形数据结构上。只要将树建造完成就可得到所有频繁集。Tree-projection的变换映射有效地减少了支持度的搜索空间,并且只需考虑相关的事务。此外,字典序树便于管理和计算支持度,且在树的生成阶段和事务映射阶段可以很方便地进行优化。
FP-Growth算法将数据库中的所有事务映射到FP-tree上,然后搜索FP-tree得到所有的频繁集。FP-tree中,事务的项集先按项排序,再映射为由结点序组成的路径,具有相同前项的事务被合并为具有同一个前缀路径的子树。同一个路径上的各结点的支持度计数是递减的,该路径的支持度就是未结点的支持度。该算法可以高效地进行超长频繁集挖掘和低支持度挖掘。
三、基于复杂数据属性的算法扩展
早期关联规则的研究都是针对布尔型属性展开,没有考虑数据属性的特点。而在实际中由于数据属性的多样性,关联规则也具有多种形式。按属性取值类型可分为布尔(boolean)关联规则和数值(numeric)关联规则,数值关联规则又分为定量(quantitative)关联规则和定类(categorical)关联规则(注:布尔关联规则可以作为定类关联规则的特例。)。按谓词(维度)可分为只有一个谓词的维内(intra-dimensional)关联规则,包含两个或两个以上的不同谓词的多维(multi-dimensional)关联规则。没有重复的多维关联规则称为维间(inter-dimensional)关联规则,否则称为混合关联规则。在同一个维度的多个属性间会存在概念上的隶属关系,这就形成了多层次(multi-level)关联规则(注:对于只挖掘泛化层次的关联规则,称为泛化(generalized)关联规则。)。由于属性分类的多样性和复杂性,各类关联规则之间也会有交叉和重复。
(一)数值关联规则算法
数值关联规则问题首先由Srikant R等(1996)提出并给出了形式化的定义[10]。处理数值属性的基本思想是先将定量或者定类属性映射为布尔型属性,然后采用一般算法完成关联规则挖掘。因而如何将数值属性区间化就成为这类研究的关键。
Srikant R考虑将数值属性等间隔划分,并使用偏完整度(measure of partial completeness)度量分区的信息损失和决定分区个数。当某一个分区的支持度小于min-sup,就与邻近的分区合并。同时给出了置信度的降低程度,部分解决了置信度过低问题。Fukuda T等(1996)提出等深度划分(equi-depth partitioning)方法[11],把具有共性的,支持度很高的相邻值划分到不同的区间。
但以上方法都不能很好地反映偏态数据分布。为能使分区充分反映数据的分布性态,张朝晖等(1998)提出一种基于聚类分区的MAQA算法[12]。先建立数值属性的事务数和属性值的二维表,按照属性值将每个局部极值区间作为基本分区,如果分区交易数大于平均交易数则保留;否则合并,再对分区检查交易数密度,保留大于平均密度的分区作为有价值的区分,在此基础上挖掘关联规则。苑森淼等(2000)的PKCCA算法[13]将数值关联规则的特点和偏完整度思想相结合,在聚类过程中动态调整中心数目,兼顾了数据的聚集和分区的支持度问题。
(二)多层次关联规则算法
在数据属性中存在隐藏的概念层次信息,这种概念层次结构可用有向无环图(Directed Acyclic Graph)表示,图中每个边表示归属关系,父结点是子结点的泛化(generalization),子结点看做是祖先的实例化(instantiation)。实际应用中感兴趣的规则往往出现在较高的概念层次上,因此有必要进行多层次关联规则挖掘。具体有以下几类方法:(1)对属性集建立概念层次树之后,按照泛化层次合并事务后挖掘指定层次的关联规则;(2)将概念层次树中所有结点都作为项集,使用固定的支持度阈值;(3)对不同概念层次结点采用可变支持度阈值分层挖掘。
Srikant R等(1995)首先考虑了多层关联规则问题并提出了Cumulate和Stratify算法以及Estimate和EstMerge两种改进算法[4]。Cumulate算法扫描事务时,先把事务中项的祖先也列入事务中,然后使用Apriori算法发现各个概念层次上的关联规则。Stratify类似Apriori算法,自上而下的逐层筛选频繁集。可见Cumulate需较多的项集操作,但I/O较少。而Stratify项集操作较少,但是I/O较多。Estimate和EstMerge算法则是用采样技术对Stratify算法进行优化。而ML-T2L1算法[15]首先按照概念层次对所有项进行层次编码,再使用类似Apriori算法按照概念层次树从上到下的搜索频繁集。
(三)多维关联规则算法
Lu H等(2000)提出的多维关联规则问题[16],在传统的单维关联规则上,更全面地考虑事务的环境因素(context),并引入相关的因素作为事务的维度,以更加详细和准确的描述事务特性。关于多维关联规则的性质和理论的详细讨论见文献[17]。
Feng L等(1999)借助用户模板指导和约束来避免产生过多的规则[18]。将用户指定的布尔型约束的模板转译为所有可能的实例。计算每次扫描时需要识别的候选集数目决定采用并行或者独立搜索策略得到频繁集。Tung AK等(1999)的FITI算法[19]。首先采用Apriori算法得到所有的维内频繁集,并按频繁集的大小把维内频繁集和支持度分别存入多个FIT表,然后类似Apriori,逐层生成维问候选集,再扫描FIT表得到支持度。
四、总结
本文首先引入关联规则的有关概念和定义,并对三类典型的关联规则算法进行详细地分析和比较。随后,从关联规则结构和算法设计角度分别考察了数值关联规则、多层次关联规则和多维关联规则等三类具有复杂属性的关联规则扩展算法。至此,关联规则做为数据挖掘的重要研究方向之一,已经具备了较为完整的理论体系。
但是,随着现代数据库技术的发展和应用领域的拓宽,数据存储形式甚至数据格式都发生了巨大变化,关联规则挖掘也面临了前所未有的挑战。这就要求研究者重新定义各种数据形式下的关联规则并建立相应的算法。
参考文献:
1Agrawal R,Imielinsi T,Swami A.Mining Association Rules between Sets of Items in Large Databass[R].the 1993 ACM SIGMOD Conference,Washington D.C.,USA,1993.
2Houtsma M,Swami A.Set-Oriented Mining for Association Rules in Relational Databases[R].the 11the Int'l Conf.on Data Engineering,1995.25-33.
3Agrawal R,Srikant R.Fast Algorithms for Mining Association Rules in Databases[R].the 20th Int'l Conf.on VLDB,Santiago,Chile,1994.487-499.
4Agrawal R,Aggarwal C,Prasad V.A Tree Projection Algorithm for Generation of Frequent Itemsets[J].Journal of Parallel and Distributed Computing,2001,61(3):350-371.
5Han J,Pei J,Yin Y.Mining Frequent Pat Terns without Candidate Generation[R].the 2000 ACM SIGMOD Conference,Dallas,Texas,USA,2000.
6Park J S,Chen M S,Yu P.An Effective Hash Based Algorithm for Mining Asociation Rules[R].ACM SIGMOD int'l conf.on Management of Data,San Jose,Canada,1995.175-186.
7Savasers A,Omiecinski E,Navathe S.An Efficient Algorithm for Mining Association Rules in Large Databases[R].the 21st VLDB Conference,Zurich,Switzerland,1995.
8Brin S,Motwani R,Jeffrey D U,et al.Dynamic Itemset Counting and Implication Rules for Market Basket Data[R].the 1997 ACMSIGMOD conference,Arizona,USA,1997.
9Tovionen H.Sampling Large Databases for Association Rules[R].the 22th VLDB Conference,Bombay,India,1996.
10Srikant R,Agrwal R.Mining Quantitative Association Rules in Large Relational Tables[R].the 1996 ACMSIGMOD Conference,Montreal,Canada,1996.
11Fukuda T,Morimoto Y.Mining Optimized Association Rules for Numeric Attributes[R].the 15th ACMSIGACT-SIGMOD-SIGART Symp.on Principles of Database Systems,Montreal,Canada,1996.182-191.
12张朝晖,陆玉昌,等.发掘多值属性的关联规则[J].软件学报,2000,(8).
13范森淼,程晓青.数量关联规则发现中的聚类方法研究[J].计算机学报,2000,(8).
14Srikant R,Agrawal R.Mining Generalized Association Rules[R].21st Int'l Conf.on VLDB,Zurich,Switzerland,1995.
15Han J,Fu Y.Discovery of Multiple-Level Association Rules from Large Databases[R].the 21st VLDB conference,Zurich,Swizerland,1995.
16Lu H,Feng L,Han J.Beyond Intratransaction Association Analysis:Mining Multidimensional Intertransaction Association Rules[J].ACM Transactions on Information Systems,2000,18(4):423-454.
17Feng L,Dillon T,Liu J.Inter-transactional Association Rules of Multi-dimensional Context for Prediction and Their Application to Studying Meteorological Data[J].Data and Knowledge Engineering,2001,37:85-115.
18Fang L,Yu J X,Lu H,et al.Mining Inter-Transaction Associations with Templates[R].ACMCIKM conference,Kansas City,Missouri,USA,1999.
19Tung A K H,Lu Han J,et al.Breaking the Barrier of Transactions:Mining Inter-Transaction Association Rules[R].ACMKDD conference,San Diego,USA,1999.