内容提要:“厚尾现象”是金融时间序列分布的一个普遍特征,本文将Realized GARCH模型推广到容纳厚尾分布的情形,并将杠杆函数的幂次放松为待估参数。结果显示,使用Skewed-t分布的模型能够较好地反映收益率序列的厚尾和偏峰性质,放松的幂次参数可以给出更贴合数据的“信息冲击曲线”。引入厚尾分布亦可用改进Realized GARCH模型对实现测度的预测,其中使用标准t分布的模型给出的预测精度最高。
关键词:Realized GARCH/厚尾分布/高频数据/信息冲击曲线
作者简介:王天一,黄卓,北京大学国家发展研究院中国经济研究中心。
引言
长期以来,波动率模型一直在金融时间序列研究中占据核心地位。学者们提出过各种各样的方法对波动率进行估计,其中最具代表性的当属Engle(1982)、Bollerslev(1986)提出的ARCH/GARCH类模型,这类模型在描述波动率聚类,尖峰厚尾现象上有相当出色的表现。GARCH模型的成功提出,激励了后继者们开发各种类型的GARCH模型(Bollerslev,2010)。特别地,为了衡量收益率对于波动率的非对称影响,Nelson(1991)、Glosten等(1993)分别提出EGARCH和GJR-GARCH模型来刻画这种杠杆现象。Engle和Victor(1993)提出用“信息冲击曲线”(News Impact Curve,NIC)来分析“杠杆效应”。除了“杠杆效应”,研究者还发现基于正态分布的GARCH模型并不能很好地刻画残差的厚尾性质,因此开始考虑使用厚尾分布,如Student's-t分布、GED分布等。
随着高频数据的可得性越来越强,基于高频数据非参数的各种“实现”测度①(Realized Measure)在波动率研究中越发占据重要地位。鉴于GARCH模型在日数据上的成功表现,如何将实现测度和传统的GARCH模型框架结合起来就成为波动率建模中的一个热点话题。一个直接的办法就是将实现测度简单地加入到方差方程式中作为一个外生变量,如GARCH-X模型。由于仅仅是将实现测度当做外生变量,这类模型并不是完整的模型,并不能解释实现测度的变动。为了改进这一点,人们开始寻找“完整”的模型。Engle和Gallo(2006)、Shephard和Sheppard(2010)分别提出了MEM模型和HEAVY模型,但这两个模型都依赖于至少两个以上的隐变量(Latent Variable)。相比之下Hansen等(2011)提出了Realized GARCH模型就要简单直接得多,这个模型只用一个隐变量就可以实现收益率,波动率和实现测度的联合建模。其想法是将GARCH-X模型的条件波动率h和实现测度X用一个测量方程连接,从而将模型封闭起来。并在其中植入一个杠杆函数来描述“信息冲击曲线”②。
Hansen等(2011)提出的Realized GARCH模型采用的残差分布是标准正态分布,这种分布并不能充分拟合收益率序列中可能的厚尾和偏峰的情况,本文使用美国股市数据进行拟合的结果也证实了这一点。因此本文将标准Realized GARCH模型推广到残差服从Skewed-t分布的情形之下,结果显示这种推广可以显著地增强模型对样本的拟合。另外,标准Realized GARCH模型将杠杆函数的幂次锁定在2,这等于先验地设定了信息冲击曲线的陡峭程度,或者说是设定了波动率对于收益率冲击的敏感程度。本文的第二个推广在于将幂次系数d作为一个数据决定的待估参数,与模型的其他参数一起进行估计。结果显示,在相当的情况下,这样的处理可以改进模型的拟合,运用“开盘价—收盘价”计算收益率的模型其信息冲击曲线参数d集中在1.5附近,而并不是标准模型中设定的2。
Wantanabe(2011)和本文平行发展了基于Skewedt分布Realized GARCH模型,但是和本文有显著的不同:第一,侧重点不同,Wantanabe(2011)侧重于将结果应用于VaR的估计,本文侧重于在更合理的残差假定下最优的估计“信息冲击曲线”的参数;第二,应用数据不同,本文除了讨论指数数据SPY以外,还讨论了个股数据;第三,收益率的计算更多样,除了讨论“收盘价一收盘价”收益率以外,还讨论“开盘价一收盘价”收益率。这两种收益率的比较体现了隔夜收益率或者说是隔夜信息对于残差分布以及信息冲击曲线的影响。
一、Realized GARCH模型简介
为了简单起见,本文使用Hansen等(2011)提出的最简单的Realized GARCH(1,1)模型为例:


从而有v(z)=γτ(z)∝π(z)。因此,本文在样本中不加区分地将τ(z)称为“信息冲击曲线”。
和传统的GARCH模型一样,Realized GARCH模型使用的也是正态的残差分布,这种分布有可能不能给出足够的偏峰和厚尾性质。因此我们有理由怀疑Realized GARCH模型和传统GARCH模型一样在拟合收益率分布的偏峰和厚尾性质能力不足。本文使用基于正态分布的Realized GARCH模型对指数(SPY)和个股(MSFT)2002年1月至2008年8月日数据进行拟合。其中,日收益率使用“收盘价一收盘价”和“开盘价一收盘价”两种不同的方式计算。实现波动率使用的实现“核”波动的计算方法如下:
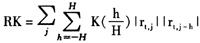
其中,K(·)是核函数,这里使用的是Bartlett核。H是核函数的带宽。实现“核”波动率和传统的实现波动率RV相比,由于显著地考虑了高频收益率之间的相关性,因此削弱了市场微观噪音对于实现测度计算的影响。
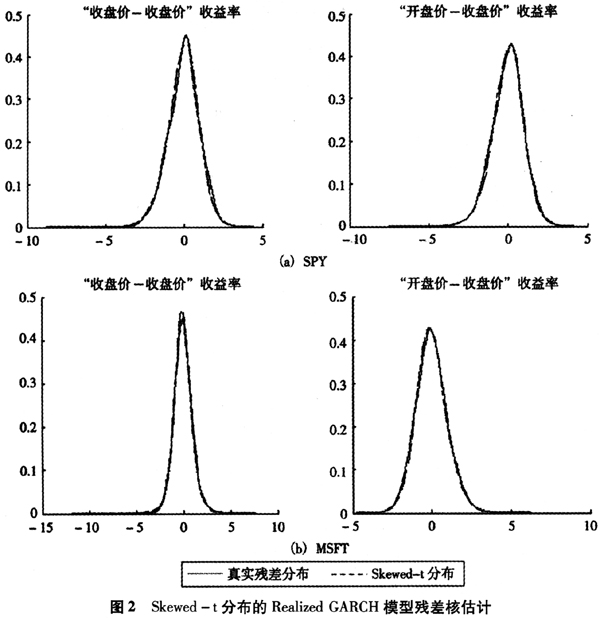
为了确定残差的尾部厚度和偏斜情况,本文对残差进行Skewed-t分布拟合,结果如下页图1所示。结果显示残差仍存在厚尾和偏斜现象,且个股数据表现更突出,更加偏离正态分布。基于“收盘价一收盘价”日收益率模型的残差比使用“开盘价一收盘价”日收益率模型的残差更加接近正态分布。由图1可知,正态分布对于残差的描述能力有限,因此有必要对模型进行拓展,使残差能够容纳厚尾和偏斜这两个特征。
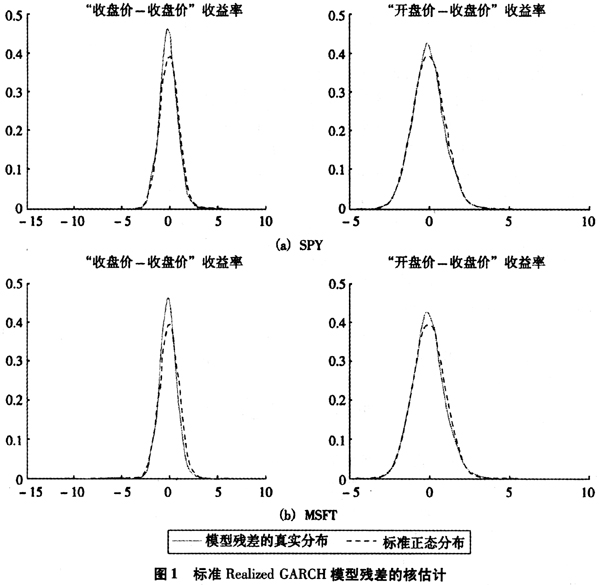
二、模型扩展
对基本的Realized GARCH模型进行两项扩展,第一项是改变误差
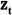 的分布。鉴于前面正态分布不能拟合的偏度和厚尾的性质,本文使用Hansen(1994)提出Skewed-t分布来改进③。使用Skewed-t分布的好处在于其相当灵活,t分布、Skewed-Normal分布、Normal分布都是其特殊情况。Skewed-t分布密度函数:
的分布。鉴于前面正态分布不能拟合的偏度和厚尾的性质,本文使用Hansen(1994)提出Skewed-t分布来改进③。使用Skewed-t分布的好处在于其相当灵活,t分布、Skewed-Normal分布、Normal分布都是其特殊情况。Skewed-t分布密度函数: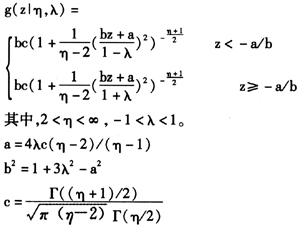
Hansen(1994)证明了上述分布的均值为0,方差为1。分布中的参数λ控制了Skewed-t的偏度,当λ时分布右偏,当λ时分布左偏。当λ=0时,Skewed-t分布退化为标准t分布。进一步,和t分布一样,自由度η控制了尾部的厚度,当η→∞时,Skewed-t分布趋向Skewed-Normal分布:
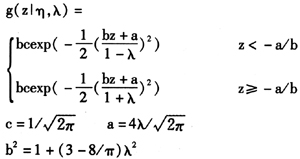
其中,-1<λ<1。进一步,当λ=0时,Skewed-Normal分布退化为标准正态分布,并有标准的尾部厚度(峰度为3)。
第二个扩展是把τ(
)函数的幂次作为优化变量来处理,具体为:
三、估计结果及检验
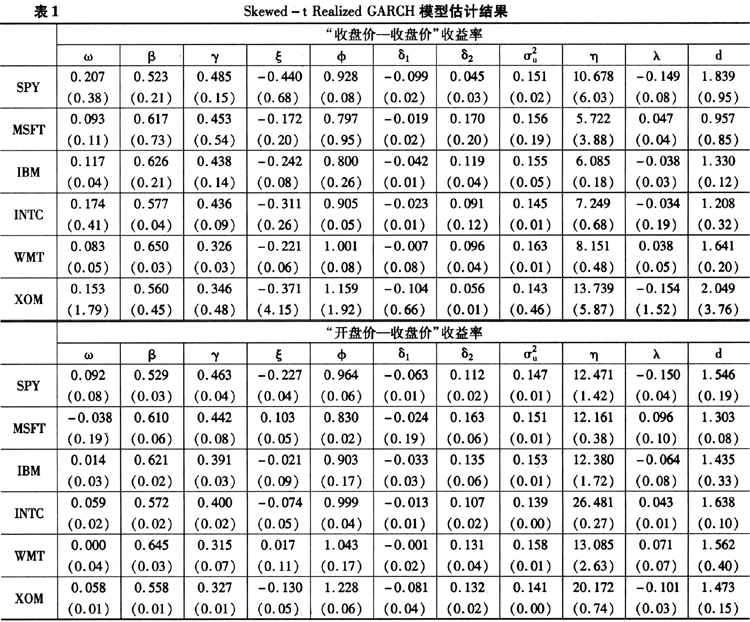
本文使用的数据包括股票指数(SPY)和个股数据(MSFT、IBM、INTC、WMT、XOM)的2002年1月至2008年6月的日数据。使用MLE方法估计基于Skewed-t分布的Realized GARCH模型,结果见表1。
表1中的第一部分是基于“收盘价一收盘价”计算收益率的估计结果,第二部分是基于“开盘价一收盘价”计算的收益率的估计结果,两者之间的差距可以认为是隔夜收益率的影响。和前面一样,实现波动率使用实现“核”波动率(RK)计算。从表1中可以看出,系数β和γ的大小在指数和个股之间都相对稳定。系数Ф取值接近于1,印证了式(3)被看做测量方程是有道理的,同时这个结论也和Andersen和Bollerslev(1998)给出的结论一致,即GARCH模型可以给出波动率的一个较好的估计。参数η显示,相对于“收盘价一收盘价”收益率而言,“开盘价一收盘价”收益率计算的模型残差尾部更薄一些。这是因为实现“核”波动率的计算只是用到了日内收益数据,并不包含隔夜收益的信息。因此,相对于同是日内收益率概念的“开盘价一收盘价”收益率而言,“收盘价一收盘价”收益率蕴含更多的不确定性,而这种附加的不确定性导致了“收盘价一收盘价”收益率模型的残差有更厚的尾部④。
以
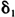 ,
,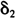 和d衡量的τ(z)函数形状在不同的股票之间显示出相同的特征,负向收益率会增大波动率,超过平均水平的收益率会增大波动率。参数d的取值在“收盘价一收盘价”收益率模型中波动较大,但是在“开盘价一收盘价”收益率模型中波动相对较小,大多在1.5左右。τ(z)对应于传统文献中的“信息冲击曲线”;其中参数d的大小决定了这条曲线陡峭程度,d越小曲线越平坦,条件波动率对于信息冲击的反应越迟钝;d越大曲线越陡峭,条件波动率对于信息冲击的反应越敏感。模型显示日内收益率“信息冲击曲线”的敏感程度相对稳定,但隔夜收益率“信息冲击曲线”的敏感程度则有相当的差别。这导致了使用“收盘价一收盘价”收益率模型计算的敏感程度参数d波动很大。
和d衡量的τ(z)函数形状在不同的股票之间显示出相同的特征,负向收益率会增大波动率,超过平均水平的收益率会增大波动率。参数d的取值在“收盘价一收盘价”收益率模型中波动较大,但是在“开盘价一收盘价”收益率模型中波动相对较小,大多在1.5左右。τ(z)对应于传统文献中的“信息冲击曲线”;其中参数d的大小决定了这条曲线陡峭程度,d越小曲线越平坦,条件波动率对于信息冲击的反应越迟钝;d越大曲线越陡峭,条件波动率对于信息冲击的反应越敏感。模型显示日内收益率“信息冲击曲线”的敏感程度相对稳定,但隔夜收益率“信息冲击曲线”的敏感程度则有相当的差别。这导致了使用“收盘价一收盘价”收益率模型计算的敏感程度参数d波动很大。在Skewed-t分布中控制尾部厚度的参数是自由度η,η趋向无穷时,Skewed-t分布趋向Skewed-Normal分布。在定义给出的偏度参数范围之内,Skewed-Normal分布的峰度接近标准正态分布的峰度⑤,特别地,在λ=0时退化为正态分布。我们使用两种方式对厚尾性进行检定,一种是Skewed-t分布和Skewed-Normal分布的比较,一种是标准t分布和正态分布的比较。偏峰与否等价于λ是否为0,从结果中看,残差的偏斜程度因股票而不同,指数数据存在着相当的偏斜,某些股票(特别是使用“收盘价一收盘价”收益率模型时)并没有出现明显的偏斜。下面使用传统的似然比检验对上述假设进行推断:
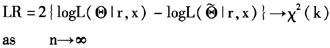
其中,k是约束的个数。做检验用的数据集和模型估计用的数据集一致。为了讨论方便,我们对不同模型进行如下设定:SKT为基于Skewed-t分布的Realized GARCH模型;SN为基于Skewed-Normal分布的Realized GARCH模型;T为基于Student's-t分布的Realized GARCH模型;N为基于正态分布的Realized GARCH模型;SKTd为基于Skewed-t分布的Realized GARCH模型且不约束d为2;Td为基于Student's-t分布的RealizedGARCH模型且不约束d为2。表2给出对数似然函数的值,表3给出似然比检验的值。
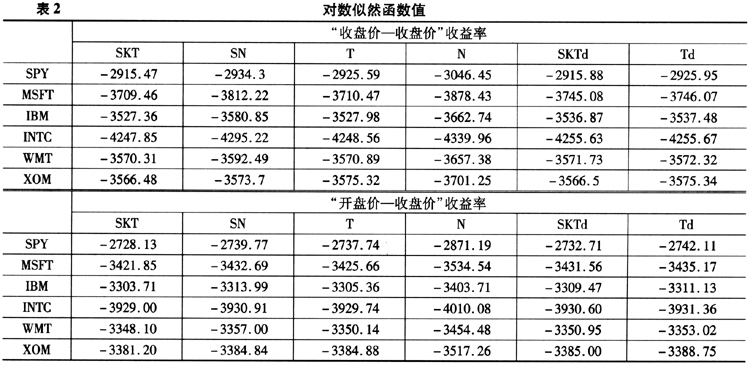
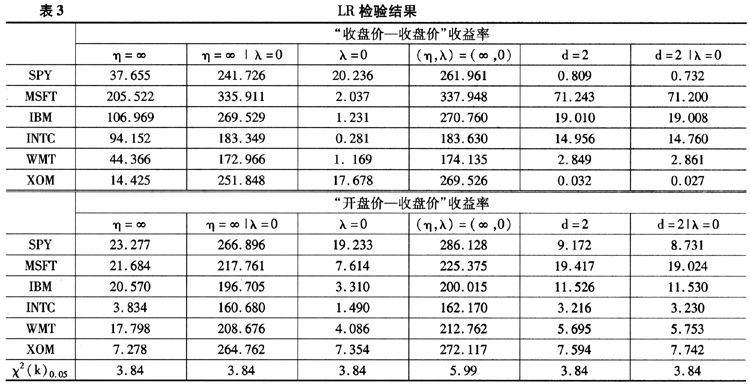
表3中的前两列对应着厚尾性的检验⑥。如前所述,我们使用两个不同的尾部厚度标准。第一列以容纳了偏峰性质的Skewed-Normal分布为标准,用比较SKT和SN模型的结果来实现;第二列以正态分布为标准,用比较T和N模型的结果来实现;第三列对应着偏峰性质的检验,使用比较SKT和T模型的结果来实现;第四列对应着偏度和峰度的联合检验,用比较SKT和N模型的结果来实现;最后两列对应着τ(z)函数的设定检验,分别讨论了允许残差分布偏峰和不允许残差分布偏峰两种情况。从结果可以看出,无论是使用“收盘价一收盘价”收益率还是“开盘价一收盘价”收益率,都无法消除残差的非正态性质。对比关于偏度和峰度的两个单独的检验,除了使用“开盘价一收盘价”收益率的INTC数据略微不到5%显著性水平以外,个股和指数数据都显示模型残差有着强烈的厚尾性质。相比而言,偏峰的性质在统计上就要弱很多,甚至在使用“收盘价一收盘价”收益率模型之下大量的不显著。
综合以上3点可以看出,残差非正态性质更显著地由残差的厚尾性质导致。残差的偏峰性相对不显著的原因可能是Realized GARCH模型本身的结构本身就可以产生相当的偏度,并不需要附加的分布再进一步产生偏度了(Hansen等,2011)。但是由于厚尾性质要强烈的多,使用正态分布为基础的Realized GARCH模型并不能产生足够峰度,因此需要使用厚尾分布来进一步描述数据。最后两列是关于τ(z)函数设定的检验,指数数据以及相当比例的个股数据显示,将d作为待估参数,让数据决定最优的d,会显著地提升模型对于数据的拟合。这同时也说明,标准Realized GARCH模型设定敏感程度d=2并不总是合适的,为了更好地估计“信息冲击曲线”曲线,有必要将d也作为一个待估参数。放松d=2的另一个可能的好处在于压缩波动率预测的置信区间。这是因为τ(z)实际上是随机冲击到波动率的一个映射,给定其他参数不变,每单位冲击对于波动率的影响实际上是随着d的增大而增大的。由于我们的结果中绝大部分的情况下d<2,因此每单位冲击对于波动率的影响并没有标准模型那么大,也就是说给定冲击z的置信区间,映射出来的τ(z)要比标准模型小。
图2(见下页)给出的结果是Skewed-t分布的Realized GARCH模型残差和Skewed-t分布的对比,其参数使用由MLE估计出来的参数。对于之前基于正态分布的Realized GARCH模型,Skewed-t模型确实显著地改进了基本模型不能拟合偏峰厚尾特征的缺陷。
Wantanabe(2011)用S&P500数据估计SKT模型的结果指出,厚尾分布可以改善Realized GARCH模型对于收益率的VaR值的估计。除了VaR计算以外,Realized GARCH模型的另一个能力是预测实现测度的值,这是传统GARCH-X模型不能做到的。表4给出了不同模型设定下实现核估计(Realized Kernel)的一步预测。本文使用Patton(2011)提出损失函数族对模型的预测能力进行评价。Patton(2011)给出的损失函数族为:
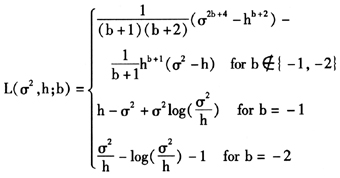
这里我们使用两个参数设定b=0和b=-2。前一种对应MSE评价标准,后一种对应QLIKE评价标准,这两种标准都是评价中常用的标准。特别地,QLIKE标准对于波动率低估给予了附加的惩罚。

Diebold和Mariano(1995)指出在零假设之下S~N(0,1)。因此5%显著性水平对应的关键值为1.96。
 是长期方差,我们使用Newy-West方法进行估计,核函数选为Bartlett核,窗宽采用Anderws(1991)提出的最优窗宽。
是长期方差,我们使用Newy-West方法进行估计,核函数选为Bartlett核,窗宽采用Anderws(1991)提出的最优窗宽。b=0和b=-2两列给出了损失函数的值,“T/SKT vs.N”为T模型和SKT模型相比于N模型预测损失函数差值的DM统计量,“SKT vs.T”为SKT模型和T模型性相比预测损失函数差值的DM统计量。
从结果上看,使用厚尾分布的Realized GARCH模型得到的一步预测在大部分的情况之下都比标准Realized GARCH模型的表现要好。特别地,使用标准t分布的Realized GARCH模型在两种评价标准之下都比标准Realized GARCH模型表现好。并且从DM统计量上看,大部分情况下T模型对于N模型的改进在统计上是显著的。相应地,SKT模型对于N模型的改进大部分情况下并不显著,在某些情况之下甚至比N模型的结果还要差,甚至是在统计上显著地差。最后,SKT模型和T模型相比,大部分情况下在统计上表现要差。这种现象和Want-anabe(2011)在VaR计算问题上一边倒的支持SKT模型的结果不同,这里的结果显示,在预测问题上使用单纯的厚尾分布如标准t分布较正态分布是有优势的,但是使用Skewed-t分布回事优势丧失。这里有两个可能的原因,一个是Wantanabe(2011)只讨论了指数数据,我们这里相应地还讨论了个股数据,两者表现不一致是有可能的;另一个更本质的原因在于,SKT模型可能出现了过度拟合的状况,导致虽然样本内拟合上面表现出色,但是在样本外预测上面表现欠佳。使用不同的收益率计算方式并不影响结果。基于这个结论,我们建议在进行拟合时,使用SKT模型较好,但是在进行预测时,采用T模型可能是一个更好的选择。
四、结论
厚尾现象是金融事件序列的一个普遍特征,本文显示,Hansen等(2011)提出的Realized GARCH模型并不能很好地描述收益率序列的厚尾现象。因此本文推广基于正态分布的模型到基于厚尾分布的情形。具体地,我们使用Skewed-t分布作为残差分布,并以此建立似然函数估计模型参数。结果证实了模型残差确实不遵循正态分布,并且这种非正态源于残差的厚尾特征,其偏峰特征并不总是明显的。这可能是因为Realized GARCH本身的结构产生的偏度已经足够,但是其产生的峰度不足,仍需要使用厚尾分布来矫正。使用Skewed-t分布以后,残差的实际分布和理论分布已基本吻合。
另外,为了更好地估计“信息冲击曲线”,我们将杠杆函数的幂次系数放松为由数据确定的待估参数。结果显示对于“开盘价一收盘价”收益率而言,其“信息冲击曲线”的幂次系数相对稳定,在1.5左右,并且显著地异于基本模型中设定的2。较小的幂次系数说明基本模型的设定把波动率对于收益率冲击设定的太大了。
本文同时对比了厚尾分布设定和正态分布设定之下的Realized GARCH模型进行实现测度一步预测的能力。从结果来看,厚尾分布相对于正态分布确实能够显著改善Realized GARCH模型的预测能力,但是由于存在着可能的过度拟合情况,Skewed-t分布Realized GARCH模型表现的显著地差于标准t分布模型。因此我们建议在追求拟合或者检验假说时宜使用Skewed-t分布假设,但是在预测的时候则应该使用相对简单的标准t分布假设。
注释:
①如实现波动率(Realized Variation,RV),二次幂变差(Bipower Variation,BV),实现核估计(Realized Kemel,RK)等。
②这里的信息冲击曲线和传统定义差一个系数,详见后文。
③Skewed-t分布也被国内学者应用于收益数据建模,如徐炜和黄炎龙(2008)就用Skewed-t分布结合GARCH模型计算VaR。这种标准化的分布也被彭作祥和庞皓(2005)用于讨论单位根检定。
④闫妍等(2011)指出,一般情况下直接使用t分布拟合收益率时,其自由度一般接近于3。由于Realized GARCH模型结构本身就可以产生一定的超额峰度,因此此处其自由度相对较大,即残差相对接近正态。
⑤当λ不为零时,Skewed正态分布的峰度比3略大,但最大不超过4。对于我们使用的股票数据|λ|<0.2,相应的峰度小于3.07,近似标准尾部厚度。
⑥LR检验得到的结果和前面直接做t检验得到的结果并不总是相同的。严格地讲,t检验应该使用Sandwich Estimator,但是按照我们的模型设定比较难以计算。因此我们报告的是普通标准差,仅供参考。
参考文献:
[1]Andersen T. G. and Bollerslev T., 1998, Answering the Skeptics: Yes, Standard Volatility Models Do Provide Accurate Forecasts[J], International Economic Review, 39(4), 885~905.
[2]Andrews D. W., 1991, Heteroskedasticity and Autocorrelated Consisitent Covariance Matrix Estimation[J], Econometrica, 59(3), 817~858.
[3]Bollerslev T., 1986, Generalized Autoregressive Conditional Heteroskedasticity[J], Journal of Econometrics, 31(3), 307~327.
[4]Bollerslev T., 2010, Glossary to ARCH(GARCH)[M], Volatility and Time Series Econometrics.
[5]Diebold F. X. and Mariano R. S., 1995, Comparing Predictive Accuracy[J], Journal of Business & Economic Statistics, 13(3), 253~263.
[6]Engle R. F., 1982, Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation[J], Econometrica, 50(4), 987~1007.
[7]Engle R. F. and N. Victor, 1993, Measuring and Testing the Impact of News on Volatility[J], Journal of Finance, 48(5), 1749~1778.
[8]Engle R. F. and Gallo G. M., 2006, A Multiple Indicators Model for Volatility Using Intra-Daily Data[J], Journal of Econometrics, 131(1), 3~27.
[9]Glosten L. R., Jagannathan R. and Runkle D. E., 1993, On the Relation between the Expected Value and the Volatility of the Nominal Excess Returns on Stocks[J], Journal of Finance, 48(5), 1779~1801.
[10]Hansen B., 1994, Autoregressive Conditional Density Estimation[J], International Economic Review, 35(3), 247~264.
[11]Hansen P. R., Huang Z. and Shek H., 2011, Realized GARCH: A Joint Model of Returns and Realized Measures of Volatility[J], Journal of Applied Econometrics, Forthcoming.
[12]Nelson D. B., 1991, Conditional Heteroscedasticity in Asset Returns: A New Approach[J], Econometrica, 59(2), 347~370.
[13]Patton A. J., 2011, Volatility Forecast Comparison Using Imperfect Volatility Proxies[J], Journal of Econometrics, 160(1), 246~256.
[14]Shephard N., and Sheppard K., 2010, Realizing the Fature: Forecasting with High Frequency Based Volatility(HEAVY)Models[J], Journal of Applied Econometrics, 25(2), 197~231.
[15]Wantanabe T., 2011, Quantile Forecasts of Financial Returns Using Realized GARCH Model[R], Working Paper.
[16]闫妍、朱晓武、熊爱民、李权葆、陈晓松:《金融危机后世界主要股票指数的金融风险:基于t分布的实证研究》[J],《系统工程理论与实践》2011年第5期。
[17]彭作祥、庞皓:《具有GARCH-Skew-t误差项的时序的单位根检验》[J],《数理统计与管理》2005年第6期。
[18]徐炜、黄炎龙:《GARCH模型与VaR的度量研究》[J],《数量经济技术经济研究》2008年第1期。^