内容提要:统计数据质量重要性催生出各国用于数据质量评估的框架、系统,IMF制定的数据质量评估框架因其结构完整性和较强归纳性受到成员国的广泛采用。文章通过运用信息熵理论对数据质量评估框架(DQAF)本身的维度、指标信息量问题进行研究,研究结果显示:DQAF各维度、指标在账户内部以及不同账户间体现的信息量不同;统计数据账户的生产主体和账户数据类型对于数据质量具有明显的影响作用。基于上述结论,作者提出对DQAF框架的改进设想。
关键词:统计数据质量数据质量评估框架(DQAF)信息量
作者简介:汤琰(1983-),女,中国人民大学统计学院博士研究生,主要从事抽样技术和数据分析、统计数据质量研究;金勇进(1953-),男,中国人民大学应用统计科学研究中心教授,博士生导师,主要从事抽样调查、应用统计、数据质量研究(北京100872)。
高质量的统计数据对于数据分析以及后续研究和政策制定具有非常重要的作用,不理想的统计数据极有可能导致数据分析结果与实际情况大相径庭,从而影响后续的政策决定和调控结果,上世纪末至今频繁爆发的全球经济危机便是最好的说明。低质量的宏观经济数据造成各经济体货币、资金和财政政策措施向破坏经济的方向发展,因此对数据进行评估是保证数据质量的重要工作。尤其是对于宏观经济数据,因其无法重复试验进行验证,最终数据的使用者往往缺乏评价数据质量的原数据或者信息,为此,IMF开发了一套专门用于评估数据质量的框架体系——DQAF。数据质量评估框架(全称Data Quality Assessment Framework,简称DQAF)是国际货币基金组织(IMF)以联合国政府统计基本原则为根本构建的数据质量评估框架体系。
一、数据质量评估框架
(一)数据质量评估框架的产生及发展
20世纪90年代以来,世界一些地区金融危机频繁爆发。1994年末和1997年的两次金融危机给IMF一个深刻教训,也对其职能提出了挑战。在总结经验教训的基础上,IMF认为,在新的国际经济、金融形势下,必须制定统一的数据发布标准,为了使各成员国按照统一程序提供全面、准确的经济金融信息,IMF着手制定数据发布标准,并针对成员国的实际状况将标准分为两个层次:第一层是为那些已经参与或正在谋求参与国际金融市场的国家(包括多数工业化国家和一些新兴市场国家)制定的标准,称之为“数据公布特殊标准”,即SDDS;第二层是为所有尚未达到SDDS要求的成员国制定的另外一套标准,称之为“数据公布通用系统”,即CDDS。1996年4月和1997年12月,SDDS和GDDS分别制定完成。在GDDS制定完成同时,一份向IMF监督组织递交的数据信息有关规定进度报告中初步形成数据质量评估框架的雏形,数据质量的重要性在2000年3月数据标准倡议第三次报告和同年6月开展的数据监督目标讨论中得到再次强调。2001年7月,一份关于DQAF的结构提纲提交至IMF执行委员会,执行委员会非常认可DQAF,支持对它进一步综合,构成用于标准和代码执行情况报告(ROSC)的数据模块。2003年7月,国际货币基金组织于正式公布出台DQAF。
(二)数据质量评估框架及其应用
根据联合国政府统计的基本原则,该评估框架在一组前提条件下,核心部分由数据质量的五个维度共同构成,分别是保证诚信、方法健全性、准确性和可靠性、适用性和可获得性,对统计数据质量的机构环境、统计过程和统计产品特征等都列出了相应的考察方面和标准要求[1]。该框架具有层级结构,一般框架的维度设置适合于所有数据表集,考察对象比较多元,包括国民账户统计数据、消费者价格指数数据、生产者价格指数、政府财政统计数据、货币金融统计数据、国际收支平衡统计数据。DQAF评估框架体系的诞生使得国际货币基金组织成员国对本国宏观经济统计等数据账户质量的评价提供了可能,操作思路是将各国(经济体)的统计实践情况与国际普遍认同的理想标准框架(DQAF)进行比较。DQAF对数据质量内涵的界定比较完整、归纳性也比较强,同时提供了具体的评估元素和评估指标并给出了相应的详细解释,这些因素使该框架相对的可操作性较强。
自该框架诞生以来,关于DQAF的研究工作多在IMF内部负责数据质量的部门开展,研究内容主要包括基于定性层次将其与其他组织的数据质量评估标准相比较,该框架在各成员国的应用情况等。具有代表性的是Lucie Laliberté,Werner Grünewald和Laurent Probst(2004)将数据质量评估框架与欧盟的数据质量执行标准进行比对,从框架整体及概念定义、制度组织、统计核心程序和统计产品几个方面定性阐述了DQAF与欧盟数据质量执行标准的异同点[2];该框架随着我国统计工作的国际化逐渐为我国学者所关注,高艳云(2008,2009)主要运用数据质量评估框架将我国CPI数据质量与美国、加拿大、英国等国家进行对比,基于该框架的维度从数据编制、发布等工作中找出我国统计数据质量工作上存在的问题[3-4]。以往对数据质量评估框架的研究工作主要基于定性层面,研究者亦默认该框架的维度设置和指标构建已基本健全完善。
在肯定该框架的同时,我们应该思考:框架中的维度和各维度下的指标在考察各国统计数据质量的过程中到底能向人们传达多少信息?是否能够或者在多大程度上识别出国家或者经济体的数据质量水平整体状况?DQAF在不同类型账户数据质量评价工作中的效果是否存在差异?这些问题的研究对于进一步完善框架体系具有重要意义,也为现实统计数据质量管理工作提供差异化的指导意见。本文将运用信息熵理论对上述问题给出定量化分析。
二、信息论原理
在信息学中,信息传输的目的就是消除或部分消除不确定性从而获得信息。1928年,R. V. L. Hartley在其论文“Transmission of Information”中提出信息定量化的概念,首次提出用对数度量信息的设想,将一条信息所包含的信息量定义为它可能取值个数的对数[5]。二十年后,Claude Elwood Shannon发表了一篇名为“A Mathematical Theory of Communication”的论文,创造性地采用概率论来研究信息传导问题,对信息给予了科学的定量描述,标志着信息论的创立[6]。按Shannon对信息的定义,信息所含信息量的度量就是要确定接收者在接收到消息后能够解除的对信息源所存疑义(不定度)。若把信息看做随机事件,则可以运用概率来测定其不确定性大小,首先引入一系列相关概念和性质说明。
信息可以看成一个离散随机变量,该变量形成的概率空间表示为:
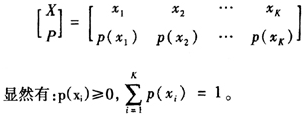
(一)自信息

(二)信息熵
单个符号的不确定性不足以代表信息源的不确定性,由此引入信息熵的概念。在统计热力学中,熵是系统无序状态的量度,由Rudolf Clausius提出[7]。信息论利用统计热力学中熵的概念,对所有符号的自信息量进行统计平均,因此信息熵也称平均自信息量。
如果信息源X可以发送出K种信息,则该信息源的信息熵表示为:

信息熵作为一个统计平均量,它的方差统计量由delta方法定义,具体形式如:
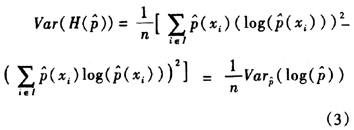
上式可以借助多项分布的性质和样本均值、方差的基本性质进行简化:
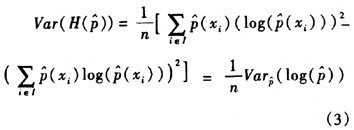
(三)相对熵
相对熵由Solomon Kullback和Richard Leibler在1951年提出。概率论中将两概率分布之间的距离或差异表示为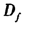 (P||Q),定义P和Q为分布在空间Ω的两概率分布,且P关于Q绝对连续,则对于凸函数f(f(1)=0),Q关于P的f离散度定义为[8]:
(P||Q),定义P和Q为分布在空间Ω的两概率分布,且P关于Q绝对连续,则对于凸函数f(f(1)=0),Q关于P的f离散度定义为[8]:
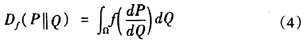
在Bregman[9]离散概念下,推导出当X,Y,为非连续信息源时,两信息源之间的KL离散距离为:

相对熵作为一个统计量,用它对总体进行推估需要计算它的样本方差:
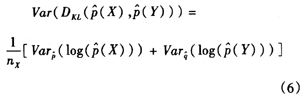
三、数据质量评估框架的信息量分析
DQAF自2003年7月正式出台以来被国际上很多国家用来评估数据质量状况,IMF不定期地对成员国数据质量工作进行考核,各成员国关于标准和代码执行情况的数据模块报告(ROSCs)便是以DQAF作为组织框架。
目前对各国数据质量工作考察的量化工作还比较薄弱,IMF只能对各成员国按DQAF中各维度下各指标的操作情况进行定性评价,评价结果分为四个等级,分别为:(1)符合要求。指当前数据质量开展工作情况基本符合或达到国际公认的DQAF数据标准,实际操作过程中没有明显的缺陷;(2)大部分符合按要求。指当前实践情况与DQAF标准存在一些差距,但是不至于导致对部门统计能力怀疑和影响数据的可信度;(3)大部分未符合要求。指当前数据质量管理实践情况与DQAF存在明显差距,该部门需要努力采取有效措施来满足DQAF要求;(4)不符合要求。指当前实践情况大部分没有达到DQAF框架要求。显然,考察结果评定较为粗糙,但却是目前仅有的可以用于量化分析的数据。这些评价结果虽然是定序的,但各等级之间的差距不可度量,因此标准的统计分析方法使用起来不能满足基本假设,基本的统计指标均值、方差都失去了计算基础和解释意义。基于此,在现有数据资料基础上,运用信息论知识对DQAF本身进行分析仍具有一定的指示和引导作用。
(一)数据来源及情况说明
目前,国际货币基金组织共有187个成员国,自2003年DQAF正式公布至2010年,共有61个成员国向IMF提交了数据质量评估报告,报告总量已有100多份,其中有些国家递交报告的频率较高。本文分析在样本收集时作了一些取舍,对于提交报告频率较高的国家,笔者认为,在一段时间内同一个国家数据质量管理工作存在较高程度的相关性,如果全部入样,有可能歪曲DQAF实施情况的总体结构,因此,选取该国最近一次提交的数据质量报告情况作为样本,以此为标准,共收集了61份报告。经过整理发现,各国的数据标准和代码执行报告中主要涉及6个账户,分别为:国民经济账户、消费者价格指数(CPI)、生产者价格指数(PPI)①、政府财政账户、货币金融统计账户和国际收支平衡账户。因为有少数国家没有对所有账户的数据质量进行报告,因此最终收集结果中,消费者价格指数和生产者价格指数的样本量较少,分别在41~44,30~31范围内,其他四个账户样本量基本在50~54范围内,详细数据查阅IMF官方网站,这里因篇幅限制略去。
按评价等级对原始数据进行了初步汇总后可以看出,不管从账户类别角度还是从DQAF维度、指标角度来看,样本国家对本国执行DQAF标准的情况评价大部分都为“符合要求”,“不符合要求的”情况非常稀少。
(二)单个数据账户下的信息熵
基于本文理论部分关于信息熵的测算方法,首先测算DQAF各个维度、指标在不同账户中的信息含量情况。需要说明的是,由于本文分析的样本仅为IMF187个成员国中的61个,因此在对考察总体的各个统计量进行推断时,需要运用如下公式对总体进行推估:

其中,T表示目标总体,S表示样本。
根据计算结果作图(见图1~6),并对结果进行解读。从图1中可以看出,对于国民经济账户,DQAF中各个指标的信息量都在1~1.4范围内。账户内部比较发现,准确性和可靠性维度下的“修正研究”指标包含的信息量最大,依现实情况而言,各国对于统计数据的修正研究执行情况差异最大,修正研究主要是要求各国或经济体定期对数据修正情况进行研究和分析,并用来在内部对于统计程序提供信息,笔者在收集数据资料的过程中也发现,只有英国、美国、加拿大等少数几个统计技术较强的国家对国民经济账户的修正研究做到定期、定量研究,很多国家对国民经济账户的修正研究基本处于起步阶段,缺乏体系和制度性。其次是质量前提条件维度下的“资源”指标,具体观察在DQAF中对资源指标的细化指标(这里指DQAF中严格意义的指标),“资源”指标的考核标准细分为:(1)满足统计规划需要的人力、设备和计算机资源;(2)采取能够确保资源有效使用的措施。从这个角度可以看出,各国在国民经济账户数据生产中用于保障数据质量工作的硬件条件差异较大。
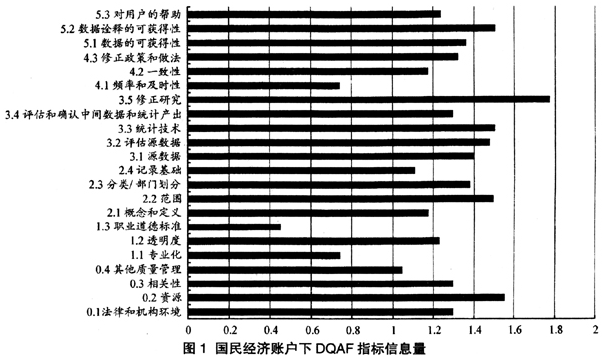
显然,国民经济账户下,DQAF中保证诚信维度下的“职业道德标准”指标的信息量最小,从数据收集原始资料可以看到,各国无论自身对于该项要求的执行情况如何,都判定本国统计机构工作人员职业道德标准符合国际要求;此外,保证诚信维度下的“专业化”指标和适用性维度下的“频率和及时性”指标包含的信息量均比较小。这说明,依据DQAF对各国统计数据质量工作进行考察时,从“职业道德标准”、“专业化”、“频率和及时性”指标上不能区分各国数据质量管理工作该方面的优劣和执行力度。从标准角度来看,该三项指标的标准和内容规定与其他指标相比可识别性不强,从现实角度来看,该现象的存在也可能是因为各国在实际工作中对标准的执行力度大致在一个水平上。
从图2中可以看出,相对于国民经济账户来说,CPI账户下DQAF中各个指标所包含的信息量总体上比较小,多数指标包含的信息量在0.8~1.4范围内。在CPI账户内部进行内部比较发现,该账户下“频率和及时性”指标包含的信息量最小,其次是“职业道德标准”和“专业化”,另外适用性维度下的“一致性”指标包含的信息量也较小,同样,造成这种现象有两种可能,一是指标本身的考察识别性较低,而是各国在现实操作中水平基本持平;与此同时,质量前提维度下的“资源”指标所包含的信息量最大,从这个角度可以看出,各国在CPI数据生产中用于保障数据质量工作的硬件条件差异较大。此外,方法健全性维度下的“范围”指标、准确性与可靠性维度下的“源数据”、“统计技术”指标和可获得性维度下的“数据诠释的可获得性”指标所包含的信息量也较大。由此可见,各国在CPI数据质量工作过程中对上述几个方面的执行情况存在较大的差异。

从图3中可以看到,生产者价格指数账户中,“职业道德标准”和“专业化”指标仍然是信息含量最低的指标,“资源”、“源数据”、“统计技术”和“数据诠释的可获得性”指标是信息含量较高的指标,各国PPI。账户统计数据工作在这些方面的差异性较大,其他指标的信息含量也基本落在0.8~1.4的范围内。从图形上看,PPI账户下DQAF指标的信息量状况与CPI账户下具有较强的相似性。
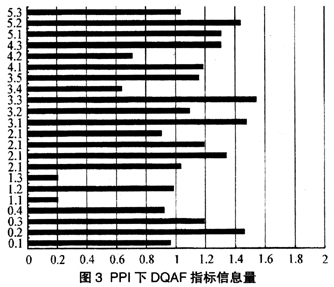
图4给出了政府财政账户下DQAF的指标信息量情况,从图形上看,该账户下的信息量分布情况显然与其他几个账户不同,总体上各指标的信息量相对较大。相同的是,“职业道德标准”指标的信息量仍然最小。大多数指标的信息含量在1~1.6范围内。比较突出的是“修正研究”指标,该指标的信息含量已经接近信息含量的最大值2,从理论上来说,只有当信息源各个信号的发生概率相等时,该信息源的信息量达到最大,对于政府财政账户而言,该现象一方面说明该项指标的考察力度较强,另一方面也说明各国政府财政账户数据在修正研究工作的实践上存在非常大的差距。此外,政府财政账户下,“资源”指标、方法健全性维度下的“范围”、“分类/部门划分”和“源数据”指标所含信息量都比较高,这是因为各国政府财政账户的统计工作势必会根据各国整体经济条件、政府的层级结构、工作模式等特点选择适合自己的做法,从而造成在这三个指标上,各国间对标准的执行情况差异较大。从图上还可以看出,政府财政账户在整个可获得性维度上的差异都非常大,这源于各国政府在政府财政公开透明化方面的现实做法存在非常大的差异。

图5是货币金融统计账户下的DQAF指标信息量情况图,与其他账户很显然的差别在于该账户下“职业道德标准”指标的信息量为0,这意味着所有成员国在货币金融统计账户数据质量管理工作中职业道德标准的执行水平完全一致。结合数据收集原始资料,所有样本国的货币金融统计账户下“职业道德标准”的判定均为“符合要求”。关于这一点,有必要追溯DQAF的起源。正如本文第二章中所述,两大数据公布系统和DQAF本身都是因为世界性金融危机的频繁爆发而催发的,因而撇开该指标本身考核力度的有效程度,各国货币金融统计账户的管理工作能够严格按照统一职业道德标准执行便不难理解。

此外,该账户下“专业化”指标的信息量仍然非常小,同样“统计技术”指标的信息量也较小。该账户下各指标的信息含量多数在0.8~1.4范围内,比较突出的是可获得维度下“数据诠释的可获得性”指标和适用性维度下的“修正政策和做法”指标,信息含量均在1.4以上,说明IMF成员国在货币金融统计账户的数据质量管理工作中在这两个方面的执行情况差异较大。
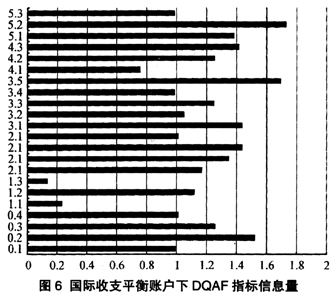
国际收支平衡账户下DQAF指标信息量情况反映在图6中。图中,大多数指标的信息含量都在1~1.6范围内,在这一点国际收支平衡账户和政府财政账户的情况很相似。该账户下,DQAF中“职业道德标准”指标的信息量依旧很小。其次是“专业化”指标,比较突出的是“修正研究”和“数据诠释的可获得性”指标,二者信息量均在1.7左右,说明各成员国在国际收支平衡账户的统计数据质量管理工作中对这两项标准的执行情况差异较大。此外,国际收支平衡账户下,“资源”、“分类/部门划分”和“源数据”指标的信息含量也较大,都处于1.4~1.5之间。
(三)数据质量评估框架的离散度分析
从各个账户的指标信息量图示中可以看出,DQAF在不同账户间的信息量存在差异,指标信息量与账户类型呈现出特定关系。这里对6个被考察账户基于DQAF的数据质量情况进行KL离散度分析,这里需要说明的是,KL离散度距离度量是不对称度量,因此表中对角线两侧的上三角部分与下三角部分数值并不对称相等。结果见表1、表2。
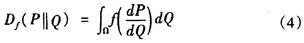
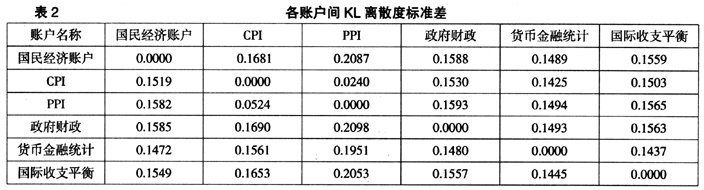
结合表1、表2描述各账户间离散度大小及其显著性,见下页表3。

从表3中可以看出以下几点通过统计显著性检验的结论:(1)政府财政账户与货币金融统计账户之间的信息离散度较大;(2)CPI与政府财政账户、货币金融统计账户之间具有较大的信息离散度;(3)PPI与政府财政账户、货币金融统计账户之间具有较大的信息离散度;CPI与PPI之间的信息离散度较小。可见,统计数据的生产部门不同,运用DQAF对数据质量进行考核所反映的信息差异较大;相同的数据类型下,运用DQAF对数据质量进行考核所反映的信息差异较小。
四、结论与展望
通过对DQAF各维度及所属指标在不同账户内信息量的测算,发现DQAF各维度和指标在账户内部以及不同账户间体现的信息量都不同,且总体看来,保证诚信维度下的“职业道德标准”和“专业化”指标对各国或经济体进行统计数据质量考核能获取的信息很少,一方面源于该两项指标在考核标准的设置上比较笼统,在被考核个体间缺乏识别性;另一方面也说明各国在这两项指标的操作实践上缺乏显著的差异性;相比之下,“数据诠释的可获得性”、“资源”、“修正研究”、“源数据”和“范围”指标对于考察成员国数据质量管理评估工作标准执行情况的差异识别度较好,同时也说明各国在统计数据质量管理评估工作中在上述几项指标的执行情况上差异较大。
在DQAF的维度层次上,保证诚信维度在统计数据质量评估管理中的差异体现能力较弱,而可获得性维度的差异识别性最强,中间从弱到强分别为质量前提条件、准确性和可靠性、方法及安全性和适用性维度。
从账户之间的信息离散度可以得出:
(1)统计数据账户的生产主体对于数据质量具有明显的影响作用,一般来说,一国政府财政账户的统计数据收集、整理、汇编工作一般由政府财政部门内部核算,一国货币金融统计账户的统计数据工作一般由中央银行负责,CPI数据一般由专门的统计部门负责收集、整理、编制。因此,统计数据的生产部门不同,运用DQAF对数据质量进行考核所反映的信息量不同,数据质量的差异也相对较大。
(2)账户的数据类型也对DQAF下数据质量的评估工作有影响,研究结果中,CPI和PPI都属于指数型数据,很明显基于DQAF对这两个账户的数据质量进行考核所反映出的信息量离散度不大,说明DQAF在反映统计数据账户质量差异上关于数据类型具有同质性。
所得结论对于DQAF今后的完善和我国今后改进统计数据质量的评估、管理工作具有很好地参考价值。囿于DQAF是国际性的评估框架,对其采取显著的改动目前看来是不现实的,但根据上面的分析结论,我们认为针对框架可以考虑将信息量较低、对数据质量评价识别度较低的维度和指标进行改进,制定确实可行的量化标度用于数据质量考核评估。
同时,上述结论对我国今后改进和完善统计数据质量评估管理工作也是具有指导意义的,在我国建立自有的数据质量评估框架问题上,我们提出以下几点设想:
(1)考虑将信息量较低、对数据质量评价识别度较低的维度和指标进行改进,制定确实可行的量化标度用于数据质量考核评估;
(2)针对数据生产部门的不同,DQAF应该制定更加具有针对性的考核细则,结合生产部门的性质和工作模式提出相应的考核评价标准和量化细则;
(3)对不同数据类型制定不同的评估标准和细则,根据统计数据的基本类型建立个性化的考核机制和细则。
注释:
①个别国家使用零售商品价格指数(RPI)代替PPI,但仔细对照后发现只是名称使用差异,而包含内容与PPI基本相同,故将其与PPI同等对待。
参考文献:
[1]常宁.IMF的数据质量评估框架及启示[J].统计研究,2004(1):27-30.
[2]LALIBERT
 NEWALD WERNER, PROBST LAURENT. Data Quality: A Comparison of IMF's Data Quality Assessment Framework(DQAF)and Eurostat's Quality Definition[R].Brussels: The Statistical Programming Committee of the European Union, 2002.
NEWALD WERNER, PROBST LAURENT. Data Quality: A Comparison of IMF's Data Quality Assessment Framework(DQAF)and Eurostat's Quality Definition[R].Brussels: The Statistical Programming Committee of the European Union, 2002.
[3]高艳云.中美CPI数据质量的比较分析——基于国际货币基金组织的DQAF框架[J].统计研究,2008,25(11):51-56.
[4]高艳云.CPI编制及公布的国际比较[J].统计研究,2009,26(9): 15-20.
[5]HARTLEY R V L. Transmission of Information[J]. Bell System Technical Journal, 1928(7): 535-563.
[6]SHANNON C E, WEAVER W. The Mathematical Theory of Communication[J].Mobile Computing and Communications Review, 1948, 5(1): 3-55.
[7]CLAUSIUS RUDOLF. The Mechanical Theory of Heat: With Its Applications to the Steam-engine and to the Physical Properties of Bodies[M]. London: John Van Voorst, 1867:251-256.
[8]KULLBACK S, LEIBLER R A. On Information and Sufficiency[J]. The Annals of Mathematical Statistics, 1951(22): 79-86.
[9]BREGMAN L M. The Relaxation Method of Finding the Common Point of Convex Sets and Its Application to the Solution of Problems in Convex Programming[J]. USSR Computational Mathematics and Mathematical Physics, 1967, 7(3): 200-217.