内容提要:研究和评估我国基础研究与专利之间的知识转移机制具有重大意义,但目前国内外的研究方法都存在着种种缺陷和不足,使得此类研究的发展受到很大的限制。本文在系统总结国内外有关基础研究与发明专利之间知识转移机制研究经验的基础上,将数据挖掘的有关方法和模式移植到了专利引文分析,建立应用数据挖掘对专利引文数据进行智能分析的创新方法体系,为定量测度基础研究与专利之间的知识转移机制提供了可能。
关键词:数据挖掘 专利引文分析 基础研究 技术创新
作者简介:赵黎明李海霞韩宇天津大学管理学院,天津300072
引言
基础研究如何对科技创新、经济发展、社会进步发挥作用?它产生的效益有多大?这些效益或影响如何评价和测度?这些问题既是研究的重点,同时也是尚未完全解决亟待完善的难点。随着社会经济的发展,对此类问题的研究也越来越复杂,手段和角度也越来越多样化。同时由于知识经济时代的到来,人们对深入理解基础研究与技术创新之间的联系越来越迫切,使得该种研究活动和成果层出不穷。
回顾前人的研究方法,主要有案例研究、计量经济学的方法、费用-效益分析、专利引文分析等,而且多数方法仅是对个别知识、技术领域进行了探索。案例研究能够表明某领域或某一项特定的技术进步可以追溯到基础科学发展的根源,但是由于较长的时滞使得该方法带有明显的事后认识的缺陷;计量经济学的方法更多地应用于从产业层次研究技术研发投入与经济增长的关系,而且由于跨学科领域、时滞等原因使研发的投入和产出的直接效应比较难以界定和测度,它对分析基础研究对社会经济的间接关系有较大的不利因素;费用-效益分析主要从考察社会效应的角度分析个别研究项目的效益,带有一定的局限性[1~4]。
专利引文分析充分利用专利(文件)作为连接基础研究与应用技术的纽带,发挥专利(文件)能广泛地公开地体现技术发展的进程的作用,更准确地评价基础研究对技术开发的影响以及与社会经济发展的关系。但是专利引文分析由于涉及数据量太大,而处理并分析海量数据比较困难,目前国内基本上还没有研究。因此,创造条件进行相关研究是十分有必要的。目前一些传统的数据库管理系统大部分限于查询统计功能,存在许多缺点和不足,迫切地需要一种能够自动、智能和快速地从数据库中挖掘出有用的信息和知识的技术和方法来解决。数据挖掘正迎合了这种需求,它为在专利引文这个大型的数据仓库中挖掘出基础研究与技术创新之间的关系提供了一种全新的、有效的解决途径。
一、数据挖掘模式的选择和模型的建立
(一)数据挖掘概述
数据挖掘是从大量数据中挖掘隐含的、先前未知的、对决策有潜在价值的知识和规则。这些规则蕴含了数据库中一组对象之间的特定关系,揭示出一些有用的信息,为科学研究、经营决策、市场策划、经济预测、工业控制提供依据。通过数据挖掘,有价值的知识或高层次的规则就能从数据库的相关集合中抽取出来,并从不同角度显示,从而使大型数据库作为一个丰富可靠的资源为知识归纳服务。
(二)数据挖掘模式的选择
数据挖掘的模式主要有聚类、关联规则、序列模式、分类等。聚类是把一组个体按照相似性归成若干类别,其目的是使得属于同一类别的个体之间的距离尽可能的小,而不同类别的个体间的距离尽可能的大。关联规则是寻找在同一个事件中出现的不同项的相关性。序列模式和关联规则相似,其目的也是挖掘数据之间的联系,但序列模式分析的侧重点在于分析数据间的前后序列关系。分类要解决的问题是为一个事件或对象归类。
专利引文是把专利作为联系基础科学与高新技术之间的纽带(专利代表了高新技术的发展,专利中引用的科技文献从一定程度上反映了基础科学的研究状况),通过考察专利引用科技文献的情况来了解基础科学与高新技术之间的关系,自然,这要用到关联规则挖掘模式。
(三)关联规则模型
1.关联规则挖掘的基本概念
定义1关联规则挖掘的数据集记为D(D一般为事务数据库),D={t[,1],t[,2],…,t[,n]},t[,k]={i[,1[,k]],i[,2[,k]],…,i[,p[,k]]}(k=1,2,…,n)为一条事务,t[,k]中的元素i[,j[,k]](j=1,2,…,p)称为项目(item)。
定义2I=(i[,1],i[,2],…,i[,m])是D中全体项目组成的集合,I的任何子集X称为D中的项目集(itemset)。{X}=k称集合X为k项目集。设t[,k]和X分别是D中的事务项目集,如果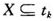 ,称事务t[,k]包含项目集X。
,称事务t[,k]包含项目集X。
定义3数据集D中包含项目集X的事务数称为项目集X的支持数,记为σ[,x]项目集X的支持率,记作:Support(X)。
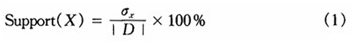
其中|D|是数据集D的事务数。若Support(X)不小于用户指定的最小支持率(记作:min_sup),则称X为非频繁项目集(或小项目集)。
定理1设X、Y是数据集D中的项目集

通常用户挖掘时需要指定最小置信度记为min_con。
支持度和置信度是描述关联规则的两个重要的概念,前者用来衡量关联规则在整个数据集中的统计重要性,后者用来衡量关联规则的可信程度。一般来说,只有置信度和支持度均较高的关联规则才是用户感兴趣、有用的关联规则。
定义5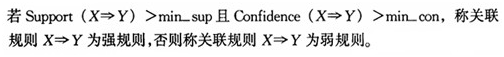 关联规则挖掘的目的就是挖掘出D中所有的强规则[5]。
关联规则挖掘的目的就是挖掘出D中所有的强规则[5]。
2.关联规则挖掘的过程
关联规则的挖掘是一个两步的过程:
(1)找出所有的频繁项集:求出D中满足最小支持度min_sup的所有频繁项集;
(2)由频繁项集产生强关联规则:利用频繁项集生成满足最小可信度的所有关联规则。
第一个子问题的任务是迅速高效地找出D中全部频繁项目集,是关联规则挖掘的中心问题,是衡量关联规则挖掘算法的标准;第二个子问题由(1)式和(4)式可知其求解是比较容易、直接的,目前所有的关联规则挖掘算法都是针对第一个子问题而提出的。
二、基于数据挖掘的专利引文分析工作流程设计
把数据挖掘应用于专利引文分析进行知识发现是一个多步骤的处理过程,其工作流程设计如图1。
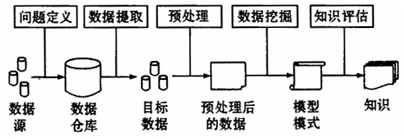
图1基于数据挖掘的专利引文分析工作流程设计
(一)问题定义
了解相关领域的有关情况,熟悉背景知识,明确挖掘目的,即挖掘基础研究与技术创新之间的关系,进而发现知识转移的规律,为国家制定科技政策提供有力的依据。
(二)数据提取
根据挖掘需要从中国专利文献数据库中提取相关的数据。
(三)数据预处理
主要对前一阶段产生的专利引文数据进行再加工,检查数据的完整性及数据的一致性,对其中的噪音数据进行处理,对丢失的数据进行填补。
(四)数据挖掘
运用选定的知识发现算法(关联规则挖掘算法),建立数据挖掘模型,利用相关软件从数据库中提取出用户所需要的知识,这些知识可以用一种特定的方式表示或使用一些常用的表示方式。
(五)知识评估
将发现的知识(基础研究与技术创新之间的关系,基础研究与发明专利之间的知识转移机制等)以用户能了解的方式呈现,根据需要对知识发现过程中的某些处理阶段进行优化,直到满足要求。
三、专利引文数据项体系的建立
目前国内还没有专门的专利引文数据库,需要从中国专利文献库中抽取数据供挖掘,因此数据挖掘是否成功,数据项的预定义非常重要。我们研究专利引文的目的是把专利引文作为联系基础科学与高新技术的纽带,希望通过分析专利引用引文的情况来进一步挖掘基础科学与高新技术之间的关系及基础研究与发明专利之间的知识转移机制。根据研究目的和数据挖掘的特点,通过对专利文献的认真研究,建立如图2专利引文数据挖掘的数据项体系。
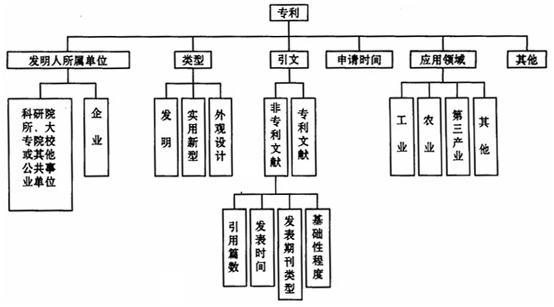
图2专利引文数据挖掘的数据项体系
图中专利引用的文章中包括专利文献和非专利文献,专利文献是指专利引用的其他专利文献,非专利文献是指专利引用的除专利文献以外的文章,主要是指一些发表在科技期刊、杂志或书籍中的论文,这一般被认为是代表了基础科学。
根据我们建立的数据项体系,如果挖掘出:
“专利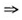 专利引用了非专利文献”是强关联规则,则说明基础研究是技术的基础,技术的发明依赖于基础研究;
专利引用了非专利文献”是强关联规则,则说明基础研究是技术的基础,技术的发明依赖于基础研究;
“专利引用了专利文献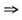 专利引用了非专利文献”是强关联规则,则说明基础研究在增强对已有技术或外来技术的消化、吸收能力方面有促进作用;
专利引用了非专利文献”是强关联规则,则说明基础研究在增强对已有技术或外来技术的消化、吸收能力方面有促进作用;
“专利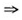 专利发明人所在单位是大专院校、科研院所或其他公共事业性研究单位”是强关联规则,则说明基础研究为高科技发展培养和输送人才,基础研究在培养科技人员的创造性思维和探索精神方面具有促进作用。
专利发明人所在单位是大专院校、科研院所或其他公共事业性研究单位”是强关联规则,则说明基础研究为高科技发展培养和输送人才,基础研究在培养科技人员的创造性思维和探索精神方面具有促进作用。
四、关联规则算法的研究
Apriori算法是一种最有影响的挖掘关联规则的算法,由于它适合于最大项目集相对较小的数据集的挖掘,而专利引文数据具备这个条件。
(一)Apriori算法第1步:使用候选集找频繁项集
Apriori算法的名字基于这样的事实;算法使用频繁项集性质的先验知识,它使用一种称作逐层搜索的迭代方法,k-项集用于搜索(k+1)-项集。首先,找出频繁1-项集的集合,该集合记作L[,1]。L[,1]用于找频繁2-项集的集合L[,2],而L[,2]用于找L[,3],如此下去,直到不能找到频繁k-项集。找每个L[,k]需要一次数据库的扫描。
为了提高频繁项集逐层产生的效率,一种称作Apriori的重要性质可用于压缩搜索空间。
Apriori性质:频繁项集的所有非空子集都必须也是频繁的。Apriori性质基于如下观察:根据定义,如果项集I不满足最小支持度阀值min_sup,则I不是频繁的,即P(I)<min_sup。如果项A添加到I,则结果项集(即I∪A)不可能比I更频繁出现。因此,I∪A也不是频繁的,即P(I∪A)<min_sup。该性质属于一种特殊的分类,称作反单调,是指如果一个集合不能通过测试,则它的所有超集也都不能通过相同的测试。
Apriori算法通过连接和剪枝两步过程来用L[,k-1]找L[,k]。
1.连接步
为找L[,k],通过L[,k-1]与自己连接产生候选k-项集的集合。该候选集的集合记作C[,k]。设L[,1]和l[,2]是L[,k-1]中的项集。记号l[,i][j]表示l[,i]的第j项。为方便计,假定事务或项集中的项按字曲次序排序。执分连接L[,k-1]×L[,k-1],其中L[,k-1]的元素是可连接的,如果它们前(k-2)各项相同。即是,L[,k-1]的元素l[,1]和l[,2]是可连接的,如果(l[,1][1]=l[,2][1])∧(l[,1][2]=l[,2][2])∧…∧(l[,1][k-2]=l[,2][k-2])∧(l[,1][k-1]<l[,2][k-1])。条件(l[,1][k-1]<l[,2][k-1])是简单地保证不产生重复。连接l[,1]和l[,2]产生的结果项集是l[,1][1]=l[,1][2]…l[,1][k-1]l[,2][k-1]。
2.剪枝步
C[,k]是L[,k]的超集;即是,它的成员可以是也可以不是频繁的,但所有的频繁k-项集都包含在C[,k]中。扫描数据库,确定C[,k]中每个候选的计数,从而确定L[,k](即根据定义,计数值不小于最小支持度计数的所有候选是频繁的,从而属于L[,k])。然而,C[,k]可能很大,这样所涉及的计算量就很大。为压缩C[,k],可以用一下办法使用Apriori性质:任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集。因此,如果一个候选k-项集的(k-1)-子集不在L[,k-1]中,则该候选也不可能是频繁的,从而可以由C[,k]中删除。这种子集测试可以使用所有频繁项集的散列树快速完成。
(二)Apriori算法第2步:由频繁项集产生关联规则
一旦由数据库D中的事务找出频繁项集,由它们产生强关联规则是直截了当的(强关联规则满足最小支持度和最小置信度)。对于置信度,可以用(5)式表示,其中条件概率用项集支持度计数表示。
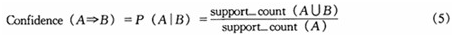
其中support_count(A∪B)是包含项集A∪B的事务数,support_count(A)是包含项集A的事务数。根据(5)式,关联规则可以产生如下:
(1)对于每个频繁项集l,产生l的所有非空子集。
(2)对于l的每个非空子集s,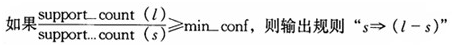 。其中,min_conf是最小置信度阀值。
。其中,min_conf是最小置信度阀值。
由于规则由频繁项集产生,每个规则都自动满足最小支持度。频繁项集连同它们的支持序预先存放在散列表中,使得它们可以快速被访问[6~8]。
五、结束语
本文在系统总结国内外有关基础研究与发明专利之间知识转移机制与测度研究经验的基础上,将数据挖掘的有关方法和模式移植到了专利引文分析,发挥它能够从大量的、不完全、模糊的、随机的数据中自动、有效、智能地提取隐含于其中的有用的信息和知识的优势,克服以往研究方法仅仅是研究少量数据进行浅层次的分析的缺陷与不足,建立应用数据挖掘对专利引文数据进行智能分析的创新方法体系,为定量测度基础研究与专利之间的知识转移机制提供了可能。
参考文献:
1Van Vianen B G,Moed H F,Van Raan A F J.An exploration of the science base of recent technology [J].Research Policy,1990,19:61-81.
2Narin E,Noma E.Is technlogy becoming science[J].Scientometrics,1985,7 (3-6):369-381.
3Collins P.Wyatt S.Citations in patents to the basic research literature [J].Research Policy,1988,17:65-74.
4Schmoch U.Tracing the knowledge transfer from science to techology as reflected in patent indicators [J].Scientometrics,1993,26(1):193-211.
5朱绍文,王泉德,等.关联规则挖掘技术及发展动向[J].计算机工程,2000,26(9):4-6.
6Han J,Kamber M.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.152-157.
7Agrawal R,Mannila H,Srikant R,et al..Fast discovery of association rules [A].In Fayyad M,Piatetsky S G,Smyth P,eds.Advances in Knowledge Discovery and Data Mining [C].Menlo Parkl AAAI Press,1996.307-328.
8Agrawal R,Imielindski T,Swami A.Mining association rules between sets of items in large database [A].Proceedings,ACM SIFMOD Conference on Management of Data [C].Washington D.C,1993.207-216.
教育频道,考生的精神家园。祝大家考试成功 梦想成真!
经济学
基于数据挖掘的专利引文研究与知识发现
http://www.newdu.com 2018/3/7 《预测》2002年第6期 赵黎明 李… 参加讨论
Tags:基于数据挖掘的专利引文研究与知识发现
责任编辑:admin相关文章列表
没有相关文章
[ 查看全部 ] 网友评论