关键词:经验分布函数 平均超出函数 极大似然估计法 卡方检验
作者简介:赵智红,李兴绪,云南财经大学数学与统计学院(昆明650224)
在非寿险业务中,对损失数据所服从的分布的精确估计是一个十分重要的问题。由于非寿险损失的复杂性,必须根据近期损失数据,研究不断发展变化的损失分布,进而达到研究保费计价的问题。近年来,由于非寿险在社会经济中的作用越来越重要,有关的非寿险模型的教科书也很多,但是,在教科书中所列举的例子一般都是设计出来的特殊情况,并且数据量很小,并不涉及利用计算机系统进行计算的问题,所以很难看到有结合实际损失数据系统分析研究并加以解决的可行性完整方法过程。为弥补方法的系统性和可行性不足,本文拟通过实例系统的介绍有大量数据下的损失分布建模问题。
一、工具函数
设X是所考虑的损失分布的随机变量,密度函数为f(x),分布函数为F(x)。
定义1如果有来自某总体的数据:
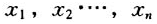 。n充分地大,则该总体的分布函数F(x)可以由下面的函数近似。
。n充分地大,则该总体的分布函数F(x)可以由下面的函数近似。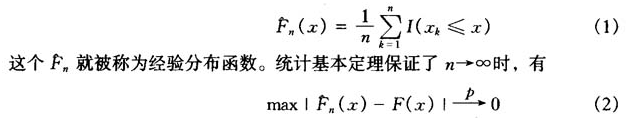
在一定条件下,还可以给出这种收敛的收敛速度。
这种经验分布的优点就是简单,易于理解。但也有明显的缺点:第一,它所给出的分布函数缺乏光滑性;第二,若有截断或者删失造成数据不完全,这种方法只能给出某种条件分布函数,而不是原来要寻找的分布函数。
定义2对于任意的实地损失额X,可以定义它的平均超出函数(mean excess loss)如下:
e(x)=E(X-d|X>d) |
它表示免赔额d所导致的平均超出赔付额。对于一个特定的实地损失额X,其MEL都是免赔额d的函数。在非寿险中损失分布通常具有厚尾分布的特性,而平均超出函数反映的正是随机变量尾部的情况,平均超出函数的图形对于不同的实地损失额有着不同的形状。可对损失数据计算平均超出函数,再与理论平均超出函数的图形进行比较,就可以初步选定分布类。在实际的计算机实现过程中,通常将上述定义转换为如下的经验平均超出函数形式,以便利用计算机编程进行计算:
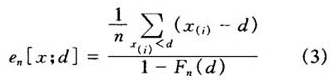
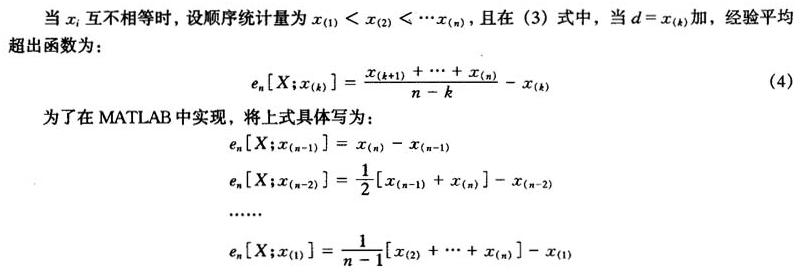
通过上面的思想,可以在MATLAB中编程写计算上面各式的第一项,然后再同第二项作差,得到经验平均超出函数。
经验平均超出函数十分重要,它是选择损失数据服从哪个分布类的重要工具,对于给定的损失数据,必须首先计算出经验平均超出函数。
二、建模过程
对于给定的损失数据,所谓参数化方法就是对某一个总体选定一个参数化了的分布族,并且认为这一总体的真分布应为这一分布族中之一员。
采用参数化方法的全过程分为一下几个步骤:(1)对数据进行初步分析,选定可参数化的分布族;(2)参数估计;(3)检验;(4)修正。
(一)初步分析
初步分析的目的是根据损失数据所表现出来的一些统计特性,选定可参数化的分布族。
1.直方图法
由经验数据做出直方图,再与已知分布族的密度曲线相比较,从中选定一个较接近者。
2.q-q图
经验数据相对于一个理论分布函数F的q-q图是平面上由n个点,若样本真的服从这个理论分布,那么相应的q-q图里的散点基本上应当位于平面上从(0,0)到点(1,1)的连线上。多尝试几种理论分布,通过观测相应的q-q图,可以从中选出比较接近经验数据的一种。
3.经验平均超出函数
将给定的一组损失数据带入定义2中的式(3),如果是一组从小到大的顺序统计量可以代如式(4)。由此,便可以计算出经验平均超出函数值
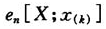 。然后,对应于这组损失数据作出经验平均超出函数的散点图。将该图与几种重要的分布类的平均超出函数散点图作比较,就可以初步判断出该组数据近似服从哪种分布类。
。然后,对应于这组损失数据作出经验平均超出函数的散点图。将该图与几种重要的分布类的平均超出函数散点图作比较,就可以初步判断出该组数据近似服从哪种分布类。(二)参数估计
当选定了备用的参数分布类之后,可以采用匹配方法和优化方法来给出其中参数的估计。所谓匹配方法就是把样本值和理论值进行匹配,由此列出关于参数的方程,方程的解就被当作参数的估计。这类方法中最常见的有矩方法和分位数方法等。所谓的优化方法是指事先给定一个准则,然后在这个准则之下求关于参数的最优解。这类方法中最常见的有最小距离法和最大似然法。
下面,简单介绍一下几种方法。
对于最小距离法,一般的可以理解为下面的情形:
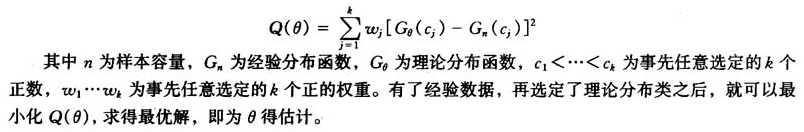

由此解得的最大似然估计。
(三)检验
在得到参数估计之后,还要对结果进行假设检验。这是因为不管采用那一种方法,参数估计所得到的结果仅仅是告诉我们在我们事先选定的分布族中哪一个分布(在某种意义上)离我们的总体最近,而我们事先选定的分布族有可能本来就是不很恰当的分布族,也即有更适当的分布族没能被我们选中。所以采用对参数估计的结果进行检验。

(四)修正
当上述估计没有能够通过假设检验时,就要重新挑选分布族。挑选新的分布族,一方面要依靠数据,另一方面也靠精算师的经验。选定新的分布族之后,再进行上述三个步骤。就这样一直做下去。随着数据的增加,得到的结果将会越来越精确。
责任编辑:夏雨