关键词:数据挖掘 知识获取 数据库
作者简介:熊熊,张维,天津大学,系统工程研究所,天津300072
一、引言
数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。
数据挖掘(Data mining,简称DM)从狭义上是指从数据库中提取知识。具体的说是在数据库中,对数据进行一定的处理,从而获得其中隐含的、事先未知的而又可能极为有用的信息。这些信息通常是以知识、规则或约束等形式来表现。在其他文献中有许多类似的提法,例如:数据分析,知识获取,知识萃取,数据构成[1]等。数据挖掘方法在数据库系统和人工智能领域是一个新方向。这里所说的知识是指大量数据中存在的规律性(regularity)或不同特征属性值之间所存在的[if then]规则。从大量数据中获取知识有两个层次的含义:首先,与科学发现有关。从观测客观世界的大量实验数据(往往是数值)中发现数据的整体结构特性和数据之间的函数关系,并根据统计特征推断客观世界中存在的规律性;其次,与商业数据等事实数据所构成的数据库中发现其中隐含的规则或规律性有关。第二类是将人工智能技术与数据库理论相融合的应用性研究课题。本文主要讨论后者。
数据挖掘的最终目的是发现人们不易察觉的、隐含的模式。一般说来,这些模式中最易于理解的是统计模型。其次是对数据的外围检测,对大规模数据集的模式识别、分类或聚类。最后是从理论和计算上解决在大多数数据库管理系统中存在的多维空间和大量的数据处理的问题。
二、知识获取与数据挖掘
一般说来,知识获取(Knowledge Discovery in Databases,称称KDD)意为数据库中知识获取,它代表从低层次数据中提取高层次知识的全过程,包括数据信息的收集,数据原型的确定,相关函数的分析,知识的抽取和数据模式分析。统计学中常指的是无假设证实所进行的数据测量和分析。而数据挖掘则是指从数据中自动地抽取模型。数据挖掘包括许多步骤:从大规模数据库中(或从其他来源)取得数据;选择合适的特征属性;挑选合适的样本策略;剔除数据中不正常的数据并补足不够的部分;用恰当的降维、变换使数据挖掘过程与数据模型相适合或相匹配;辨别所得到的是否是知识则需将得到的结果信息化或可视化,然后与现有的知识相结合比较。这些步骤是从数据到知识的必由之路。每一步骤都可能是成功的关键或失败的开始。在一般的定义中数据挖掘是知识获取的一部分。
数据挖掘的研究领域涉及广泛,主要包括数据库系统,基于知识的系统,人工智能,机器学习,知识获取,统计学,空间数据库和数据可现化等领域。
(一)统计学
统计学在数据样本选择、数据预处理及评价抽取知识的步骤中有非常重要的作用。以往许多统计学的工作是针对数据和假设检验的模型进行评价[2~4],很明显也包括了评价数据挖掘的结果。在数据预处理步骤中,统计学提出了估计噪声参数过程中要用的平滑处理的技术,在一定程度上对补足丢失数据有相当的作用。统计学对检测数据分析、聚类和实验数据参数设计上也有用。但统计学研究的焦点是在于处理小规模数据样本采集和小规模数据集处理的问题上。统计学的工作大多是针对技术和模型的理论方面。于是许多工作是着眼于线性模型、递增的高斯噪声模型、参数估计和严格分类参数模型上。只有在进行相近模式区别时才强调寻优。大多数数据库用户并不具备恰当使用统计学知识的能力。实际上是要求有关数据库工程师或数据库系统的管理员运用关于数据选择的模型、相当多的域知识和数学知识的能力,在现实中是不大可能的。
(二)模式识别
在模式识别工作中,传统上是把注意力集中在符号形式化直接结合实际技术的工作过程中[5,6]。模式识别主要用于分类技术和数据的聚类技术上。模式识别中的分类和含义分析是对数据挖掘概念形成的开端。多数模式识别的算法和方法对降维、变换和设置都有直接的参考意义。在数据挖掘的步骤中,模式识别比统计学更为重要,因为它强调了计算机算法、更加复杂的数据结构和更多的搜索。典型的数据分类是用一定的分类技术把数据从一个向量空间映射到另外一个向量空间。但这种映射并不总是有意义的。比如,形状上“方”与“圆”的差别就很难说比性别上“男”与“女”的差别大。显然,这其中应当注重其语言的含义。
(三)人工智能
人工智能对于数据挖掘来说原来一直是在符号的层次上处理数据,而对于连续变量注意较少[7,8]。在机器学习和基于案例的推理中,分类和聚类算法着重于启发式搜索和非参数模型。对于其结果,并不象模式识别和统计学在数学上的精确和要求严格分析。随着计算机学习理论的发展。人工智能把注意力集中在了表达广义分类的模糊边缘上。机器学习主要是对数据挖掘过程中的数据变量选择处理极有帮助,在通过大量搜索表达式和选择变量上有很大作用。另外,机器学习对于发现数据结构,特别是人工智能中的不确定推理技术和基于贝叶斯模型推理是统计学意义上的分布密度估计的强有力的工具。人工智能技术建立了关于特定领域知识和数据的已有知识的相对容易理解和自然的框架。人工智能的其他技术,包括知识获取技术、知识搜索和知识表达在数据挖掘的数据变换、数据选择、数据预处理等步骤中都有作用。
(四)数据库
数据库及其相关技术显然与数据挖掘有直接的关系。数据库是原始数据的处理、储存和操作的基础。随着平行和分布式数据库的使用,对数据录入和检索有更高的要求。数据挖掘中很重要的一个问题是对数据库中数据的在线分析,主要是如何利用多种方法对数据进行实时处理和分析[6,9]。一般来说,通过相关数据结构的标准化可以克服要求特殊存取数据的困难。在数据挖掘中为了对数据进行特定的统计和计数,则要对各个特征属性进行组合形成新的数据库。其中,对于数据挖掘所得知识支持率的研究是个新领域。为直接从数据库中发现联系规则,已经以产品的形式出现了依靠分析和分类表达式的新方法。此外,为了对数据库问题的求解和优化,利用新出现的数据库定向技术更加易于寻求数据库中隐含的模式。
三、数据挖掘的基本问题
(一)数据挖掘所获取目标知识分类
从目前的资料看来,数据挖掘所希望研究和获取的知识可以分为三类,即:分类问题,联系问题,时间序列问题。
(1)分类问题
分类的问题就是根据一定的领域知识和给定的数组,找出分类的各条规则。例如一个航空邮购滑雪旅行包顾客分类问题:首先把相对较少数目的旅行包邮寄给事先选定的一组顾客样本,然后就可得到有良好反应的大概的规律。这种大概的规律一般以顾客各特征属性的值不同范围来描述的。比如说对该产品邮购有良好反应的顾客一般为年龄在30到40之间,年收入高于40000美元,并驾驶跑车的人。各个有关因素可按一定顺序排列,从而据此挑选出最恰当的顾客群体,也是销售所急需的知识。
(2)联系问题
联系的问题就是得到如下形式的规则:
"A[,1]∧…∧A[,m]
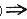 B[,1]∧…∧B[,n]",其中A[,i](i∈[1,…,m])与B[,j](j∈[1,…,n])均为在数据库中相关数据特征属性值的集合。例如在一个大型超市的售货记录数据库处理后可能得到这样的规则:如果顾客在一次购买行为中,买了某种品牌的牛奶,一般他/她会买某种品牌(另一品牌)的面包。
B[,1]∧…∧B[,n]",其中A[,i](i∈[1,…,m])与B[,j](j∈[1,…,n])均为在数据库中相关数据特征属性值的集合。例如在一个大型超市的售货记录数据库处理后可能得到这样的规则:如果顾客在一次购买行为中,买了某种品牌的牛奶,一般他/她会买某种品牌(另一品牌)的面包。(3)时间序列问题
指的是若干种事件发生的顺序规则(或规律)。例如通过对股票市场的数据库进行处理,可得到如下规则:当AT&T公司股票价格在两个连续交易日中上涨,而同一时期内DEC公司股票价格没有下跌。则IBM公司股票在随后的一个交易日内会上涨。
(二)数据挖掘的统一框架
以O为实体集。以D(m)代表某一分类m的特征域,以R(m)代表m分类的特征的所处区间。以M为分类的一个集合。其中M的一些分类m的域处于O中或R(m)中。以o.m代表以分类m作用于记录o上的结果。分类m指以一定的属性的不同组合方式。表达式p(o.l)中,l为M中的分类组成,p为集合M中一些分类m在R(m)中的所限定的表述。例如表述为“年长的”,当纪录t的age大于65时,“长年的(t.age)”为真。这里,age为M中的一个分类。
数据挖掘的最终目的是希望得到相关的规则。我们通常以形式F(o)
 G(o)表达一条规则。其中F为表达式的组合,为这条规则的前件。而G为另外一个表达式。为这条规则的后件。对于所得规则可靠程度的衡量,一般以置信度c来表征。置信度如下定义:实体集O中.如果O中最少以c比例的纪录同时满足F和G,则规则F(o)
G(o)表达一条规则。其中F为表达式的组合,为这条规则的前件。而G为另外一个表达式。为这条规则的后件。对于所得规则可靠程度的衡量,一般以置信度c来表征。置信度如下定义:实体集O中.如果O中最少以c比例的纪录同时满足F和G,则规则F(o) G(o)以置信度c成立,其中0≤c≤1。
G(o)以置信度c成立,其中0≤c≤1。对于给定目标集O,所产生的规则应当满足一定的附加约束。通常,约束以两种形式出现:①合成约束:是出现在规则中的表述和方法的约束。例如,我们可能只关心规则后件中包含特征属性值x的规则或只关心前件中出现特征属性值y的规则。也可能对前件、后件都有约束。②支持率约束:是在O实体集中对某一规则支持的纪录的数目的有关约束。支持率定义为实体集O中满足规则前件、后件的交。支持率与置信度是有区别的。置信度是规则强度的一个度量,而支持率相应的是统计意义上的比率。出于实际应用的目的。我们经常只对支持率达到一定阀值的规则感兴趣,这是要求计算规则支持率约束的另外一个原因。
以下是对数据挖掘问题如何对应各类种数据挖掘问题表述的一般方法。
(1)分类问题
分类器的训练集由实体集O中的有标号的数组构成。标号把记录分到各个组中。相应每一记录的属性,有一方法返回记录的属性值,另有一方法返回记录的标号。分类问题的目标是发现训练集中的每一类数组特征的规则。就是说发现所有后件为“o.标号-方法=k”,k为不同标号值范围。例如,找出规则中后件带有“积极的反应(o.positive-response=yes)”的目标市场分类问题,在滑雪旅行包中可有如下表示:
(30≤u.age≤40)and(u.salary≥40k) |
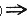 u.positive-response=yes
u.positive-response=yes这里规则的后件的限制是典型的合成约束。另一个合成约束是前件中不能出现带标号的数值。在规则确认前,实体应当满足一定的前件的支持率条件。
(2)联系问题
实体集O是一个售货交易数据库。相应每个交易集中的项,有一个二进制的值,依据是否在集中的项出现而返回真或假。同样应满足置信度和支持率要求。
(3)时间序列问题
时间序列问题中的实体集O包含时间因素(可能有不同的细化程度,例如天,分钟,小时等)。以上文中提到的股市问题为例,以stock(s,t[,1],t[,2])为一方法则有:
(t.stock(AT&T,0,1)=UP)∧(t.stock(AT&T,1,2)=UP) ∧(t.stock(DEC,0,1)≠DOWN)∧(t.stock(DEC,1,2) ≠DOWN) |
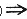 (t.stock(IBM,2,3)=UP)
(t.stock(IBM,2,3)=UP)
时间序列规则可看成一类特殊的联系规则,前件和后件在时间序列上相续出现。在此,支持率的约束作用尤其重要。
(三)数据挖掘的基本步骤
在上述的统一的框架下,以下几个基本操作是解决数据挖掘问题在基本原则上、概念上的步骤。这些步骤中有“串”的概念。串是一个有序数对,一般形式为:“a=(特征属性m,值v)”。其中,a是一个有序数对,是一个“串”。串中的值则可以是表达式,或者当特征属性返回的值可有序排列则可以为一个区间。如果v为一表达式(或如果v为一区间),且t.m∈a时,对于特征属性t的表述t.m=v的简单表示为串(m,v),其中,a为t的取值区间。
(1)新串←产生(源集,数据库)
把串的集合表示为第一个参数(源集),并以此建立一个单作为遍历数据库的准则。串集合从源集中扩展,然后依据表得到(特征属性m,值v)对。新串的实际值在一次遍历中依赖于参数数值。
(2)检验(新串)
检验是通过简单迭加上一步骤产生的新率中每一记录的支持数字而得到支持率比较完成的。在此情形下,因为需要提高效率的原因要对串进行一定的合并。例如,把处于某个时间段上且有相同身份证号的顾客在超市数据库中的记录的购买合并,进而发现其中的联系规则。那么定义支持率集为买某种商品的顾客数而不是买某种商品的总价值。
(3)合并串←合并(新串)
可通过划分区间和相近的属性域或利用分类学信息。以此方法可把多个串合并成一个“合并的串”。例如:某类人年龄为20,22,24,27,28,30,则可用新串20~30表示。
(4)源集←过滤(合并串)
即从组合串中筛选出新的源集。对于目标集来说,新的源集有“更好”特性能达到目标最终要求的属性。
(5)目标←选择(源集)
选择的串和其检验值储存于目标集中,也可留在源集中。
初始的源集只有空串,后4个步骤循环进行直到源集中无串为止。
(6)合并操作
在合并操作中,对于数据挖掘三类不同的规则,分别有如下表述:
①分类规则。目前来说,一般采用的是决策树分类法。串的目标集包括所有的相应分类树上的从根到叶的串。在源集中给走一个串s,通过给它加上所有可能数对(属性,值),可产生此串所有的扩展集。属性为连续时可扩展合并,ID3和CART方法是用二进制数实现此目标。过滤器操作中,以熵计算每一属性的增加,而且只有包含信息量系数最大值的属性才被保留和并包括在下次循环的源集中。可对其设定一定的阀值。
②联系规则。为辨别规则F(o)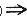 G(o)是否满足最低置信度,首先把在实体集O中,满足支持率为F(o)的纪录o的总数n算出来,并计算对支持率为G(o)和F(o)的纪录总数m,而后以m除以n,如其比率大于置信度c,则规则满足置信度因素c,否则不满足。串的目标集包括所有支持率达到一定阀值(最小支持)的串,而且也是选择操作中所用的标准。这些串形成了可能规则的基础(换句话说,它们可能形成规则的前件)。在产生操作中,新串通过在源集中没出现的项的源集串扩展而产生。检验操作是计算在数据库中某一个串出现的总数。在过滤操作中,未满足最小支持率的串淘汰。注意,选择操作挑出的串仍然在源集中保留一下,以做进一步扩展。
G(o)是否满足最低置信度,首先把在实体集O中,满足支持率为F(o)的纪录o的总数n算出来,并计算对支持率为G(o)和F(o)的纪录总数m,而后以m除以n,如其比率大于置信度c,则规则满足置信度因素c,否则不满足。串的目标集包括所有支持率达到一定阀值(最小支持)的串,而且也是选择操作中所用的标准。这些串形成了可能规则的基础(换句话说,它们可能形成规则的前件)。在产生操作中,新串通过在源集中没出现的项的源集串扩展而产生。检验操作是计算在数据库中某一个串出现的总数。在过滤操作中,未满足最小支持率的串淘汰。注意,选择操作挑出的串仍然在源集中保留一下,以做进一步扩展。
③时间序列规则。其处理与联系规则的处理方法相同。前件和后件的关系可由包括压缩存储和特殊目标索引等许多方法实现。
(四)数据挖掘实现中需注意的问题
使用基本操作时,应注意以下两个问题,以提高对数据挖掘算法的效率[1]。
(1)淘汰率
以α代表目标集中的串与所有串总数的比值。淘汰率则为1-α、淘汰率太高说明做了许多不必要的工作。分类准确率相差不大而淘汰率较低的算法是较优的。
(2)与CPU耗费相平衡的输入\输出耗费
减少淘汰率是保守的做法。在大型数据库处理中是不适应的。可采用较少的循环次数而进行大量的计算或每次计算量减少而增加总的计算次数。目的都是为了减少内存消耗。
四、结束语
数据挖掘技术是一个发展十分快的领域,最近,各类杂志发表了许多有关数据挖掘技术的新研究报告、论文,提出了一些新的方法和模型。因此,本文作为对数据挖掘技术的总体概述,显得十分必要。
本文总结了数据挖掘的定义、目标、相关领域及其一般方法,基于数据挖掘技术数据资料之丰富,现在在论文中提到的相关领域已有了一些数据挖掘技术的模型,限于篇幅不再一一列举。
作为一个新兴的研究领域,数据挖掘仍然有许多问题需要进行深入研究。例如:从同一个数据库的不同层次上提取相应的规则;确定一种方便、实用、统一的语言表达数据挖掘的结果;应用数据挖掘技术,基于动态数据库、面向对象技术、多媒体数据库及从国际互连网上抽取新的、有用的规则。当然,数据挖掘技术同样应该包括对于所抽取规则的准确性及数据的安全性、私密性的保护等领域的研究。
参考文献:
1Mark B.Data mining-here we go again[J].IEEE Transactions,Expert,1996,11(5):18-19.
2Rasmussen J.The role of hierarchical knowledge representation in decision making and systems management [J].IEEE Transactions,Systems,Man,and Cybernetics,1985,15(2):234-243.
3Lewis C M,Hammer J M.Significance testing of rules in rule-based models of human problem solving [J].IEEE Transactions,Systems,Man,and Cybernetics,1986,16(1):154-158.
4Waltz E L,Buede D M.Data fusion and decision support for command and contro [J].IEEE Transactions,Systems,Man,and Cybernetics,1986,16(6):865-879.
5Eorsythe D E,Buchanem B G.Knowledge acquisition for expert systems:some piffle and suggestions [J].IEEE Transactions,Systems,Man,and Cybernetics,1989,19(3):435-442.
6Ross J,Quinlan.Knowledge acquisition from structured data[J].IEEE Transactions,Expert,1991,6(6):32-37.
7Lu H,Setiono R,Liu H.Effective data mining using neural networks [J].IEEE Transactions Knowledge and Data Engineering,1996,8(6):957-961.
8Agraual R,Shafer J C.Parallel mining of association rules[J].IEEE Transactions Knowledge and Data Engineering,1996,8(6):962-970.
9Othurusamy R,Means L G,Godder K,et al.,Extracting Knowledgefrom diagnostic database [J].IEEE Transactions,Expert,1993,8(6):27-38.