马薇/袁铭
【内容提要】
本文提出使用核估计的方法构造平滑转移模型(STR)的非参数模拟最大似然估计(NPSML),给出了NPSML估计量的构造方法、渐近性质以及相应的核函数和窗宽的选择准则,并利用滑动窗宽算法对估计量的构造过程进行了改进。通过Monte Carlo实验证明,该方法是可靠的,并且当误差项存在序列相关时,此种估计量是稳健的。
【关 键 词】平滑转移模型/非参数模拟最大似然估计/滑动窗宽算法
引言
经济过程在运行中由于其复杂性,大多数表现出非线性特征。特别地,许多经济过程都表现出以机制转换行为为特点的非线性特征,即经济运行过程具有一个或者多个突变点。目前,世界性的金融危机就充分体现出这样的特征。针对这些现象,人们开始考虑将传统的线性模型拓展到非线性建模领域,并逐步提出了三种典型的机制转换模型,即马尔可夫机制转换模型、门限回归模型和平滑转移模型。三个模型的共同点都是将数据生成过程中的非线性信息转换成可以控制的模型机制,主要区别在于处理机制转换结构的方法有所不同。作为本文研究的重点,设定平滑转移回归模型(STR)允许两个或者多个极端机制之间的变化是平滑的。
STA模型用于研究经济过程的变化规律具有以下三个优点:(1)由于现实中的经济变量发生机制转移行为时需要时间,因此该模型适合模拟经济现实和突发性政策;(2)能够处理经济过程中的结构性突变;(3)能够捕捉经济过程中的非对称现象。这些优点使得平滑转移模型成为近年来国内外计量经济学前沿领域追踪的热点问题,广泛应用于经济周期研究、购买力平价假设、失业率与产出等宏观经济现象的建模和预测,并逐步拓展到向量自回归和面板数据分析领域,使其能够处理系统模型以及经济过程中广泛存在的异质性问题。
在以往的平滑转移模型的研究中,Ters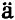
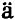
基于前面的分析,本文做了以下工作:首先对STR模型的基本形式、拓展形式以及参数估计进行介绍,指出现有NLS估计存在的局限性;然后提出STR模型的NPSML估计量,给出了估计量的构造方法、渐近性质以及相应的核函数和窗宽的选择准则,并通过Monte Carlo实验验证其可靠性;最后,利用基于估计点的滑动窗宽算法对NPSML估计量进行改进,并验证其改进效果。
一、平滑转移模型及其参数估计
1.STR模型的基本形式、拓展形式与常用估计方法
研究非线性模型的关键问题是寻找恰当的替代模型,将复杂的模型转移到已经成熟的非线性模型进而得到估计与应用。
平滑转移模型(STR)的基本形式为:

不同的模型,适合不同的经济领域。为了扩大STR模型的应用领域,该模型具有多种拓展形式。主要包括:多机制的STR模型(MRSTR)、时变STR模型(TVSTR)、向量STR模型(Vector-STR)以及面板STR模型(PSTR)。其中,MRSTR模型可以用来捕捉经济过程中更细微的非线性结构,如果令某个转移机制中的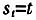
此外,Thomakos(2003)将非参数转移函数引入STR模型,并通过引入加权函数赋予此类模型很大的灵活性,使得机制平滑转移可以在模型的线性部分与半参数部分之间进行。刘金全等(2007)以及Amado和Ters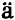
STR模型的参数估计可以使用NLS,也可以使用基于广义矩估计(GMM)方法。其中,NLS估计需要为迭代过程给出恰当的初值,一般的方法是利用网格搜索法,并且需要进行尺度变换,即使用转移变量的标准差对转移速度参数进行标准化;GMM估计需要选择恰当的工具变量,Areasa和McAleer(2008)指出工具变量集合W必须与转移函数G(γ,c,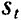
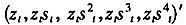
本文在引言部分已经指出STR模型参数估计存在两个缺陷,其根本原因是:①对于初始值问题,非线性最优化算法容易收敛于局部最优解,也就是说在给定的迭代次数内,算法很难在初始值的邻域内做大幅度地搜索;②对于转移速度参数估计问题,当γ值很大时,由于γ的变化程度对转移函数的形态影响很小,为了对其做出精确估计,人们必须在转移门限的邻域内拥有足够多的观测点,而现实条件往往不具备。
Monte Carlo实验表明,当样本容量较小或者误差项非独立同分布时,NLS和GMM估计量都存在严重偏差,并且γ存在明显的高估现象,而门限参数c的估计偏差则与具体的门限参数值有关,当c小于样本均值时,c表现为一定程度的低估,反之则表现为高估。因此,本文考虑在Fermanian和Salanie(2004)提出的非参数最大似然估计的基础上,对STR模型参数估计进行改进。
2.STR模型的非参数模拟似然估计(NPSML)
STR模型的非参数模拟似然估计(NPSML)的基本思想是对于任意参数值,利用已有观测点信息产生模拟样本,并通过核估计方法拟合出原始样本的条件密度函数,并在此基础上构造似然函数进行估计。


NPSML估计量的优点体现在:①有效地解决了非线性模型参数估计的维数灾难问题,例如STR模型的转移函数为一阶logistic函数时,NLS或者MLE是可行的,但当模型具有更为复杂的转移变量形式或者更多转移机制时,对这些非线性参数进行网格搜索是极为困难的,而模拟似然估计量的维数只取决于被解释变量;②由于模拟序列是在独立同分布残差序列基础上构造的,故估计量的分布密度不受样本数据相依结构的影响,即无论过程是否平稳,是否独立同分布,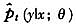
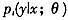


二、NPSML估计量可靠性研究
1.实验设计与估计方法说明
本节将通过Monte Carlo实验研究NPSML估计量的可靠性,重点考察模拟样本数量和窗宽对估计效果的影响。实验使用的数据生成过程(T=1000)为:

评估标准为在不同情况下生成200个随机样本,使用NPSML方法估计之,计算这些样本参数估计值的均值和90%置信区间并与NLS估计量进行比较。
2.模拟结果与NPSML估计量可靠性分析
表1给出了在不同模拟样本数量和窗宽下NPSML和NLS的估计结果,从中可以看出,在各种情况下NPSML都可以对两个机制的回归系数、转移速度参数和转移门限做出可靠估计,估计量的整体偏差与NLS相近,但有效性不如NLS估计量,即NPSML估计量存在边界效应问题。这主要由于核估计是局部加权平均,其在边界点的偏差将大于内点处的偏差,并且边界点收敛速度较慢。当窗宽为非参考窗宽时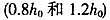
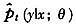
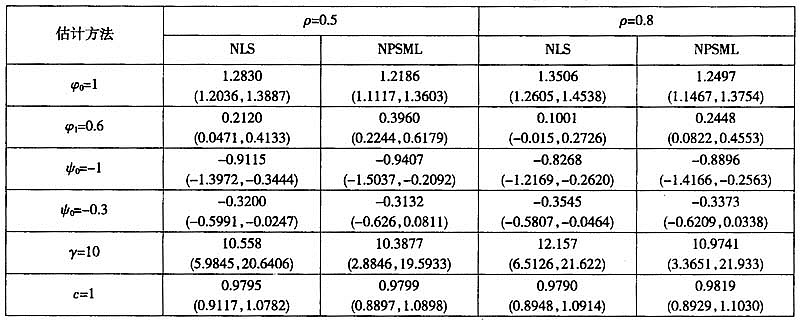
表2(见下页)给出了误差项存在序列相关时的估计结果。此时,NLS估计和NPSML估计都出现偏差(转移速度参数表现为低估,两个机制中的自回归系数表现为高估),并且随着相关程度增强,这种偏差也随之加大。尽管如此,NPSML(N=1000,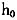
表1独立同分布误差项下NPSML和NLS估计结果
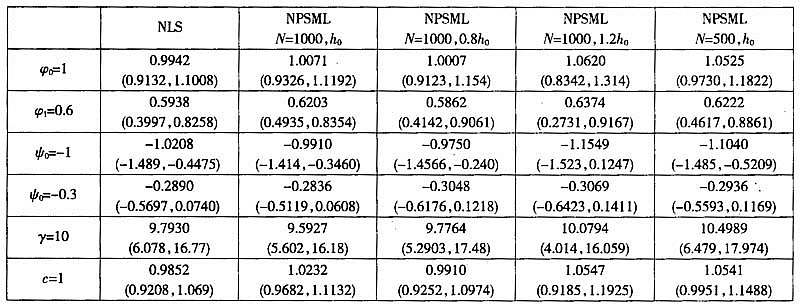
表2误差项存在序列相关时NPSML和NLS估计结果
三、基于滑动窗宽的NPSML估计量的改进
1.基于估计点的滑动窗宽优化算法
在前面的研究中,通过蒙特卡洛实验发现,按照最优窗宽表达式构造的NPSML估计量结果并非最优,许多情况下不能令人满意。但是在模拟实验中发现,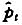
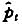


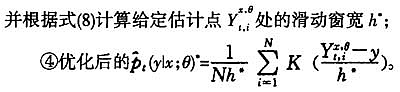
2.改进效果验证
仍然使用前面的数据生成过程和相关参数的设定,验证滑动窗宽NPSML估计量的可靠性。实验使用的估计方法为:NLS、固定窗宽NPSML和滑动窗宽NPSML。为了比较三者在有限样本和误差项非独立同分布情况下的性质,将样本容量设定为T=200,误差项存在序列相关,其中ρ=0.5。在滑动窗宽算法的具体实现过程中,由于样本分布边缘区域观测点的稀疏性,导致窗宽值急剧增大。因此,对于过大的窗宽值,本文取其上限为2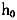
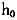
结果表明:①在误差项独立同分布情况下,基于滑动窗宽的NPSML估计量,在总体偏差方面接近NLS而优于固定窗宽的NPSML估计量,甚至在估计转移速度和转移门限时亦优于NLS,而在误差项存在序列相关时,滑动窗宽NPSML的优势表现得更加明显,能够在很大程度上修正序列相关性对参数估计的影响;②滑动窗宽NPSML尽管不如NLS估计有效,但在相当大的程度上降低了非参数核估计中的边界效应,并且基本不受误差项存在序列相关的影响,其估计不但可靠,而且稳健。
图1为实际的滑动窗宽变化规律,从中可以看出:在绝大多数情况下,滑动窗宽值比固定窗宽值要大(固定窗宽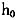
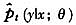
表3NLS、固定窗宽NPSML和滑动窗宽NPSML的估计结果
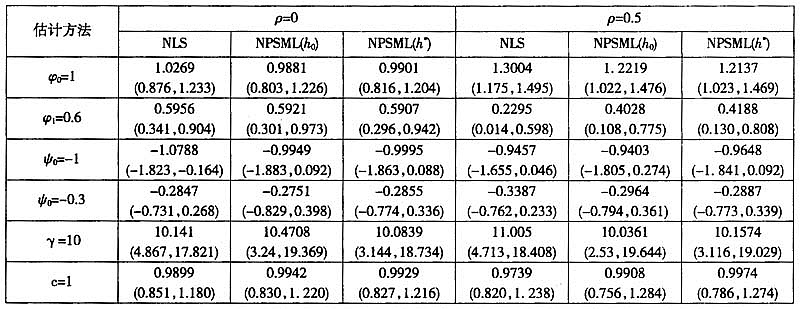
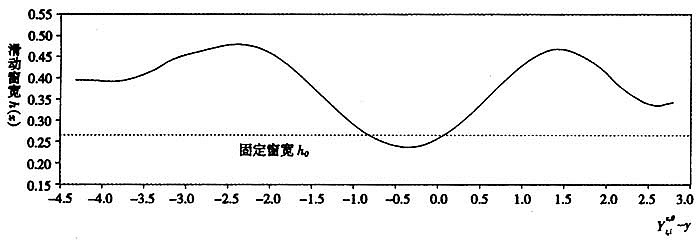
图1实际的滑动窗宽变化规律
四、结论
本文在对STR模型的形式、估计方法和局限性介绍的基础上,引入非参数模拟最大似然估计的思想,提出了STR模型的NPSML估计量,给出了估计量的构造方法、渐近性质以及相应的核函数和窗宽的选择准则,利用基于估计点的滑动窗宽算法对NPSML估计量进行改进,并通过Monte Carlo实验验证其可靠性,得到如下结论:
第一,误差项独立同分布时,在适当条件下(N=1000,使用固定参考窗宽)构造的NPSML估计量能够对模型系数做出可靠估计,整体偏差与NLS相近。由于核估计存在边界效应,其有效性不如NLS。
第二,误差项存在序列相关时,NPSML整体上比NLS估计量表现出更为优良的性质,特别是对转移速度和转移门限参数的估计,NPSML远优于NLS,这主要是因为用于构造NPSML估计量的模拟样本是在独立同分布序列基础上产生的。同时,序列相关性强弱对参数估计的影响,NPSML也比NLS要小。
第三,当使用非参考窗宽或者使用较小的模拟样本数量时,NPSML估计的偏差加大,有效性也不如使用参考窗宽的情形,并且使用较大的参考窗宽时,这一情况更加严重。
第四,使用基于估计点的滑动窗宽算法进行改进后,无论误差项是否独立同分布,NPSML估计量的可靠性都得到明显改善,并且根据滑动窗宽的变化规律可知,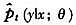
总之,本文提出的NPSML估计量为解决STR模型参数估计局限提供了一种新的、易于实现的方法,该方法的思路也可以广泛用于其他非线性模型。进一步的研究工作将是使NPSML估计量应用于多机制STR以及向量STR模型中,并更深入地研究其可行性和估计的可靠性。
【参考文献】
[1]刘金全、李庆华、郑挺国:《具有平滑迁移的ARFIMA模型及其应用》[J],《中国管理科学》2007年第6期。
[2]Amado, C. and Ters
[3]Areasa, McAleer. Moment-based Estimation of Smooth Transition Regression Models with Endogenous Variables[R], Working Paper. 2008, 36.
[4]Fermanian, J.-D. and B. Salanié. A Nonparametric Simulated Maximum Likelihood Estimation Method[J], Econometric Theory, 2004,20:701~734.
[5]P
[6]Rothman, van Dijk and Franses. A Multivariate STAR Analysis of the Relationship between Money and Output[J], Macroeconomic Dynamics, 2001,5:506~532.
[7]Ter
[8]Ters
[9]Dimitrios D. Thomakos. A Semiparametric Smooth Transition ARX Model for Nonlinear Time Series[R], Working Paper. 2003.
[10]Timo Terasvirta, Dick van Dijk. Panel Smooth Transition Regression Models[J], SSEPEFI Working Paper Series in Economics and Finance. No. 6041.
[11]Wooldridge, J.M. Estimation and Inference for Dependent Processes[C], in R.F. Engle and D.L. McFadden(eds.), Handbook of Econometrics[A], 2004.Vol. IV, Amsterdam: Elsevier Science, 2639~2738.^
【原文出处】《数量经济技术经济研究》(京)2010年1期第151~160页
【作者简介】马薇,袁铭,天津财经大学。