内容提要:基于城镇居民人均可支配收入分组数据,运用非参数Kernel密度估计方法和Monte Carlo模拟技术,估计了1987-2008城镇居民收入分布及其演进特征。结果发现:(1)从全国城镇居民收入分布演进特征看,城镇居民收入不平等呈扩大趋势,基尼系数由0.17上升到0.33,增长近一倍,但没有观察到普遍和持久的两极分化现象(双峰分布);(2)在12个代表性省(区、直辖市)中,以经济发展模式(经济增长—收入分配)分类,广东属于平等发达型,湖南、四川、宁夏和广西属于不平等落后型,急需调整和转变增长方式;(3)从区域经济发展特征看,东部地区和东北地区收入增长较快,但收入不平等现象十分严重,中部地区和西部地区收入增长相对较慢,不平等现象相对轻微。
关键词:收入分布/分组数据/非参数Kernel密度估计方法/Monte Carlo模拟技术
作者简介:陈立中(1973-),男,湖北麻城人,经济学博士,暨南大学经济学院讲师(广州510632),北京大学中国经济研究中心博士后(北京100871)。
一、问题的提出与文献回顾
改革开放30年来,中国经济总量水平和平均水平保持持续高速增长,经济总量世界排名由1978年第146位跃升到2008年的第4位,人均GDP由1978年的381元上升到2008年的22698元(名义值),年均增长率超过9%。中国经济改革的主要策略之一是先试验后推广,由点带面逐步推进,通过增量带动存量。实践证明,这样的改革和发展模式符合中国特色,成功地带动了整体经济的快速增长。不过,中国经济发展的不平衡性和不平等性越来越引起了人们的强烈关注,樊纲(2007)研究认为中国表示收入不平等的基尼系数已经超过国际警戒线,王小鲁等(2009)甚至认为中国经济已落入“不平等陷阱”。的确,学界和政府部门已经认识到,收入不平等是阻碍和制约经济社会持续健康发展的深层问题。诊断先于治疗,要缩小收入不平等,改善收入分布状况,首先需要知道居民收入分布状态、特征及其成因。从研究过程看,要统计描述收入分布及其演进,需要长时间系列的以家户为单位的微观调查大样本数据库,这对于一般研究者而言是非常困难的,甚至不可能。因此,采用中国统计年鉴发布的收入分组数据①(grouped data)便成为许多研究者的现实选择。要想用这些信息相对有限的分组数据,方便准确地估计收入分布,在很大程度上依赖于所采用的统计技术。基于此,本文试图运用城镇居民收入分组数据、非参数Kernel密度估计方法和Monte Carlo模拟技术,估计城镇居民收入分布及其演进特征,为人们认识和缓解收入不平等问题提供依据。
在国外文献中,一些学者试图估计全球收入分布及其演进特征,如Quah(1993)以国家为单位的分组数据和参数估计方法,实证发现,世界收入分布具有明显的从单峰向双峰演进的特征,即两极分化倾向。Bourguignon(2002)收集了1820-1992年世界33个经济体的相关收入数据,运用随机参数方程研究发现,从19世纪初到19世纪40年代,全球收入分布在持续恶化,之后趋向稳定。Sala-I-Martin(2006)收集了138个国家的收入分组数据,采用非参数Kernel密度方法,实证估计了1970-2000年各样本国和世界收入分布及其演进特征,结果发现,世界收入不平等和贫困在20世纪80年代及90年代都呈下降之势,不过,不同国家或地区的演进特征并不一致,差异比较明显。
在国内文献中,何江等(2006)用1985年、1995年和2004年31个省(区、市)的人均GDP数据和非参数Kernel密度方法,实证模拟出全国相对人均GDP的分布曲线。王争等(2006)和许冰(2006)采用相似方法和数据资料,估计了全国收入分布及其特征。徐现祥等(2008)采用《中国国内生产总值核算历史资料》和非参数Kernel密度方法,实证估计了各省(区、直辖市)及全国的收入分布,并进行了分解。不过,这些文献所采用的方法在统计上的可靠性还在讨论之中。
从测算和模拟技术角度看,用分组数据来估计收入分布主要有参数和非参数两种估计方法。万广华(2006)认为,参数估计方法的关键在于如何选择恰当的参数模型,对于使用分组数据而言,参数估计方法的另一个弱点是,高收入分组数据中所含误差通常比低收入分组数据大,遗憾的是,该方法不能将二者分离开来。参数估计方法将一个先验的模型强加于数据之上,缺乏灵活性和准确性。相对而言,非参数Kernel密度估计方法事先不需要设定函数形式,并且还可以提高估计质量,特别是对非单峰密度函数估计。
基于此,本文试图运用城镇居民人均可支配收入分组数据和非参数Kernel密度估计方法,通过参数比较与选择,以及Monte Carlo模拟技术,实证估计中国城镇居民收入分布状态及其演进特征。文章其余部分安排如下,第二部分介绍数据来源和估计方法,第三部分是实证结果及其解析,最后是文章的简要结论和进一步研究展望。
二、数据来源与估计方法
(一)数据来源及处理
国家统计局、各省(区、直辖市)统计局每年定期发布城镇居民七分组(或五分组)人均可支配收入数据,即最低收入户(10%)、低收入户(10%)、中下收入户(20%)、中等收入户(20%)、中上收入户(20%)、高收入户(10%)和最高收入户(10%)的人均可支配收入,这些数据分别来自1988-2009年各省(区、直辖市)统计年鉴和《中国统计年鉴》。各省(区、直辖市)城镇居民消费价格指数(CPI)来自《新中国五十五年统计资料汇编》。由于河北和甘肃大部分年份数据存在缺失,我们只计算了29个省(区、直辖市)的相关指标。
为适合模型估计需要,我们首先将城镇居民七分组数据合并为五等份分组数据(quintile means),即低收入户(20%)、中下收入户(20%)、中等收入户(20%)、中上收入户(20%)和高收入户(20%),这样处理对估计结果不会形成统计上的影响(Sala-I-Martin,2006;Minoiu,et al., 2007)。接着,我们用各省(区、直辖市)城镇居民消费价格指数(CPI)将各分组的可支配收入平减为1987年价格水平。为便于分析和比较城镇居民收入分布的密度曲线,我们还将可支配收入水平转换为对数形式。
(二)非参数Kernel密度估计方法
假设有一随机变量X的密度函数为f(x),则在点x处的核密度函数可设定为:
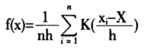
这里,n为研究对象观测值个数,K(·)是核函数,它是一种加权函数(the weighting function)或平滑转换函数,h为带宽(the bandwidth of the Kernel),即平滑转换参数。在核密度函数f(x)估计过程中,核函数和带宽选择是关键。
1.核函数选择
实际应用中,Kernel核函数K(·)的形式主要有:高斯(Gaussian)核、Epanechnikov核、三角核(Triang ular)和四角核(Quartic)等四种,选择的依据在于分组数据的密集程度。经验研究显示,所采用的分组数据越少,选择高斯核函数的可能性越大(Sala-I-Martin,2006),基于此,我们选用高斯核函数进行估计②。
2.带宽选择
Silverman(1986)研究发现,当数据特征和核函数给定时,如果带宽选择太小,估计结果可能比较粗糙,还会产生一些数据噪声,以及一些反事实的伪造信息;如果带宽选择太大,估计结果可能过于平滑,容易掩盖数据结构,遗失一些重要结构性信息。实际估计中,使用的样本越多,越宜于选择较小的带宽,但不可太小,一般应满足如下要求:


三、城镇居民收入分布及其演进特征:1987-2008
基于数据来源和研究需要,我们使用高斯核函数,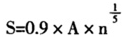 作为带宽,以及Monte Carlo模拟法,分别估计29个省(区、市)和地区的收入分布曲线③。下面分别探讨典型省(区、市)、全国、东部、中部、西部及东北地区的收入分布曲线及其特征。
作为带宽,以及Monte Carlo模拟法,分别估计29个省(区、市)和地区的收入分布曲线③。下面分别探讨典型省(区、市)、全国、东部、中部、西部及东北地区的收入分布曲线及其特征。
(一)典型省(区、市)城镇居民收入分布演进特征
基于估计结果,我们依据地域和经济发展特征,选择性报告了1987-2008年12个代表性省(区、市)城镇居民收入分布及其演进特征,收入分布密度曲线见图1。
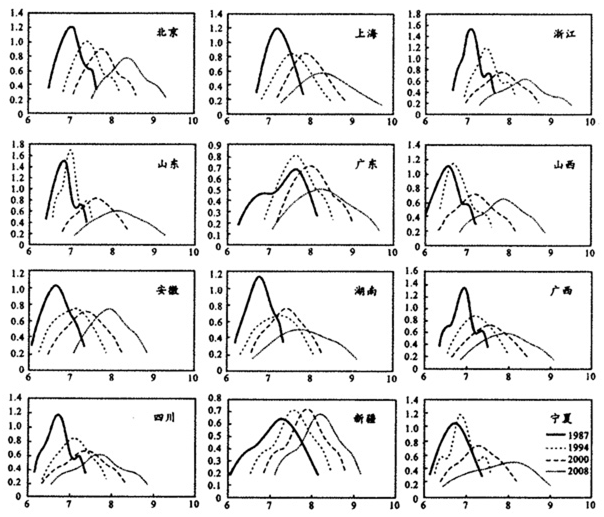
图11987-2008年典型省区城镇居民收入分布演进特征
从收入水平增长速度看,北京城镇居民收入增长最快,由1987年的1182元上升到2008年6421元(1987年价格,下同),增长4.48倍;广东其次;宁夏最慢。从收入分布形态看,宁夏收入不平等程度恶化最为严重,基尼系数由1987年的0.1754上升到2008年的0.3264;新疆基尼系数始终保持在0.27左右。浙江1987年和1994年收入分布曲线表现为双峰分布,具有明显的两极分化特征,到了2000年和2008年,双峰逐渐演进为单峰,两极分化现象消失。广西和四川1987年呈多峰分布,之后向单峰分布演进。
我们从经济增长(收入增长率)和收入不平等(基尼系数增长率)两个维度将12个代表性城市分为四种经济发展模式(图2):平等发达型、平等落后型、不平等发达型和不平等落后型④。分类发现:(1)广东属于相对平等发达型经济体,需要注意的是,统计中没有将大量流动人口,特别是农民工包含进来;(2)新疆和安徽属于平等落后型;(3)吉林、山东、上海和浙江属于不平等发达型;(4)湖南、宁夏、四川和广西属于不平等落后型。
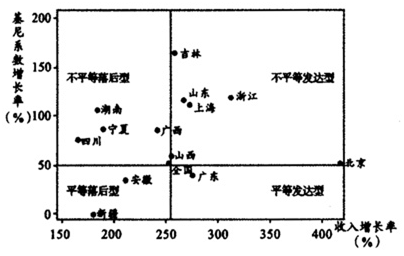
图2代表性省(区、市)和全国经济发展模式分类与比较
(二)全国城镇居民收入分布演进特征
图3是全国城镇居民收入分布密度曲线,我们看到,1987-2008年城镇居民人均收入水平由916元上升到3728元,基尼系数由0.1660上升到0.3251,增长近一倍。与已有研究不同,在我们的估计中,城镇居民收入分布并没有出现双峰分布,即两极分化特征。
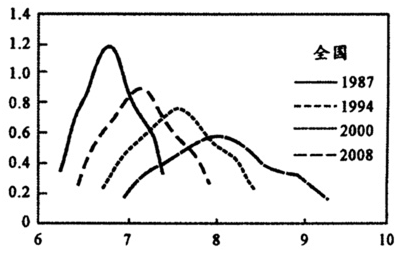
图31987-2008年全国城镇居民收入分布演进特征

图41987-2008年东部、中部、西部和东北地区城镇居民收入分布演进特征
(三)东、中、西部及东北地区⑤城镇居民收入分布演进特征
从图4我们看到:1987-2008年,东部地区城镇居民收入增长最快,由1072元上升到3701元,高于全国平均增长水平;基尼系数由0.1442上升到0.3062,增长112.34%。其中,1987年和1994年收入密度曲线表现出双峰分布特征,具有两极分化趋势,2000-2008年,两极分化现象消失,密度曲线更加平滑,收入不平等进一步加剧。
从密度曲线形状看,中部地区和西部地区非常相似。西部地区受恶劣的气候和地理条件限制,经济发展水平明显落后,2008年城镇居民收入水平(2547元)仅相当于全国水平的75%。相对而言,中部地区经济发展更慢,1987年中部和东部城镇居民收入水平相当,前者为1049元,后者为1072元,但是20年后(2008年),中部地区城镇居民收入水平只有东部地区的74%,“中部塌陷”说有较强的事实支撑。
与其他地区相比,东北地区表现特别,1987年收入分布呈三峰分布,有多极分化特征,之后密度曲线十分扁平,表明存在严重的收入不平等,基尼系数由1987年的0.2070上升到2008年的0.3784,高于全国平均水平(0.3227)。东北是我国传统老工业基地,有着雄厚的经济基础,改革开放后,随着国有大中型企业改革的大幅度推进,经济发展水平出现明显下滑,这可能成为一种有力的解释。相对而言,在改革起点上东北地区与其他地区明显不同(东北地区国有经济比例更高),这为经济转型中关于起点与路径选择研究提供了案例。
四、结论及含义
本文中,我们运用城镇居民收入分组数据、非参数Kernel密度方法和Monte Carlo模拟技术,估计了1987-2008年城镇居民收入分布及其演进特征,得出以下结论及含义:
(1)从全国城镇居民收入分布演进特征看,1987-2008年城镇居民收入不平等呈扩大趋势,基尼系数由0.17上升到0.32,增长近一倍,但是与已有的研究不同,我们没有观察到普遍和持久的两极分化现象(双峰分布)。这意味着,经济发展过程中“不平等陷阱”并未出现,政策选择中,可以完善市场机制,通过初次收入分配手段来改善收入不平等。
(2)在12个代表性省(区、直辖市)中,以经济发展模式(经济增长—收入分配)分类,广东属于平等发达型,是一种比较理想的发展模式,当然,这是在没有将农民工纳入研究范围下的发现。接下来的研究可以将农民工考虑将来,并进一步思考这种发展模式的内在动因和传导机制;湖南、四川、宁夏和广西属于不平等落后型,急需调整和转变增长方式,并进一步探寻具体转变的路径与机制。
(3)从区域发展特征看:东部地区和东北地区收入增长较快,但是收入不平等现象十分严重;中部地区和西部地区收入增长相对较慢,不平等现象相对轻微,在区域振兴规划制定中,应该充分考虑这些因素。我们还发现,东北地区经济发展模式为经济转型中的起点与路径选择研究提供了素材。
(4)在采用分组数据和非参数Kernel密度估计方法估计密度曲线时,运用Monte Carlo模拟技术可以提高估计质量。
作者特别感谢匿名审稿人的意见与建议,当然,文责自负。
注释:
①这里分组数据是一种按照某种顺序排列的统计数据,它是通过计算每一等份组的平均值得到的。
②实际上,我们用上述四种核函数分别进行了估计,比较发现,高斯核函数估计结果相对较优。
③相关估计程序,有兴趣的读者可直接向作者索取。
④为了便于比较,我们以全国收入增长率——基尼系数增长率作为基准点。
⑤根据中国统计年鉴2007年的地区划分标准,东部包括北京、天津、河北、上海、江苏、浙江、福建、山东、广东和海南10省市,中部包括山西、安徽、江西、河南、湖北和湖南6省,西部包括内蒙古、陕西、甘肃、宁夏、青海、新疆、重庆、四川、云南、贵州、西藏和广西12省区,东北包括黑龙江、吉林和辽宁3省。
参考文献:
[1]樊纲.2007.2007年中国社会蓝皮书[M].北京:社会科学文献出版社:102-103.
[2]何江,张馨之.2006.中国省区收入分布演进的空间—时间分析[J].南方经济(12):12-19.
[3]万广华.2006.经济发展与收入不平等:方法与证据[M].上海:上海三联书店:56-69.
[4]王争,钱彦敏.2006.中国省际收敛与收入分布的“极化”特征,1978-2004:趋势及成因[R].经济发展论坛工作论文,www.fed.org.cn.
[5]王小鲁,樊纲.2009.中国收入差距的走势和影响因素分析[J].经济研究(10):24-36.
[6]许冰.2006.一种可选择的新方法:加权人均GDP[J].数量经济与技术经济研究(7):42-51.
[7]徐现祥,王海港.2008.我国初次分配中的两极分化及成因[J].经济研究(2):38-45.
[8]BOURGUIGNON F, MORRISON C. 2002. Inequality among world citizens: 1820-1992[J]. American Economic Review, 92:727-744.
[9]MINOIU C, REDDY S. 2007. Kernel density estimation based on grouped data: The case of poverty assessment[R]. Columbia University Institute for Social and Economic Research and Policy Working Paper, No.2007-02.
[10]QUAHD. 1993. Galton's fallacy and tests of the Convergence Hypothesis[J]. Scandinavian Journal of Economics, 95:427-443.
[11]SALA-I-MARTIN X. 2006. The world distribution of income: Falling poverty and eovergence, period[J]. Quarterly Journal of Economics, 21:351-397.
[12]SILVERMAN B W. 1986. Density estimation for statistics and data analysis[M]. London: Chapman and Hall.
来源:《财贸研究》(蚌埠)2010年6期第8~13页