内容提要:方差估计是抽样调查的重要组成部分,重抽样方法是常用的方差估计方法。重权数方法与重抽样方法类似,也是利用计算机的优势通过重复获得大量不同的子样本的重权数估计目标参数的估计量和方差估计量,是一种稳健、通用、有效的方差估计方法。本文主要介绍重权数在复杂抽样调查的方差计算中的理论和应用。
关键词:方差估计 重权数 平衡半样本方法 刀切法 自助法
作者简介:吕萍(1981-)女,山东泰安人,北京大学中国社会科学调查中心博士后,研究方向为统计调查和数据分析。
一、引言
当今世界,抽样调查受到社会各界越来越多的关注,方差估计量是抽样调查中的重要组成部分,是评价调查数据质量的重要指标。方差估计量[1,2]的计算方法包含公式法、泰勒级数展开法和重抽样方法,随着计算机的发展,重抽样方法以其稳健性和简便性成为方差估计量的主要方法,重抽样方法包含随机组法(Random Group)、平衡半样本方法(Balanced Repeated Replication)、刀切法(Jackknife)和自助法(Bootstrap),其基本原理是首先依据一套事先设定好的方案,从原始数据集中创建B个数据集(通常被称为伪复制数据集pseudo-replicatesdata)。令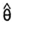 是参数θ的基于原始数据集的估计量,
是参数θ的基于原始数据集的估计量, (j=1,…,B)为第j个复制数据集得到的估计量,重抽样方法利用
(j=1,…,B)为第j个复制数据集得到的估计量,重抽样方法利用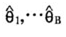 之间的变异估计V(
之间的变异估计V(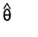 ),即重抽样方法是利用计算机的优势通过从实际调查数据中按照一定的规则重复抽取大量不同的子样本来估计目标参数的估计量和方差估计量。其实质是每次重复抽样后得到的重复权数是不同的,由此得到的估计量也是不同的,这个重复的权数称为重权数(replicate weight),本文主要介绍如何利用重权数得到不同抽样设计下的目标参数的估计量和方差估计量。
),即重抽样方法是利用计算机的优势通过从实际调查数据中按照一定的规则重复抽取大量不同的子样本来估计目标参数的估计量和方差估计量。其实质是每次重复抽样后得到的重复权数是不同的,由此得到的估计量也是不同的,这个重复的权数称为重权数(replicate weight),本文主要介绍如何利用重权数得到不同抽样设计下的目标参数的估计量和方差估计量。
利用重权数计算目标变量的估计量和方差估计量主要有以下优势:
(1)克服复杂抽样调查的方差估计问题。实际调查的抽样设计一般都是分层、多阶段、不等概的复杂抽样设计,若利用公式法计算目标变量的方差估计量,计算过程十分繁杂。而重权数方法借助计算机的优势通过不断获得重权数计算目标变量的估计量,从而克服了复杂公式方差计算法的缺陷,简便实用。
(2)克服多类型多目标调查的方差估计问题。实际的抽样调查往往是一个多目标的调查,即目标参数包含均值、总量、相关系数、比例、分位数、模型参数等各种类型的目标估计量,在实际调查中还不可避免地存在无回答、事后分层等情况。此时,利用传统的方差估计方法是十分困难的,有时也是无法做到的,利用重权数方法可以比较方便地解决这个问题。
(3)避免数据的抽样设计者和数据使用者(数据分析者)之间的误解。在实际调查中,数据的抽样设计者和数据的使用者并不相同。对于一个复杂调查数据,数据使用者需要获得完整有效的抽样信息,并能够利用这个抽样信息进行数据分析,但是这个工作往往是十分困难的。通过重权数方法可以克服这个问题,因为重权数是由抽样设计者根据完整的抽样设计和抽样实施过程的所有抽样信息获得的,数据分析者无需了解数据获取抽样信息,直接利用重权数就可以准确地分析数据,避免分析者和抽样者之间的误解。
(4)保护隐私,避免过多信息泄露。重权数方法只给出重权数,避免提供个体信息和抽样信息,一定程度上可以防止过多的信息泄露。有些国家在数据发布时已经开始用重权数来替代抽样信息。
(5)更好地解决域估计问题。在复杂调查中,有些分析者更关心部分群体的特征,例如某个年龄段人群的消费情况,利用重权数方法可以方便有效地进行域估计,只需要提取出相应域的数据集和重权数进行数据分析即可。
正因为重权数具有上述优势,其在复杂数据分析中将发挥越来越大的作用,下面我们分别介绍各种重权数的计算方法。
二、平衡半样本方法的重权数
平衡半样本方法[2-4]是McCarthy(1966)提出的一种方差计算方法,主要针对复杂调查中每个层中的初级单元个数不多的分层简单随机抽样。这种方法可以估计非线性估计量、线性估计量、分位数等估计量,在方差估计中占有重要的地位。


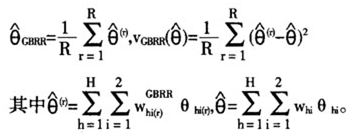
其中i=1,2表示半样本,h=1,2,…L表示层,r=1,2,…R表示重复次数,从而得到目标变量 的估计量和方差的估计量是:
的估计量和方差的估计量是:
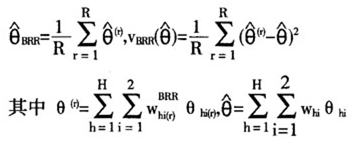
在实际抽样设计中,往往会出现某些层中的样本量大于2,针对这个问题一种是利用混合正交矩阵[5]的方法,另一种方法是利用分组平衡半样本方法[6](Grouped Balanced Repeated Replication)。前一种方法需要引入混合正交矩阵,计算方法也比较繁杂。在实际中多用分组平衡半样本的方法,即将层中的样本单元随机分为2个虚拟组,一个虚拟组的样本单元的个数是 ,([
,([ ]表示取整),另一个虚拟组的样本单元的个数是
]表示取整),另一个虚拟组的样本单元的个数是 ,则重权数是:
,则重权数是:
 (2)
(2)
得到目标参数的估计量和方差估计量是:
分组平衡半样本方法对某些层的样本单元进行了随机分组,降低了估计量的精度,在分组过程中应尽可能地利用辅助信息使两个虚拟组相似,当无法获得层内单元相关信息时需要通过多次重复分组的方法提高目标变量的估计精度。
在抽样设计中,有效的分层可以大大地提高目标变量的估计精度,但是太多的层会导致计算量过于庞大,利用部分平衡半样本方法[7](Partially balanced Repeated Replication)可以有效降低计算量,即将上层分成G(G<L)个虚拟层后进行的平衡半样本方法。设 是一个虚拟层集,利用R×G的正交矩阵
是一个虚拟层集,利用R×G的正交矩阵 ,其中:
,其中:

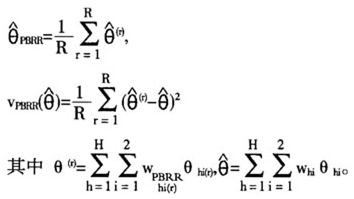
则部分平衡半样本方法的重权数是

目标参数的估计量和方差估计量是:
这种平衡半样本方法不仅提高了计算效率,而且当层内只有一个样本单元无法直接计算方差时,同样需要利用这种平衡半样本方法得到方差估计量。但是,这种方法由于合并层而引入了层间偏差,导致方差估计量的高估。为了提高估计的精度,在实际计算过程中,应尽可能利用辅助信息合并相似的层,例如利用辅助信息对层进行排序,然后对邻近的相似层进行合并。另一方面也可以通过提高重复抽样的次数或重复执行上述计算过程提高估计精度。
上面介绍的平衡半样本方法是一种标准的平衡半样本方法,这种方法存在一定的缺陷,一方面每个层中的权数变化较大容易产生较大的方差,另一方面当每个层中的样本量比较少时容易导致比例估计量的方差变化过大甚至无法计算。Robert Fay将上述平衡半样本方法进行扩展,通过引入Fay因子占(0≤ε<1)来减弱层内权数的变化,即Fay的平衡半方法[8],此时的重权数是:

由于Fay的平衡半样本方法利用了更多的信息,提高了估计的精度,应用也更为广泛。当ε=0时是标准的平衡半样本方法,同样的,由于实际情况的复杂性,也存在Fay的分组平衡半样本、Fay的部分平衡半样本估计方法。
三、刀切法的重权数
刀切法(Jackknife)[2,9]是由Quenouille(1949、1956)作为减少系列相关系数估计量偏倚的一种方法提出的,后来逐渐成为复杂样本方差估计的一种重要方法。

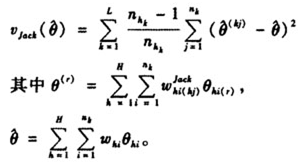
在分层抽样设计中,若每个层中的样本量都比较大,则用刀切法可以提高估计的精度,但是刀切法对于估计非线性估计量尤其是分位数估计量通常会失效,弃-d的刀切法可以有效解决这个问题,即每一层的样本单元每次随机舍去d个,同样的方法可以得到弃-d的刀切法的估计量。
刀切法要求每个层中的样本量要足够大,但是在实际调查中,某些层的样本个数可能比较小,为了提高计算效率,可对样本个数比较小的层进行邻近层合并,称为合并层刀切法(Combined Strata Grouped Jackknife),即将L层合并成G个虚拟层,设 是一个合并层集,则重权数是:
是一个合并层集,则重权数是:
 (6)
(6)
其目标参数的估计量和方差估计量是:
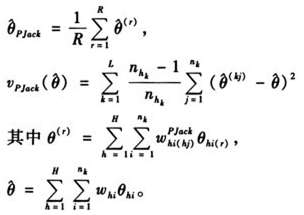
四、自助法的重权数
自助法(Bootstrap)[2][9]是由B.Efron(1979)教授在刀切法的基础上提出的一种利用重抽样方法对总体参数进行估计的统计方法。

表示第h层的第i个单元在第r次重复入样的次数,重复上述过程B次,得到自助法的重权数是:
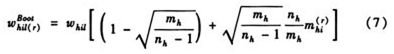
其目标参数的估计量和方差估计量是:
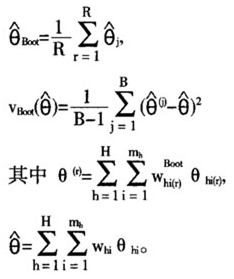
同样的,由于实际情况的复杂性,也会产生合并层自助法等。
五、无回答和事后分层调整权数
在复杂的抽样调查中,经常包含无回答现象,以及为了提高估计精度而需要进行的一些关键变量的事后分层等现象。抽样调查利用权数与数据的乘移得到目标参数的无偏估计量,即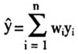 ,其中的权数
,其中的权数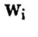 是经过基础设计权数、无回答权数、事后分层调整权数[10]调整后的最终权数。
是经过基础设计权数、无回答权数、事后分层调整权数[10]调整后的最终权数。
但是,在利用重权数方法进行目标变量的估计量和方差估计时,需要在基础设计的权数基础上进行,因为重抽样的实质是对样本按照原抽样设计反复抽取子样本的基础上,而得到的重权数是在基础设计权数调整的基础上再进行无回答和事后分层权数的调整。例如一个两阶段的随机抽样设计,其最终的权数是:
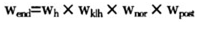
其中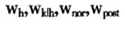 。分别是第一阶段的权数、第二阶段的权数、无回答调整权数、事后分层调整权数。若是用刀切法,第一阶段的初级单元每次舍去一个j,也就是第一阶段的样本单元的入样概率发生了变化,所以第一阶段的权数需要乘以
。分别是第一阶段的权数、第二阶段的权数、无回答调整权数、事后分层调整权数。若是用刀切法,第一阶段的初级单元每次舍去一个j,也就是第一阶段的样本单元的入样概率发生了变化,所以第一阶段的权数需要乘以 。第二阶段是从第一阶段入样的初级单元的基础上进行的,因此每个样本单元的第二阶段的人样概率没有发生改变。而无回答调整权数、事后分层调整权数若调整只是在第一阶段的初级单元的基础上进行的,即最终的权数是
。第二阶段是从第一阶段入样的初级单元的基础上进行的,因此每个样本单元的第二阶段的人样概率没有发生改变。而无回答调整权数、事后分层调整权数若调整只是在第一阶段的初级单元的基础上进行的,即最终的权数是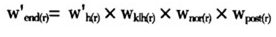 。若是无回答权数调整和事后分层调整是在整个样本中进行的,则需要进行调整,例如无回答调整是在样本的m个子总体中进行,则无回答调整权数、事后分层调整分别是:
。若是无回答权数调整和事后分层调整是在整个样本中进行的,则需要进行调整,例如无回答调整是在样本的m个子总体中进行,则无回答调整权数、事后分层调整分别是:

任何抽样设计都可以按照上述方式对重权数进行无回答和事后分层权数的调整,在实际计算中还可以进行校准权数等的处理,其基本原理是一样的。最后将重权数提供给数据使用者,利用重权数计算目标参数的估计量及进行方差估计量和相应的数据分析。
六、重权数的软件应用
由于重权数在复杂调查中的简便性和有效性,目前已有许多软件提供利用重权数进行数据分析的功能,例如SAS、Sudaan、WeSvar、R、Splus、Stata等都有专门的模块、程序包帮助数据使用者利用重权数进行数据分析,本文仅以R软件为例展示重权数在数据分析中的应用。
R软件是近年来发展较快的一种统计软件,以其方便性、免费性、灵活性受到越来越多的统计工作者的喜爱。复杂调查的重权数主要通过“Survey”程序包的as.svrepdesign和svrepdesign命令完成,其中as.svrepdesign用来产生抽样设计的重权数,svrepdesign用重权数进行数据分析。R软件中利用重权数进行数据分析的基本原理是假定方差估计量的一般形式是:

下面用一个模拟例子说明如何利用R软件进行方差的计算。一个针对中国6-15岁青少年儿童发育特征的综合调查,采用分层三阶段不等概率复杂抽样设计,即首先将全国的区县按照人大发展指数和区县的发展水平分成14个层,第一阶段是在14个区县层中抽取100个样本区县;第二阶段是在每个样本区县中抽取学校;第三阶段是在每个样本学校的各个年级中抽取一定数量的学生。目标变量涉及各个年级、各个区域的均值、总量、百分数、相关系数等多种类型,若采用常规的方差计算方法,计算过程十分繁杂,此处用重权数的方法进行分析。由抽样设计和数据情况,利用R软件,分别用平衡半样本方法、Fay的平衡半样本方法、刀切法和自助法进行计算。本例中的目标参数是三年级青少年儿童的某能力测试的得分y的均值估计量和方差估计量,其他变量的计算过程与之相同:
(1)按照分层三阶段随机抽样的方式抽取学生样本,第一阶段在14个层中每层随机抽取2个样本区县,第二阶段在每个样本区县中随机抽取2个样本学校,第三阶段在每个学校中随机抽取10个样本学生,估计目标变参数y的均值和方差。
(2)利用R软件的程序包survey中命令svrepdesign,并选择BRR、Fay、JKn和bootstrap四种方法,计算y的均值和方差估计量。
(3)在上述方法的基础上,对每次的重权数按照城市、农村、县镇的事后分层调整后计算y的均值和方差估计量。
(4)重复上述过程(1)-(3)100次,得到估计结果如表2。
表2数据模拟结果

由表2得到,重权数是一种有效的估计计算方法,而且经过事后分层调整的重权数方法的精度更高。
七结论
本文主要从重权数的角度计算目标参数的估计量和方差估计量,重权数方法和重抽样方法一样都是借助计算机的优势,通过在调查数据中重复获得大量不同的子样本的重权数估计总体目标参数的估计量和方差估计量,是一种稳健、通用、有效的方差估计方法。重权数中包含大量的抽样信息,可以帮助数据使用者更好地分析数据,避免了数据使用者和数据收集者信息不对称的矛盾,另一方面重权数对处理纵向数据的方差分析、缺失数据问题也有一定的优势。目前已有许多统计软件,例如SAS、R、Stata等有专门的模块帮助数据使用者利用重权数进行数据分析,但是实际情况总是十分复杂的,往往无法直接利用这些统计软件进行数据分析,掌握重权数的基本原理,利用软件编程是比较好的选择。
参考文献:
[1]Rao, J.N.K. , Wu, C.F.J. , and Yue, K. Some Recent Work in Resampling Methods [J]. Survey Methodology, 1992 18, 209-217.
[2]Wolter, K.. Introduction to Variance Estimation[M]. New York: Springer-Verlag, 1985.
[3]Krewski, D., and Rao, J. N. K. Inference from stratified samples: proper-ties of the linearization, jackknife, and balanced repeated replication methods [J]. Annals of Statistics, 1981. 9,1010-1019.
[4]Rao, J. N. K, and Shao, J.On balanced half sample variance estimation in stratified sampling. Journal of the American Statistical Association, 1996,91,343-348.
[5]Sitter, R. R.. Balanced repeated replications based on orthogonal multi-arrays[J]. Biometrika, 1993,80, 211-221.
[6]Rao,J. N. K, and Shao, J. Modified balanced repeated for complex survey data[ J]. Biometrika, 1999, 86,403-415.
[7]Lee, K.H. The use of partially balanced designs for half-sample replication method of variance estimation [J]. Journal of the American Statistical Association,1972, 67, 324 - 334.
[8]Judkins, D.R.. Fay's Method for Variance Estimation[J]. JOS,1990, 6, pp. 223-229.
[9]Shao, J., and Tu, D. The Jac'kknife and Bootstrap[M]. New York: Springer-Verlag, 1995.
[10]Fay, R. E. Theoretical application of weighting for variance calculation [J]. Proceedings of the Section on Survey Research Methods of the American Statistical Association, 1989, 212 -217.
教育频道,考生的精神家园。祝大家考试成功 梦想成真!
经济学
重权数在复杂调查的方差估计中的应用
http://www.newdu.com 2018/3/7 《统计研究》(京)2011年2期第93~99页 吕萍 参加讨论
Tags:重权数在复杂调查的方差估计中的应用
责任编辑:admin相关文章列表
没有相关文章
[ 查看全部 ] 网友评论