内容提要:插补是另一类对缺失数据进行调整,以减小估计偏差的方法。本文介绍的插补方法有:演绎估计,均值插补,随机插补,回归插补和多重插补。
关键词:缺失数据 插补调整
作者简介:金勇进中国人民大学统计学系,北京100872
一、无回答的类型与插补法的运用
调查中的无回答有两种类型,一种被称为“单位无回答”,它是指入选样本单位由于各种原因没有接受调查,可以说这些样本单位交的是一份白卷。另一种被称为“项目无回答”,它是指被调查单位虽接受调查,但在某些调查项目上没有提供有效回答。与单位无回答相比,项目无回答或多或少地提供了一些被调查单位的信息。上一讲中介绍的加权调整法虽然也可以应用于“项目无回答”,但主要是对“单位无回答”进行的调整。而本文将要介绍的插补调整法虽然也可以应用于“单位无回答”,但主要是对“项目无回答”进行调整的方法。
所谓插补是指,采用一定的方式,为调查中的缺失数据确定一个合理的替补值,插补到原缺失数据的位置上。插补可以达到二个调整的目的:一个是减小由于数据缺失可能造成的估计量偏差,为此,就要使确定的替补值尽可能地接近缺失的原数据值。事实上缺失数据的真值我们无法得知,因此所追求的只能是确定替补值方法的合理和有效。调整的第二个目的是力图构造一个完整的数据集。在调整前,由于缺失值的存在,使原数据集上出现许多“窟窿”,给一些统计分析方法的使用带来不便。采用插补的方式填补了缺失值的空缺,就为后面分析人员的工作提供了方便,他们在使用标准统计软件的同时,不必繁琐地说明对缺失值进行处理的方法,大大节省了精力和时间。而且不同分析人员使用的是同一套经过插补调整的数据,也保证了分析结果的一致性。
插补的效率如何,取决于替补值与缺失值的近似程度。为了提高效率,对研究总体进行分层,使层内各单位诸方面情况尽可能相似,利用同一层内回答单位的信息产生出缺失数据的替补值,是进行插补的基本思路。因为可以利用不同的信息源,采用不同的方式生成替补值,所以有不同的插补方法。本文将对几种比较典型的方法做以简要介绍。
二、演绎估计法
演绎估计法适用于这样一种情况,目标变量Y的缺失值可以以很高的确定性由其它辅助变量来决定。这意味着,目标变量与辅助变量之间存在着已知的函数关系,即Z[,i]=f(X[,i])。式中Z[,i]是第i个单位目标变量缺失值的估计值(替补值),X[,i]是第i个单位已知的辅助变量值。例如美国在一项关于医疗设备使用和费用的调查中,多处使用演绎估计法对缺失值进行插补。1.对种族缺失值的插补函数式为Z[,i]=X[,i],即如果某人种族数据缺失,可采用其配偶的种族;如果某家庭成员种族资料缺失,可使用户主的种族。2.如果年龄项目数据缺失,则利用出生年份资料讲行估计。若调查是在1990年进行,令X[,i]为出生年份,则Z[,i]=1990-X[,i]。3.若就业收入的数据缺失,则利用其它4个相关的辅助变量信息推算。令X[,1i]、X[,2i]分别为该被调查者的主要职业和第二职业的周工资率,X[,3i]、X[,4i]分别为其在主要职业和第二职业上的工作周数,则劳动收入的估计值为Z[,i]=X[,1i]・X[,3i]+X[,2i]・X[,4i]。
由此看出,f(X[,i])可假定为许多不同的形式。使用的条件是Y与X之间存在确定的函数关系,且X值已知。实践中,可以把演绎估计法视为对数据进行逻辑审核的一部分。
三、均值插补法
首先根据辅助信息将样本分为若干组,使组内各单位的主要特征相似。然后分别计算各组目标变量Y的均值,将各组均值作为组内所有缺失项的替补值。均值插补法的特点是操作简便,并且对均值和总量这样的单变量参数可以有效地降低其点估计的偏差。但它的弱点也比较突出。一个是插补的结果歪曲了样本单位中Y变量的分布,因为同组中缺失数据的替补值都由该组的平均值充当,使得其分布状况受到由各组回答单位数据计算出的组均值的制约,其次,插补结果将导致在均值和总量估计中对方差的低估,因为同一组内样本单位的离差将由于同一个数值的多次出现而偏低,因此均值插补适用的场合是仅仅进行简单的点估计,而不适用于需要方差估计等比较复杂的分析。
四、随机插补法
为避免均值插补中替补值过于凝集的弱点,随机插补应运而生。这种方法是指,采用某种概率抽样的方式,从回答单位的资料中抽取缺失数据的替补值。为便于说明,令某项目回答数据个数为n[,1],缺失数据个数为n[,0],即n=n[,1]+n[,0],现从n[,1]个数据中随机抽取n[,0]个替补值,则样本构成为:


式中,S[2]为总体方差。可以看出,随机插补法估计量 的方差由两部份组成,等式右边第一项是仅用回答单位数据进行估计的方差,即
的方差由两部份组成,等式右边第一项是仅用回答单位数据进行估计的方差,即
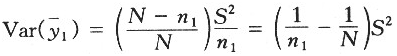 ,第二项是由于增加了一个再抽样过程而带来的估计量方差增加项。随机插补虽然使估计量的方差增大了,但是它避免了均值插补容易扭曲目标变量分布的弱点,使替补位的分布与真值分布更为接近,这就使随机插补法在估计与样本分布有关的参数时具有明显的优势。
,第二项是由于增加了一个再抽样过程而带来的估计量方差增加项。随机插补虽然使估计量的方差增大了,但是它避免了均值插补容易扭曲目标变量分布的弱点,使替补位的分布与真值分布更为接近,这就使随机插补法在估计与样本分布有关的参数时具有明显的优势。
显然,根据调查中所得到的辅助变量信息,将样本单位进行事后分层,然后在各层中使用随机插补法,就会有更好的调整效果。
五、回归插补法
回归插补的基本思想是利用辅助变X[,k]=(k=1,2…k)与目标变量Y的线性关系,建立回归模型,利用已知的辅助变量的信息,对目标变量的缺失值进行估计。于是第i个缺失值的估计值可以表示为:
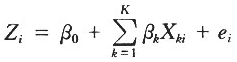
式中的β是回归系数。若辅助变量是定性变量时,可以采用虚拟变量的处理方法:若目标变量Y是定性变量,则考虑通过Logit变换,进行Logistic线性回归。与随机插补和均值插补的不同点在于:Z[,i]不是取自回答单位的实际值,也不是由回答单位数据计算的均值,而是利用目标变量与辅助变量的线性关系,采用标准方法(如最小平方法)计算出的估计值。
上面的回归模型可以有不同的演变形式。例如,对于连续性固定样本调查中的缺失值,今β[,0]=e[,i]=0,并指定前期调查数据为唯一的辅助变量,则上式变成:Z[,i]=βX[,i],这便是简单比率插补,即用时间的变化,对前一期的回答数据进行调整,并做为本次调查缺失值的替补值。
应用回归插补法中一个讨论的问题是e[,i]的处理,因为经过回归后,Z[,i]的估计为 ,对于相同的X[,k](k=1,2,…k),得到的替补值是相同的,这就会和均值插补一样,存在样本分布扭曲的问题。为此需要构造随机残差e的数据集。构造的方法有多种,比较典型的一种方法是,根据辅助变量X[,k]将样本单位分层,在各层中将回答单位数值与其均值的离差视为残差e,在用回归法得到
,对于相同的X[,k](k=1,2,…k),得到的替补值是相同的,这就会和均值插补一样,存在样本分布扭曲的问题。为此需要构造随机残差e的数据集。构造的方法有多种,比较典型的一种方法是,根据辅助变量X[,k]将样本单位分层,在各层中将回答单位数值与其均值的离差视为残差e,在用回归法得到 后,在该层的残差集中随机抽取
后,在该层的残差集中随机抽取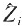 的残差项,并将其和作为缺失值的替补,即:
的残差项,并将其和作为缺失值的替补,即: 。
。
最后,由回答数据y[,i]和回归替补位Z[,i],得到目标变量的估计值为

六、处理缺失数据的多重插补法
(一)什么是多重插补法
在上面介绍的插补方法均是单一差补法,即对每个由于无回答造成的缺失值只构造一个插补值。单一插补法存在这样或那样的局限,如均值插补容易扭曲样本分布,随机插补的稳定性不够,等等。能否有一种方法综合起单一插补法的各自特长,而将其弱点降低到最小程度?多重插补法就是在这个背景下提出的。美国哈佛大学统计系的Rubin教授70年代末首先提出多重插补的思想,80年代中与其他学者一起进一步扩展,充实了多重插补的理论与方法。90年代许多学者对这种方法继续研讨,该方向上的研究目前仍在继续。
多重插补的主要思想是,给每个缺失值都构造m个插补值(m>1),这样就产生出m个完全数据集,对每个完全数据集分别使用相同的方法进行处理,得到m个处理结果,最后再综合这m处理结果,最终得到对目标变量的估计。构造m个插补值的目的是模拟一定条件下的估计值分布,因此,多重插补法的实质是一种模拟方法,研究人员可以借此估计目标量的实际后验分布。
(二)多重插补法的推断理论
多重插补法的理论证明来源于贝叶斯理论,它由Rubin在80年代初期以一系列的论文提出,其基本的理论架构被他整理在一本书中(Rubin "Multiple Imputation for Nonresponse in Surveys"),这里仅对其推断理论做一简要介绍,假定我们的目标是从一个有缺失的调查数据集中推断目标总体,并且缺失值的后验分布(给定回答值的条件分布)可以获得,那么目标总体的后验分布由下式给出:


以上关于多重插补推断理论的详细证明,请参阅Rubin的书(见参考文献[1])。
用多重插补法处理缺失值的常用软件有NORM(注:Www.stat.edu/~jsl(J.L Schafer)),SOLAS(2.0版本),SAS(8.0版本)(注:Www.statsolusa.com),AMELIA等。
(三)一个例子
这里用一个例子来说明多重插补法的使用,例子取自于Rubin的书(19-22页)。此例展示了多重插补法的三个步骤:插补、分析、合并。
假定从一总体N=1000中采用简单随机抽样,抽取n=10的一个样本,目标变量Y,辅助变量X,调查中无回答率为20%,即y[,4],y[,6]缺失,具体数据如表1:

步骤一插补
由上数据知,目标变量Y与辅助变量X存在相关关系,假定采用简捷的最近距离法为每个缺失值插补两次,即m=2。第一个缺失值的辅助变量x=9与其最近距离的有x=8和x=11,故取与之对应的y=10和y=14为第一个缺失值的插补值。同样的方法,第二个缺失值的插补值为y=16和y=14,由此形成两个完全数据集。在三个步骤中,插补这个步骤甚为关键,实际处理中需要根据具体情况,选择适当的插补模型。
步骤二分析
现在我们感兴趣的是比估计量。根据比估计公式


七、总结
插补调整常用于对项目缺失数据的处理。造成项目数据缺失的原因有多种,比较常见的有项目无回答,此处缺失值还产生异常值的剔除。虽然这些异常值是回答者实际提供的,但由于它们是极端值,把它们修正为正常值对分析可能更有利。当然,在数据审核中,把明显的,不合逻辑的数据删去,用插补法进行调整,也是一种补救措施。与花费很高费用去寻找正确数值相比,或与用可疑数据进行分析相比,采用插补法对可数据进行修正是可以考虑的选择。
多重插补法提出了处理缺失数据的一个新思路。这种方法采用模拟数据的方式。尽可能地提取调查中的有效信息。与单一插补法相比,多重插补法具有一些明显的优点:首先,该方法利用多个插补值之间的变异性反映缺失值的不确定性,进而为估计抽样误差提供了依据;其次,多重插补可以保持研究变量之间的相关性,不像单一插补那样容易扭曲变量间的关系,这样,它的应用范围就更加广泛。例如,如果调查中的无回答率较高,单一插补的估计效率会受到很大影响,而多重插补所受影响则相对小得多;最后,插补的效果与构造插补值的模型有关,多重插补数据可以模拟特定方法下估计值的分布以及总体参数的贝叶斯后验分布,这就为更好地理解和进一步改进插补方法提供了发展空间。
当然,多重插补法的操作比较复杂,工作量大,与单一插补法相比,成本增加许多,因此有些学者置疑,估计质量的提高能否补偿增大的成本;还有,在多重插补的理论与应用方面,有些学者也持有疑议。看来,对多重插补的理论与应用研究还会继续下去。
插补法的运用离不开辅助信息。相对于目标变量的缺失值而言,辅助信息既可以来自于同一次调查,也可以取自于以前的调查或其它有关资料。显然,辅助信息的质量越高,与目标变量的统计关系越密切,使用插补法的效果就越好。但即便如此,在使用调整后的数据集时都应时刻注意,毕竟此“完全数据集”非彼完全数据集,在使用分析结果时对该结果抱一种客观而谨慎的态度。