内容提要:对数据分组之后再进行处理是一种常见方法,但是这种方法可能产生错误结果。本文搜集了几个实际的数据分析案例,说明对数据的分析可以是任意的,但是对分析结果的解释必须受制于研究对象和周围条件。本文结合案例提出了一些避免分组陷阱的手段,还提供了理解辛普森悖论的一个角度。
关键词:辛普森悖论 数据分组 统计方法的滥用
作者简介:张皓(1968-),北京人,中国人民大学书报资料中心经济编辑室主任,编辑,主要从事编辑学、经济统计研究(北京100086);黄向阳(1970-),湖北黄梅人,中国人民大学统计学院副教授,经济学博士,主要从事风险管理和精算研究(北京100872)。
引言
科学方法的基本前提是对事物进行分类,然后假设类之间存在着相对稳定的联系,作为统计学家的K.皮尔逊在《科学的规范》中指出“事实的分类、对它们的关联和相对意义的认识是科学的功能”。统计学家所发展起来的统计方法充分体现了这一观点,1980年代之后成熟起来的数据挖掘技术仍然认为自己的主要任务是分类和关联分析。从逻辑上来看,某种程度的分类或者汇总是不可避免的,但是把研究对象分为若干类在逻辑上又必然存在缺陷。要保证分类的合理性,就必须满足数据的同质性,而同质性假设在最好的情况下是一种近似,在比较糟糕的情况下则是研究者个人判断的结果。社会学家由于意识到自己研究的是复杂现象,所以从18世纪起就一直反对使用数据同质性假设。最典型的例子是对“平均人”概念的看法。虽然平均人可以反映部分现实,但它所掩盖的可能多于所能揭示的东西,而且缺乏现实生活中的对应物。尽管存在种种有力的反对意见,以分类为依据的数据分组还是逐渐成为统计分析的基本程序之一。而对于分组方法的认真检视则逐渐淡出统计学家的视野,相关论述已经很罕见了,但陈希孺在《数理统计学简史》中还是用了几页篇幅回顾了有关问题(注:从142页到149页的主要内容是讨论19世纪的社会学研究如何处理数据的同质性问题。)并指出[1]:
开维伯格和科洛特……揭示了将统计方法用于社会问题的困难所在,即如何决定所研究的总体的细分程度,以便可以通过数据资料对问题进行有意义的分析。这一点不仅在当时,即便在今日,也不能说有了完满的解决。
陈希孺特别指出这个问题从根本上说不是一个统计或数学的问题,可能正因为它是一个更基本的问题,所以即使在统计学方法高度发展的20世纪,分组不当还在不断引发各种问题。而要深入理解分组方式的影响,也要超越统计学的边界才有可能。
分组的实现方法一般是,首先按照一个或多个分类指标对数据进行分组,然后分析各组数据的统计指标,由此形成的交叉表是进行二维或者高维列联分析的基础数据。从方法依据来看,这是进行数据压缩的具体手段之一,而数据压缩是统计方法的基本特点;从使用效果来看,列联表和几个简单百分比在结果的呈现方面具有很强的说服力,因此也得到广泛使用。由于这两个原因,数据分组变成了基本统计方法之一。但是这种做法往往隐藏着很多的陷讲。首先,数据压缩必然引起种种后患,比如信息损失、指标失真或者虚假相关,如果考虑不周就很有可能得到似是而非的分析结论。其次,这种做法本身具有误导能力,可能被有心人士用来操纵数据的解读,从而导致统计方法的滥用。本文搜集了几个数据分析中的实例,说明了汇总数据可能造成误导,并指出了一些解决的方法。一般来说,对数据的处理可以是任意的,但是赋予处理结果以意义就必须受到各种环境的限制。当然,在统计分析中如何有效地结合“让数字说话”和“跟常识比对”这两种方法是一个没有定论的问题,值得我们不断探索和改进。
一、和数据分组有关的几个案例
辛普森悖论可以看作分组不当造成理解混乱的典型案例,但是在统计学历史上,还有一个已经被我们忘却的发生在1933年因为分组不当造成的风波。下面本文将介绍1933年的风波、辛普森悖论和出现在统计学教科书上涉及分组问题的两个案例。
(一)1933年的统计学风波
Stigler回顾了已经被大家忘却的1933年统计学风波[2],故事的主角是当时很有名的统计学家Secrist和现在依然很有名的Hotelling。Secrist在1933年出版了名为《平庸状态在商业活动中的胜利》(The Triumph of Mediocrity in Business),指出平庸状态在竞争行业中会逐渐流行,最后占据主导地位。这本书的篇幅和数据量是令人惊叹的:作者考察了百货商店、五金店、银行等各个行业,全书有468页,140张表格和103张图表。把49家百货店按照1920年的利润率分成4组,按照当时的四分位数来分组。Secrist跟踪了这些组的时间序列数据,确切地说是各组的平均值时间序列,就发现了随时间趋同的明显趋势。这个结果在出版前,经过了多位统计学家的匿名评审,在出版之后引发一片惊叹,直到Hotelling发表文章指出Secrist仅仅利用数据验证了一条定理,即条件期望的方差(给定第一年的结果)小于无条件方差。就是说Secrist的研究成果没有错误,但是毫无意义,相当于正确的废话。Hotelling一锤定音,大家突然都明白了,只有Secrist无法接受他的意见,并开始用措辞激烈的文章攻击Hotelling。最后,Hotelling只好撰文打了一个比方作为回应,这个比方虽然有些尖刻,但对于从事应用统计工作的人来说却是醒世良言:
(Secrist的研究)就好像先通过排列大象方阵,然后再排列一系列其他动物来验证乘法口诀一样,费时费力。这个过程可能具备一定的娱乐价值,但是对统计学和动物学两无所益。
不知道有多少挂着统计学之名的研究成果都是在用大象方阵验证乘法口诀呢。Secrist的错误源于他的分组方法,利润率在1920年属于同一组的百货店经过几年之后必然会出现分化,就是说原来近似成立的组内数据同质性随着时间流逝消失了。到1930年,当年属于同一组的百货店基本上可以成为全部49家百货店的一个随机样本,其均值自然会接近总体均值。现在不会再犯这种错误了。通用的方法是用一个转移矩阵来描述各组的企业在一段时间之后(通常为一年)进入其他组的概率,由此形成的转移概率矩阵更具说服力。在企业破产概率评估和信息评级中也是采用信用级别转移概率矩阵来解决实际问题的。Secrist风波的教训是:数据分组之后也许能够提供看起来很漂亮的结果,但是这些结果可能毫无意义。不过许多人并没有汲取这个教训,比如我们能看到的企业统计指标往往都是根据企业规模汇总之后的结果,很少给出这些指标的分位数,这些数字包含的信息量就非常有限了。
(二)从选取分组指标的角度分析辛普森悖论
辛普森悖论到现在还是统计学中的未解之谜,涉及定性数据分析或者列联分析的教材通常都会提到这个悖论。本文引用的材料来自王静龙和梁小筠[3]。本文表述的重点是统计方法可以对数据作任意处理,但是处理结果的解读并不是任意的,如果不作全面考察,就会导致自我实现的分组变量。辛普森悖论的数据来源于1976年到1977年美国佛罗里达州29个地区凶杀案的有关数据,研究者关心的主要问题是死刑判决是否受到种族歧视的影响。为了解答这个问题,根据原始数据建立凶手肤色和死刑判决结果的二维列联表是一个很自然的选择,结果如表1所示。


从表1的数据来看,在死刑判决中似乎没有肤色歧视,数据甚至表明白人凶手被判死刑的比例还略高一点。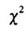 检验的p值超过了0.05,那么从统计角度来看,可以认为凶手肤色与死刑判决无关。但是如果考虑更多的因素,用一张三维列联表把受害人的肤色也考虑进来,就会得到表2。
检验的p值超过了0.05,那么从统计角度来看,可以认为凶手肤色与死刑判决无关。但是如果考虑更多的因素,用一张三维列联表把受害人的肤色也考虑进来,就会得到表2。
表2的数据表明,无论受害人是白人还是黑人,黑人凶手被判死刑的比例都明显高于白人凶手被判死刑的比例。教材中的普遍解释是“表1的分析是有偏的,被害人的肤色是混杂因素。”证明的依据就是表2提供的分析结果。但是我们为什么就要相信还没有其他的混杂因素呢?数据中没有列举陪审团的组成情况,也许实际情况是陪审团的肤色比例决定了判决结果呢?所以简单地用一张三维列联表来否定二维列联表有五十步笑百步的嫌疑。因为大家都假设了分组之后的组内数据同质性,而这种同质性并没有得到严格验证,它是研究者隐含在分组方式中的。
从更广阔的视野来看,统计方法是系统研究人类推理方式的,仅仅在数据中打转就无法理解辛普森悖论。引起辛普森悖论的原因是我们的提问方式,而不是统计分析方法。我们执著于寻找一个或几个真正原因的动机是推动我们进行分组的内部动力。考察表1背后的推理方式也许能够解答我们的疑惑。在计算死刑判决比例的时候,从数值上来看,是19/160=0.119。按照定义,除法运算有意义的前提是分子和分母具有可比性,所以这个除法运算依赖于一个隐含前提:是否做出死刑判决仅仅和凶手肤色有关。就是说,数据的分析过程和其隐含前提之间存在着某种循环论证的可能性。只有接受这个隐含前提,才能让0.119这个数字具有可以理解的实际意义,否则它就仅仅是一个计算出来的没有意义的数字。这样在许多场合下,分组变量可能变成一个自我实现的预言,即假设这个变量能够产生显著影响,然后我就能证明的确如此。这也是统计分析方法经常受人诡病的一个主要原因。毋庸讳言,对数据的处理是任意的,因为那仅仅涉及对数字的数学加工,但是赋予处理结果以实际意义就不是任意的,要经受多个角度的考察。高维列联表也许仍然包含混杂因素,但是比起二维列联表来是一个进步。
(三)如何解读列联分析中的行列百分比
即使在二维列联表中,解读数据处理结果的过程也充满陷饼。下面这个例子说明,列联表的行列百分比的意义和抽样方式有直接联系,必须结合抽样方式解读行列百分比,否则就会得出错误的结论。这个例子来自贾俊平等[4]。社会学家希望研究某个地区中家庭状况对青少年犯罪的影响。该地区无犯罪纪录和有犯罪记录的青少年分别是10000名和150名,从无犯罪纪录的青少年中抽取100人,比例为1%,为了保证有犯罪记录的人数,必须扩大相应的抽样比例,比如扩大为1/2。由此得到一张二维列联表,如表3所示。

如果看列百分比,就会发现完整家庭中有犯罪记录的青少年的比例是38/130,当然不符合常识,贾俊平等(2007)建议把家庭状况(作为自变量)放在列变量的位置上以免导致误解。这当然是一个很好的建议,但是我们认为问题的关键不在于能否这样处理数据,而是这种数据处理的意义何在。这个除法描述的是样本的实际情况,它不是没有意义的演算,更不是一个错误的结果。问题在于它能否从样本推广到总体上去?而我们知道,这个样本是严重有偏的,样本的特征不能简单地推广到总体上去。但是问题在于,这项研究必然要用样本的某些特征来说明总体,在样本严重有偏的情况下,哪些样本特征可以用来描述总体呢?这里我们再次碰到了不是统计方法所能解答的问题:数据处理可以是自由的,但是结果的解读是受制于实际环境的,尤其是样本代表总体的能力。
(四)人口密度与社会经济发展指标
这个案例来自教材《社会经济统计》[5],由于分组不当产生了错误结果。研究者关心的是人口密度和人均收入之间的关联,通过对数据合并得到了如下结果,见表4。

教材中的解释如下:
从表可以看出,低收入国家的人口密度是高收入国家的2.5倍之多。由此可以做一个简单推断:和高收入国家相比,对很多发展中国家而言,更高的人口密度意味着同样大小的土地需要承载更多的人口,过于庞大的人口规模成为其社会经济发展中的重要制约因素。
表4中的数据是很漂亮的,能给读者留下深刻印象。但是认定高收入国家的人口密度最低却让人觉得似乎有违常识。考察原始数据,就可以发现认为人口密度与发展水平成反比的看法并不可靠。我们放弃根据国家人均收入水平进行数据汇总的做法,转而考察组内每一个国家的人口密度(以高收入国家为例),就可以得到表5。
表5高收入国家的组内人口密度与平均人口密度

从表5可以看到,许多高收入国家的人口密度都超过了100,如果说新加坡是一个城市国家,人口总量比较小,那么像德国、日本、英国这几个人口超过5000万的国家,其人口密度都超过了200。造成高收入国家在整体上人口密度偏低的主要因素是澳大利亚、美国和加拿大这三个地广人稀的国家。放弃汇总数据而考察更细致的数据,就会发现人口密度这个指标在高收入国家组内的差异非常之大,因此高收入国家组内的数据同质性就人口密度这个指标来说是不存在的,汇总之后计算出来的组内人口密度实际上已经没有多大实际意义。更糟糕的是,所得到的分析结果会误导分析者得出错误结论。这个例子比较有戏剧性,它揭示了统计分析中的两个常见现象,第一是分组数据往往能够提供更加平滑更加漂亮的中间数据,第二是在组内差异非常大的情况下,计算组内均值不仅是毫无意义的问题,还会导致错误结果。分组计算的均值可能从正确的废话蜕变为错误的废话。其实,从所有国家的人均面积和人均收入的原始数据出发,可以得到更有说服力的分析结果,为什么要分组之后再处理呢?
二、几点评论
分组是一种历史上形成的做法,尤其是在计算能力不足的手工时代形成的做法。这种做法在现代的计算条件下基本上失去了历史合理性和技术合理性,在很多场合下是有害无益的。可能派上用场的应该是在海量数据的处理中。在数据处理的最前沿,计算机的发展总是追不上数据量的膨胀,现代计算机系统和统计软件能够轻松地处理中小型企业的日常交易数据,但还不能有效处理大型银行、保险公司和国家统计局面对的海量数据。所以分组方法还会有很多用途。但是统计教科书在介绍各种统计方法的时候,并没有强调方法的技术合理性和历史局限。而大部分人对统计方法的印象来自教科书,并没有时间对方法的优点和缺陷作充分了解,这是造成公众对统计方法缺乏正确理解的一个重要原因。
对于大众来说,统计数据往往具有一种表面的科学性和严密性,而把社会生活简化为一组数字也能够让社会生活变得似乎更加简单,所以分组之后的数据指标很受欢迎。但我们可以看到,经过种种处理之后的数据可能包含各种偏差,这些偏差的来源至少包括:统计方法自身的缺陷,计算能力约束造成的估算方法,由于外在的利益造成的有偏向的选择结果。就是说,对数据的数学运算几乎是任意的,但是计算结果是否有意义取决于统计方法之外的判断,而这种判断可能依据常识或者受到利益驱动,很难置身于真实世界之外。但是从上面的案例可以得到一些基本经验,帮助我们避开大多数陷阱。
第一,分组的基本依据是组内数据同质性。这个性质一般来说只能近似成立,许多场合下甚至只是研究者的个人判断。关注分组之后对于各种指标的组内同质性有助于我们避免一些错误。
第二,尽量使用原始数据而不是分组之后的数据。不过这一点在实际生活中往往难以实现,比如研究企业数据的时候,能够拿到的公开数据已经根据企业规模进行了分组处理,这样就损失了大量信息,甚至可能被误导。
第三,对分析对象和环境做更加全面的考察。两个变量在数字上的虚假相关是最容易骗人的假象。社会学发展出了许多实用模型,比如结构方程模型,比如高维列联分析,有助于我们消除混杂因素,但是利用常识判断总是不可缺少的补充手段。
第四,注意样本的代表性。样本的特征能否随意推广到总体,这是一个基本问题。对于样本列联表的数据提供的比例就更应该警惕。
分组数据导致的信息损失固然是一个缺陷,但这种缺陷会为有心人士提供操控数据和舆论的机会,毕竟大部分人没有仔细研究过分组方法以及计算能力对统计方法有何影响,这是滥用统计方法的问题,它已经超出了本文的研究范围,而统计专业人员能够做到的是说明自己的同质性假设并结合常识和分析结果判断分组方法的合理性与局限性。
参考文献:
[1]陈希孺.数理统计学简史[M].长沙:湖南教育出版社,200:147.
[2]Stephen Stigler. The History of Statistics in 1933[J]. Statistics Science, 1996,11(3):244-252.
[3]王静龙,梁小筠.定性数据分析[M].上海:华东师范大学出版社,2004:177-178.
[4]贾俊平,何晓群,金勇进.统计学(第三版)[M].北京:中国人民大学出版社,2007:266-267.
[5]高敏雪,李静萍.经济社会统计[M].北京:中国人民大学出版社.2003:25.